 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisAlgae 2023: A Dataset and Challenge for Algae Detection in Microscopy Images
May 27, 2025Microalgae, vital for ecological balance and economic sectors, present challenges in detection due to their diverse sizes and conditions. This paper summarizes the second "Vision Meets Algae" (VisAlgae 2023) Challenge, aiming to enhance high-throughput microalgae cell detection. The challenge, which attracted 369 participating teams, includes a dataset of 1000 images across six classes, featuring microalgae of varying sizes and distinct features. Participants faced tasks such as detecting small targets, handling motion blur, and complex backgrounds. The top 10 methods, outlined here, offer insights into overcoming these challenges and maximizing detection accuracy. This intersection of algae research and computer vision offers promise for ecological understanding and technological advancement. The dataset can be accessed at: https://github.com/juntaoJianggavin/Visalgae2023/.
Path and Bone-Contour Regularized Unpaired MRI-to-CT Translation
May 06, 2025



Accurate MRI-to-CT translation promises the integration of complementary imaging information without the need for additional imaging sessions. Given the practical challenges associated with acquiring paired MRI and CT scans, the development of robust methods capable of leveraging unpaired datasets is essential for advancing the MRI-to-CT translation. Current unpaired MRI-to-CT translation methods, which predominantly rely on cycle consistency and contrastive learning frameworks, frequently encounter challenges in accurately translating anatomical features that are highly discernible on CT but less distinguishable on MRI, such as bone structures. This limitation renders these approaches less suitable for applications in radiation therapy, where precise bone representation is essential for accurate treatment planning. To address this challenge, we propose a path- and bone-contour regularized approach for unpaired MRI-to-CT translation. In our method, MRI and CT images are projected to a shared latent space, where the MRI-to-CT mapping is modeled as a continuous flow governed by neural ordinary differential equations. The optimal mapping is obtained by minimizing the transition path length of the flow. To enhance the accuracy of translated bone structures, we introduce a trainable neural network to generate bone contours from MRI and implement mechanisms to directly and indirectly encourage the model to focus on bone contours and their adjacent regions. Evaluations conducted on three datasets demonstrate that our method outperforms existing unpaired MRI-to-CT translation approaches, achieving lower overall error rates. Moreover, in a downstream bone segmentation task, our approach exhibits superior performance in preserving the fidelity of bone structures. Our code is available at: https://github.com/kennysyp/PaBoT.
PanoLlama: Generating Endless and Coherent Panoramas with Next-Token-Prediction LLMs
Nov 24, 2024



Panoramic Image Generation has emerged as an important task in image generation, driven by growing demands for large-scale visuals in creative and technical applications. While diffusion models have dominated this field, they face inherent limitations, including the multilevel-coherence challenge and implementation complexity, leading to suboptimal outcomes. In this paper, we introduce PanoLlama, a novel framework that redefines panoramic image generation as a next-token prediction task. Building on the pre-trained LlamaGen architecture, we generate images in an autoregressive manner and develop an expansion strategy to handle size limitations. This method aligns with the image token structure in a crop-wise and training-free manner, resulting in high-quality panoramas with minimal seams and maximum scalability. PanoLlama demonstrates its effectiveness and versatility in our experiments, achieving the best overall performance while offering flexibility for multi-scale, multi-layout, and multi-guidance generation. It overcomes the challenges that diffusion-based methods fail to address, setting a new paradigm for panoramic image generation tasks. Code is available at https://github.com/0606zt/PanoLlama.
Multi-Scale Diffusion: Enhancing Spatial Layout in High-Resolution Panoramic Image Generation
Oct 24, 2024
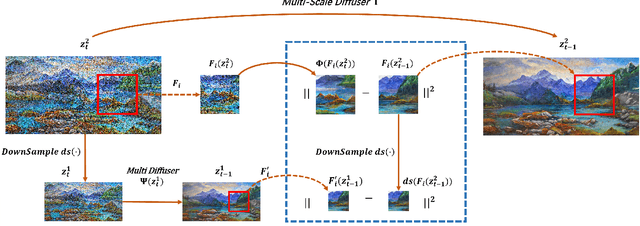

