 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketchBodyNet: A Sketch-Driven Multi-faceted Decoder Network for 3D Human Reconstruction
Oct 10, 2023



Reconstructing 3D human shapes from 2D images has received increasing attention recently due to its fundamental support for many high-level 3D applications. Compared with natural images, freehand sketches are much more flexible to depict various shapes, providing a high potential and valuable way for 3D human reconstruction. However, such a task is highly challenging. The sparse abstract characteristics of sketches add severe difficulties, such as arbitrariness, inaccuracy, and lacking image details, to the already badly ill-posed problem of 2D-to-3D reconstruction. Although current methods have achieved great success in reconstructing 3D human bodies from a single-view image, they do not work well on freehand sketches. In this paper, we propose a novel sketch-driven multi-faceted decoder network termed SketchBodyNet to address this task. Specifically, the network consists of a backbone and three separate attention decoder branches, where a multi-head self-attention module is exploited in each decoder to obtain enhanced features, followed by a multi-layer perceptron. The multi-faceted decoders aim to predict the camera, shape, and pose parameters, respectively, which are then associated with the SMPL model to reconstruct the corresponding 3D human mesh. In learning, existing 3D meshes are projected via the camera parameters into 2D synthetic sketches with joints, which are combined with the freehand sketches to optimize the model. To verify our method, we collect a large-scale dataset of about 26k freehand sketches and their corresponding 3D meshes containing various poses of human bodies from 14 different angles. Extensive experimental results demonstrate our SketchBodyNet achieves superior performance in reconstructing 3D human meshes from freehand sketches.
A Voice Disease Detection Method Based on MFCCs and Shallow CNN
Apr 18, 2023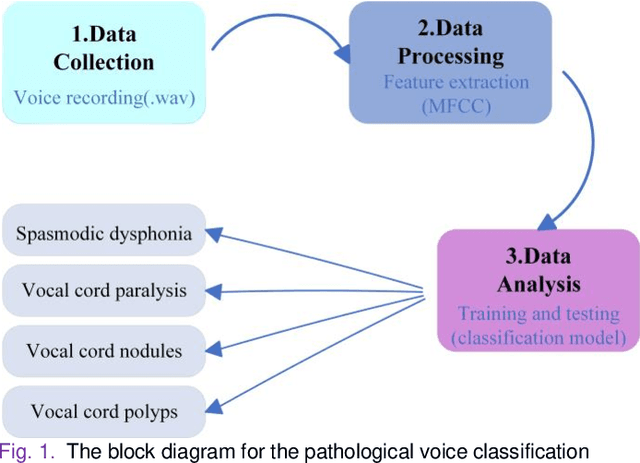
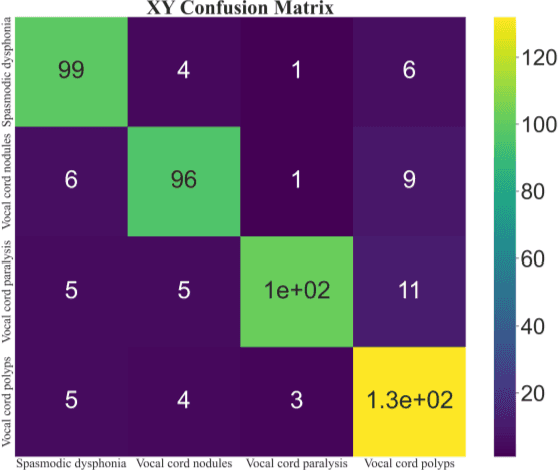
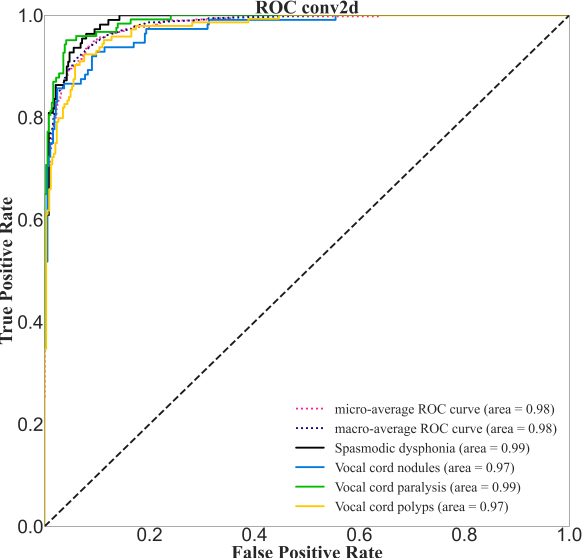
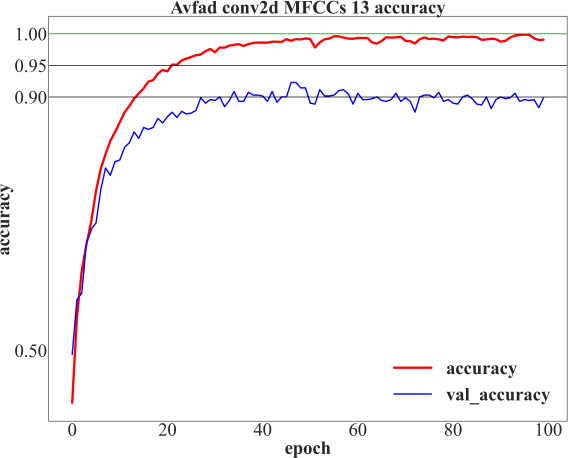
