 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
TalkToAgent: A Human-centric Explanation of Reinforcement Learning Agents with Large Language Models
Sep 05, 2025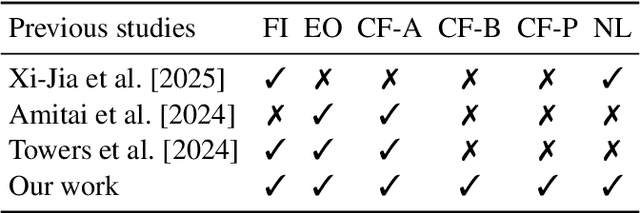



Explainable Reinforcement Learning (XRL) has emerged as a promising approach in improving the transparency of Reinforcement Learning (RL) agents. However, there remains a gap between complex RL policies and domain experts, due to the limited comprehensibility of XRL results and isolated coverage of current XRL approaches that leave users uncertain about which tools to employ. To address these challenges, we introduce TalkToAgent, a multi-agent Large Language Models (LLM) framework that delivers interactive, natural language explanations for RL policies. The architecture with five specialized LLM agents (Coordinator, Explainer, Coder, Evaluator, and Debugger) enables TalkToAgent to automatically map user queries to relevant XRL tools and clarify an agent's actions in terms of either key state variables, expected outcomes, or counterfactual explanations. Moreover, our approach extends previous counterfactual explanations by deriving alternative scenarios from qualitative behavioral descriptions, or even new rule-based policies. We validated TalkToAgent on quadruple-tank process control problem, a well-known nonlinear control benchmark. Results demonstrated that TalkToAgent successfully mapped user queries into XRL tasks with high accuracy, and coder-debugger interactions minimized failures in counterfactual generation. Furthermore, qualitative evaluation confirmed that TalkToAgent effectively interpreted agent's actions and contextualized their meaning within the problem domain.
Trustworthy Tree-based Machine Learning by $MoS_2$ Flash-based Analog CAM with Inherent Soft Boundaries
Jul 16, 2025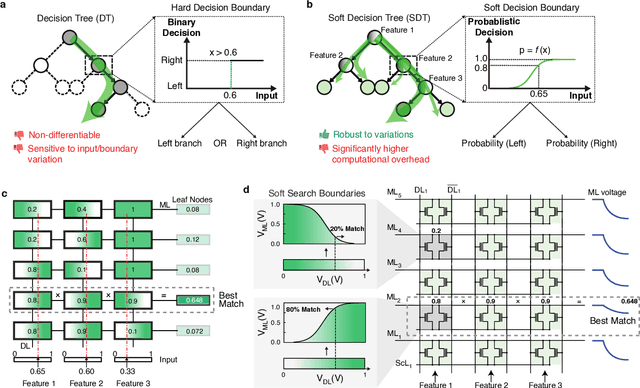
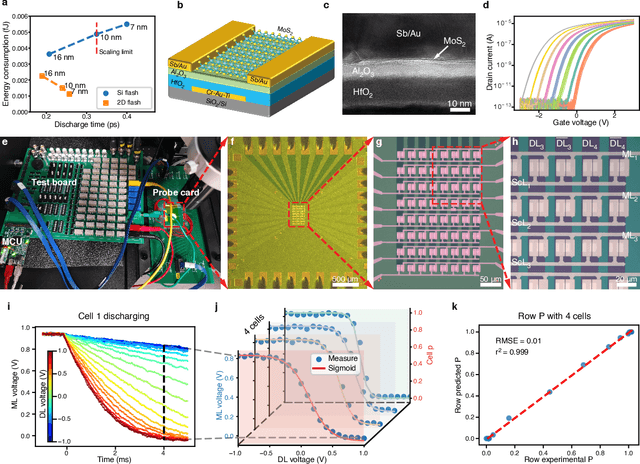
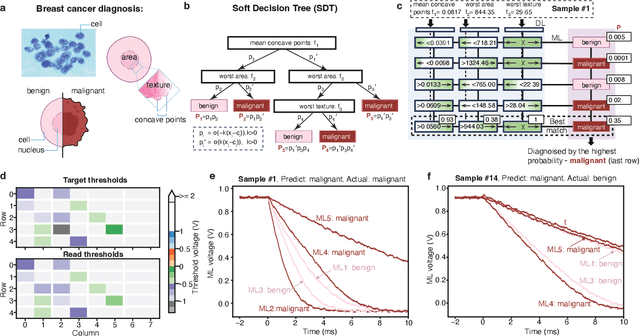
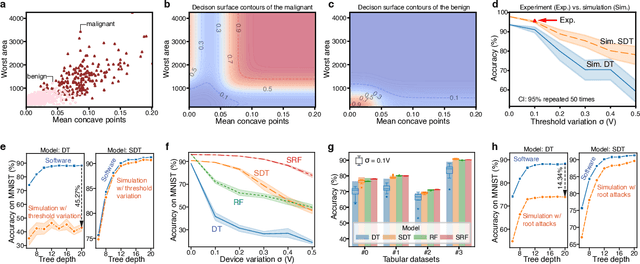