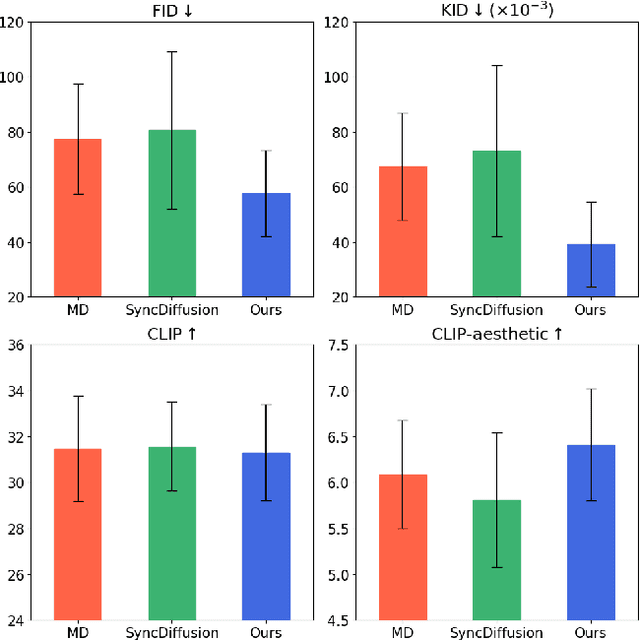
Diffusion models have recently gained recognition for generating diverse and high-quality content, especially in the domain of image synthesis. These models excel not only in creating fixed-size images but also in producing panoramic images. However, existing methods often struggle with spatial layout consistency when producing high-resolution panoramas, due to the lack of guidance of the global image layout. In this paper, we introduce the Multi-Scale Diffusion (MSD) framework, a plug-and-play module that extends the existing panoramic image generation framework to multiple resolution levels. By utilizing gradient descent techniques, our method effectively incorporates structural information from low-resolution images into high-resolution outputs. A comprehensive evaluation of the proposed method was conducted, comparing it with the prior works in qualitative and quantitative dimensions. The evaluation results demonstrate that our method significantly outperforms others in generating coherent high-resolution panoramas.
TwinDiffusion: Enhancing Coherence and Efficiency in Panoramic Image Generation with Diffusion Models
Apr 30, 2024Diffusion models have emerged as effective tools for generating diverse and high-quality content. However, their capability in high-resolution image generation, particularly for panoramic images, still faces challenges such as visible seams and incoherent transitions. In this paper, we propose TwinDiffusion, an optimized framework designed to address these challenges through two key innovations: Crop Fusion for quality enhancement and Cross Sampling for efficiency optimization. We introduce a training-free optimizing stage to refine the similarity of the adjacent image areas, as well as an interleaving sampling strategy to yield dynamic patches during the cropping process. A comprehensive evaluation is conducted to compare TwinDiffusion with the existing methods, considering factors including coherence, fidelity, compatibility, and efficiency. The results demonstrate the superior performance of our approach in generating seamless and coherent panoramas, setting a new standard in quality and efficiency for panoramic image generation.
SketchBodyNet: A Sketch-Driven Multi-faceted Decoder Network for 3D Human Reconstruction
Oct 10, 2023



Reconstructing 3D human shapes from 2D images has received increasing attention recently due to its fundamental support for many high-level 3D applications. Compared with natural images, freehand sketches are much more flexible to depict various shapes, providing a high potential and valuable way for 3D human reconstruction. However, such a task is highly challenging. The sparse abstract characteristics of sketches add severe difficulties, such as arbitrariness, inaccuracy, and lacking image details, to the already badly ill-posed problem of 2D-to-3D reconstruction. Although current methods have achieved great success in reconstructing 3D human bodies from a single-view image, they do not work well on freehand sketches. In this paper, we propose a novel sketch-driven multi-faceted decoder network termed SketchBodyNet to address this task. Specifically, the network consists of a backbone and three separate attention decoder branches, where a multi-head self-attention module is exploited in each decoder to obtain enhanced features, followed by a multi-layer perceptron. The multi-faceted decoders aim to predict the camera, shape, and pose parameters, respectively, which are then associated with the SMPL model to reconstruct the corresponding 3D human mesh. In learning, existing 3D meshes are projected via the camera parameters into 2D synthetic sketches with joints, which are combined with the freehand sketches to optimize the model. To verify our method, we collect a large-scale dataset of about 26k freehand sketches and their corresponding 3D meshes containing various poses of human bodies from 14 different angles. Extensive experimental results demonstrate our SketchBodyNet achieves superior performance in reconstructing 3D human meshes from freehand sketches.
CNN in CT Image Segmentation: Beyound Loss Function for Expoliting Ground Truth Images
Apr 08, 2020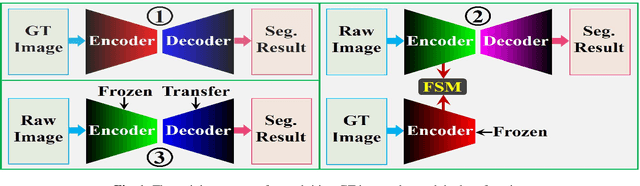

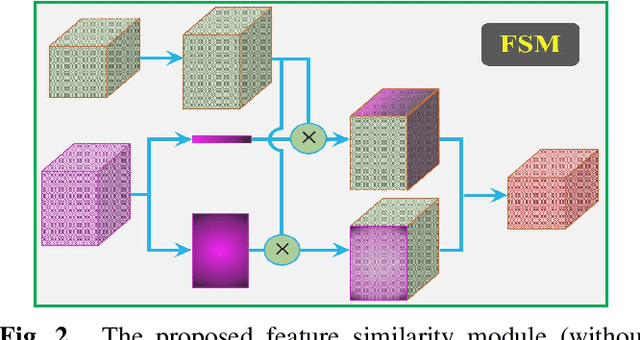
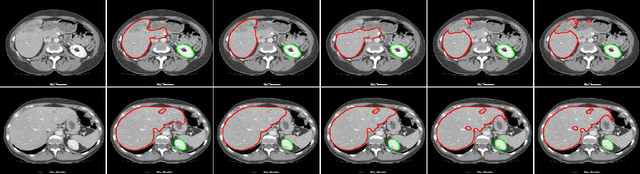
Exploiting more information from ground truth (GT) images now is a new research direction for further improving CNN's performance in CT image segmentation. Previous methods focus on devising the loss function for fulfilling such a purpose. However, it is rather difficult to devise a general and optimization-friendly loss function. We here present a novel and practical method that exploits GT images beyond the loss function. Our insight is that feature maps of two CNNs trained respectively on GT and CT images should be similar on some metric space, because they both are used to describe the same objects for the same purpose. We hence exploit GT images by enforcing such two CNNs' feature maps to be consistent. We assess the proposed method on two data sets, and compare its performance to several competitive methods. Extensive experimental results show that the proposed method is effective, outperforming all the compared methods.