The incidence rate of voice diseases is increasing year by year. The use of software for remote diagnosis is a technical development trend and has important practical value. Among voice diseases, common diseases that cause hoarseness include spasmodic dysphonia, vocal cord paralysis, vocal nodule, and vocal cord polyp. This paper presents a voice disease detection method that can be applied in a wide range of clinical. We cooperated with Xiangya Hospital of Central South University to collect voice samples from sixty-one different patients. The Mel Frequency Cepstrum Coefficient (MFCC) parameters are extracted as input features to describe the voice in the form of data. An innovative model combining MFCC parameters and single convolution layer CNN is proposed for fast calculation and classification. The highest accuracy we achieved was 92%, it is fully ahead of the original research results and internationally advanced. And we use Advanced Voice Function Assessment Databases (AVFAD) to evaluate the generalization ability of the method we proposed, which achieved an accuracy rate of 98%. Experiments on clinical and standard datasets show that for the pathological detection of voice diseases, our method has greatly improved in accuracy and computational efficiency.
CrowdMLP: Weakly-Supervised Crowd Counting via Multi-Granularity MLP
Mar 15, 2022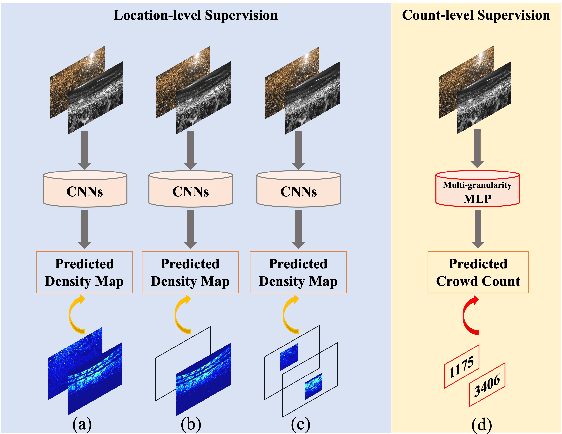
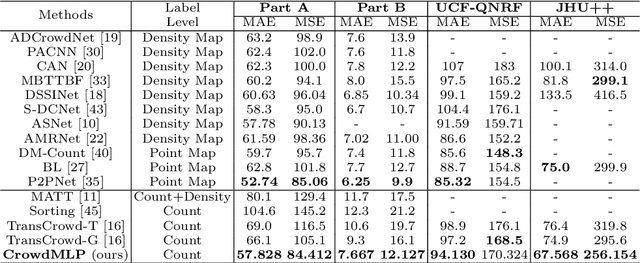
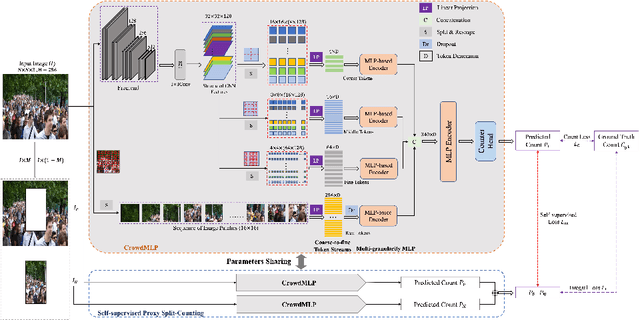

Existing state-of-the-art crowd counting algorithms rely excessively on location-level annotations, which are burdensome to acquire. When only count-level (weak) supervisory signals are available, it is arduous and error-prone to regress total counts due to the lack of explicit spatial constraints. To address this issue, a novel and efficient counter (referred to as CrowdMLP) is presented, which probes into modelling global dependencies of embeddings and regressing total counts by devising a multi-granularity MLP regressor. In specific, a locally-focused pre-trained frontend is cascaded to extract crude feature maps with intrinsic spatial cues, which prevent the model from collapsing into trivial outcomes. The crude embeddings, along with raw crowd scenes, are tokenized at different granularity levels. The multi-granularity MLP then proceeds to mix tokens at the dimensions of cardinality, channel, and spatial for mining global information. An effective proxy task, namely Split-Counting, is also proposed to evade the barrier of limited samples and the shortage of spatial hints in a self-supervised manner. Extensive experiments demonstrate that CrowdMLP significantly outperforms existing weakly-supervised counting algorithms and performs on par with state-of-the-art location-level supervised approaches.