The rapid advancement of artificial intelligence has raised concerns regarding its trustworthiness, especially in terms of interpretability and robustness. Tree-based models like Random Forest and XGBoost excel in interpretability and accuracy for tabular data, but scaling them remains computationally expensive due to poor data locality and high data dependence. Previous efforts to accelerate these models with analog content addressable memory (CAM) have struggled, due to the fact that the difficult-to-implement sharp decision boundaries are highly susceptible to device variations, which leads to poor hardware performance and vulnerability to adversarial attacks. This work presents a novel hardware-software co-design approach using $MoS_2$ Flash-based analog CAM with inherent soft boundaries, enabling efficient inference with soft tree-based models. Our soft tree model inference experiments on $MoS_2$ analog CAM arrays show this method achieves exceptional robustness against device variation and adversarial attacks while achieving state-of-the-art accuracy. Specifically, our fabricated analog CAM arrays achieve $96\%$ accuracy on Wisconsin Diagnostic Breast Cancer (WDBC) database, while maintaining decision explainability. Our experimentally calibrated model validated only a $0.6\%$ accuracy drop on the MNIST dataset under $10\%$ device threshold variation, compared to a $45.3\%$ drop for traditional decision trees. This work paves the way for specialized hardware that enhances AI's trustworthiness and efficiency.
VisioMath: Benchmarking Figure-based Mathematical Reasoning in LMMs
Jun 07, 2025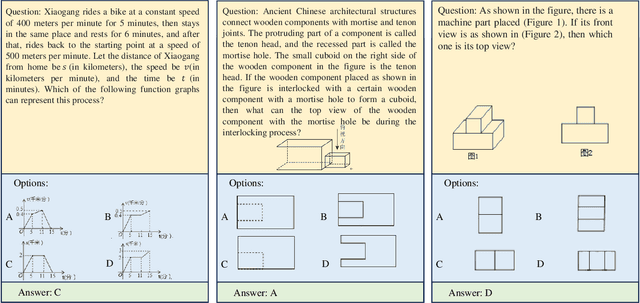
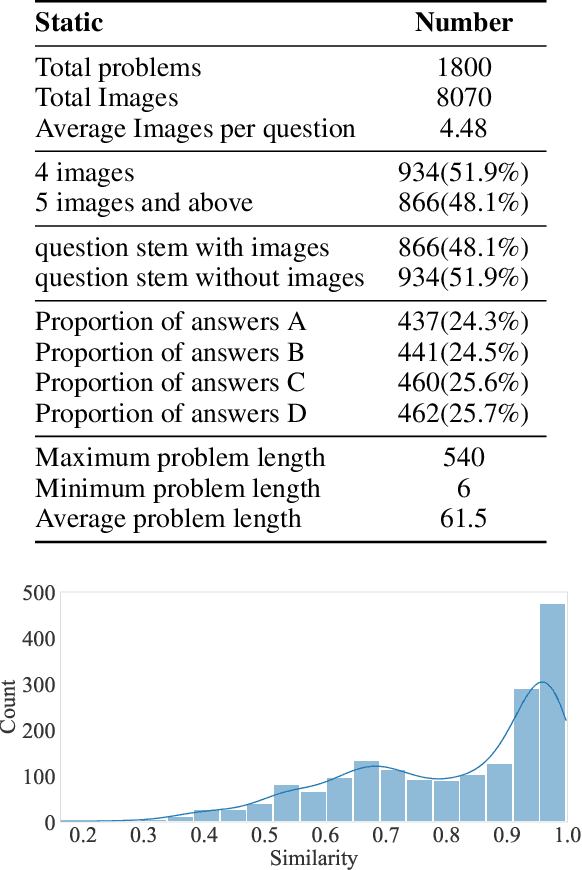
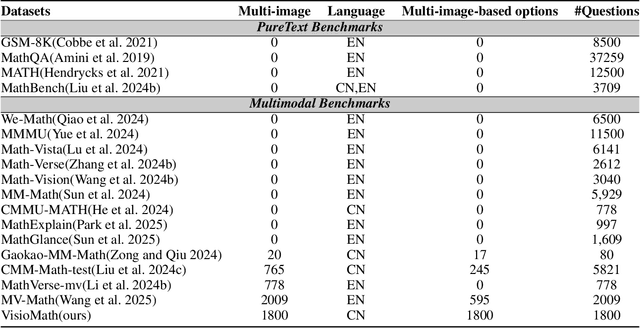
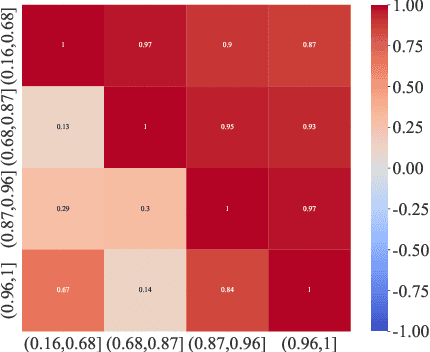
Large Multimodal Models (LMMs) have demonstrated remarkable problem-solving capabilities across various domains. However, their ability to perform mathematical reasoning when answer options are represented as images--an essential aspect of multi-image comprehension--remains underexplored. To bridge this gap, we introduce VisioMath, a benchmark designed to evaluate mathematical reasoning in multimodal contexts involving image-based answer choices. VisioMath comprises 8,070 images and 1,800 multiple-choice questions, where each answer option is an image, presenting unique challenges