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
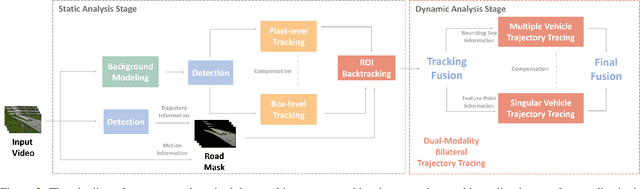
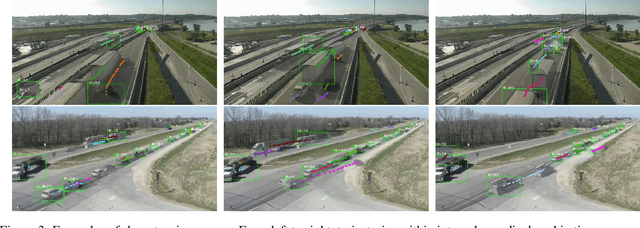
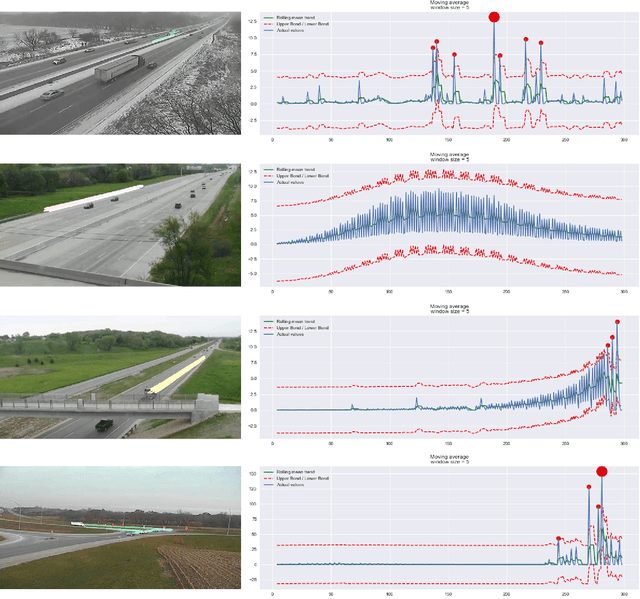
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.
STNet: Scale Tree Network with Multi-level Auxiliator for Crowd Counting
Dec 18, 2020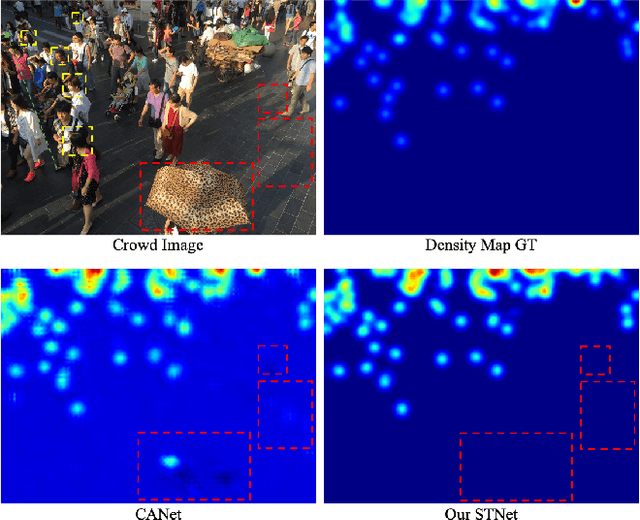
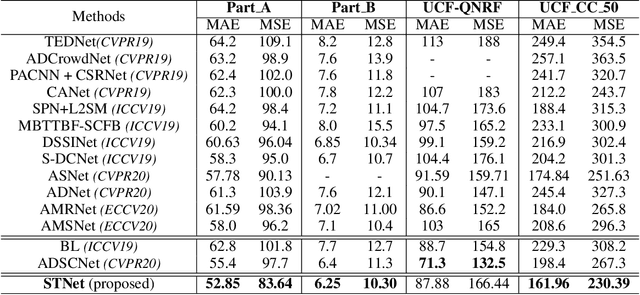


Crowd counting remains a challenging task because the presence of drastic scale variation, density inconsistency, and complex background can seriously degrade the counting accuracy. To battle the ingrained issue of accuracy degradation, we propose a novel and powerful network called Scale Tree Network (STNet) for accurate crowd counting. STNet consists of two key components: a Scale-Tree Diversity Enhancer and a Semi-supervised Multi-level Auxiliator. Specifically, the Diversity Enhancer is designed to enrich scale diversity, which alleviates limitations of existing methods caused by insufficient level of scales. A novel tree structure is adopted to hierarchically parse coarse-to-fine crowd regions. Furthermore, a simple yet effective Multi-level Auxiliator is presented to aid in exploiting generalisable shared characteristics at multiple levels, allowing more accurate pixel-wise background cognition. The overall STNet is trained in an end-to-end manner, without the needs for manually tuning loss weights between the main and the auxiliary tasks. Extensive experiments on four challenging crowd datasets demonstrate the superiority of the proposed method.