to existing LMMs. To the best of our knowledge, VisioMath is the first dataset specifically tailored for mathematical reasoning in image-based-option scenarios, where fine-grained distinctions between answer choices are critical for accurate problem-solving. We systematically evaluate state-of-the-art LMMs on VisioMath and find that even the most advanced models struggle with this task. Notably, GPT-4o achieves only 45.9% accuracy, underscoring the limitations of current models in reasoning over visually similar answer choices. By addressing a crucial gap in existing benchmarks, VisioMath establishes a rigorous testbed for future research, driving advancements in multimodal reasoning.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
Enforcing Hard Linear Constraints in Deep Learning Models with Decision Rules
May 20, 2025


Deep learning models are increasingly deployed in safety-critical tasks where predictions must satisfy hard constraints, such as physical laws, fairness requirements, or safety limits. However, standard architectures lack built-in mechanisms to enforce such constraints, and existing approaches based on regularization or projection are often limited to simple constraints, computationally expensive, or lack feasibility guarantees. This paper proposes a model-agnostic framework for enforcing input-dependent linear equality and inequality constraints on neural network outputs. The architecture combines a task network trained for prediction accuracy with a safe network trained using decision rules from the stochastic and robust optimization literature to ensure feasibility across the entire input space. The final prediction is a convex combination of the two subnetworks, guaranteeing constraint satisfaction during both training and inference without iterative procedures or runtime optimization. We prove that the architecture is a universal approximator of constrained functions and derive computationally tractable formulations based on linear decision rules. Empirical results on benchmark regression tasks show that our method consistently satisfies constraints while maintaining competitive accuracy and low inference latency.