Interlayer and Intralayer Scale Aggregation for Scale-invariant Crowd Counting
May 25, 2020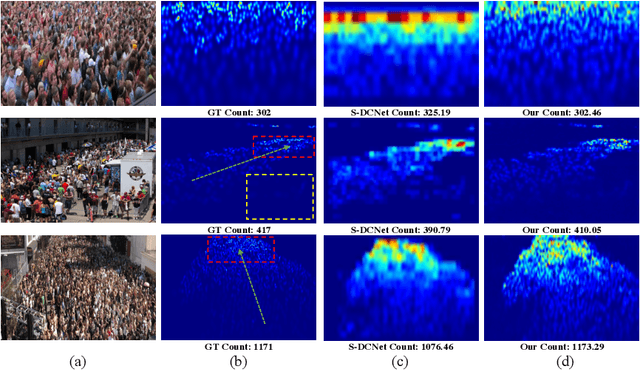
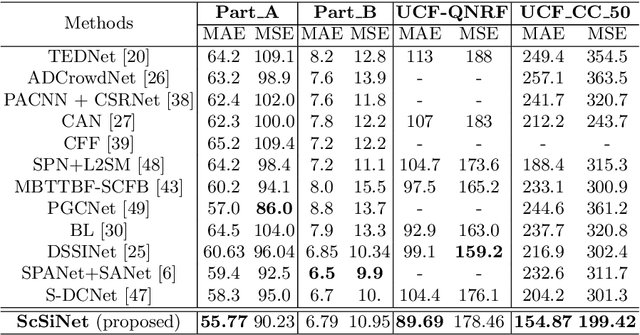
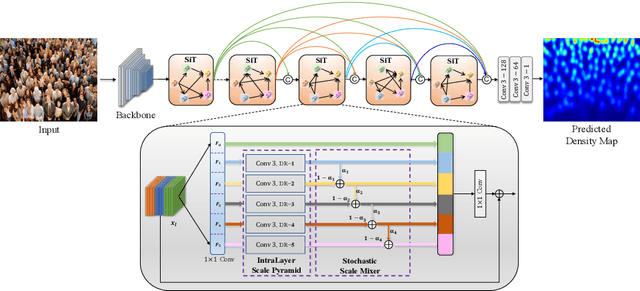

Crowd counting is an important vision task, which faces challenges on continuous scale variation within a given scene and huge density shift both within and across images. These challenges are typically addressed using multi-column structures in existing methods. However, such an approach does not provide consistent improvement and transferability due to limited ability in capturing multi-scale features, sensitiveness to large density shift, and difficulty in training multi-branch models. To overcome these limitations, a Single-column Scale-invariant Network (ScSiNet) is presented in this paper, which extracts sophisticated scale-invariant features via the combination of interlayer multi-scale integration and a novel intralayer scale-invariant transformation (SiT). Furthermore, in order to enlarge the diversity of densities, a randomly integrated loss is presented for training our single-branch method. Extensive experiments on public datasets demonstrate that the proposed method consistently outperforms state-of-the-art approaches in counting accuracy and achieves remarkable transferability and scale-invariant property.