Hardware-Adaptive and Superlinear-Capacity Memristor-based Associative Memory
May 19, 2025Brain-inspired computing aims to mimic cognitive functions like associative memory, the ability to recall complete patterns from partial cues. Memristor technology offers promising hardware for such neuromorphic systems due to its potential for efficient in-memory analog computing. Hopfield Neural Networks (HNNs) are a classic model for associative memory, but implementations on conventional hardware suffer from efficiency bottlenecks, while prior memristor-based HNNs faced challenges with vulnerability to hardware defects due to offline training, limited storage capacity, and difficulty processing analog patterns. Here we introduce and experimentally demonstrate on integrated memristor hardware a new hardware-adaptive learning algorithm for associative memories that significantly improves defect tolerance and capacity, and naturally extends to scalable multilayer architectures capable of handling both binary and continuous patterns. Our approach achieves 3x effective capacity under 50% device faults compared to state-of-the-art methods. Furthermore, its extension to multilayer architectures enables superlinear capacity scaling (\(\propto N^{1.49}\ for binary patterns) and effective recalling of continuous patterns (\propto N^{1.74}\ scaling), as compared to linear capacity scaling for previous HNNs. It also provides flexibility to adjust capacity by tuning hidden neurons for the same-sized patterns. By leveraging the massive parallelism of the hardware enabled by synchronous updates, it reduces energy by 8.8x and latency by 99.7% for 64-dimensional patterns over asynchronous schemes, with greater improvements at scale. This promises the development of more reliable memristor-based associative memory systems and enables new applications research due to the significantly improved capacity, efficiency, and flexibility.
TimeKAN: KAN-based Frequency Decomposition Learning Architecture for Long-term Time Series Forecasting
Feb 10, 2025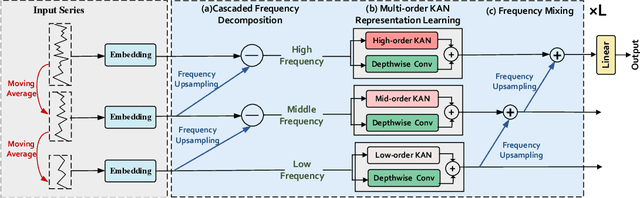



Real-world time series often have multiple frequency components that are intertwined with each other, making accurate time series forecasting challenging. Decomposing the mixed frequency components into multiple single frequency components is a natural choice. However, the information density of patterns varies across different frequencies, and employing a uniform modeling approach for different frequency components can lead to inaccurate characterization. To address this challenges, inspired by the flexibility of the recent Kolmogorov-Arnold Network (KAN), we propose a KAN-based Frequency Decomposition Learning architecture (TimeKAN) to address the complex forecasting challenges caused by multiple frequency mixtures. Specifically, TimeKAN mainly consists of three components: Cascaded Frequency Decomposition (CFD) blocks, Multi-order KAN Representation Learning (M-KAN) blocks and Frequency Mixing blocks. CFD blocks adopt a bottom-up cascading approach to obtain series representations for each frequency band. Benefiting from the high flexibility of KAN, we design a novel M-KAN block to learn and represent specific temporal patterns within each frequency band. Finally, Frequency Mixing blocks is used to recombine the frequency bands into the original format. Extensive experimental results across multiple real-world time series datasets demonstrate that TimeKAN achieves state-of-the-art performance as an extremely lightweight architecture. Code is available at https://github.com/huangst21/TimeKAN.
OptiChat: Bridging Optimization Models and Practitioners with Large Language Models
Jan 14, 2025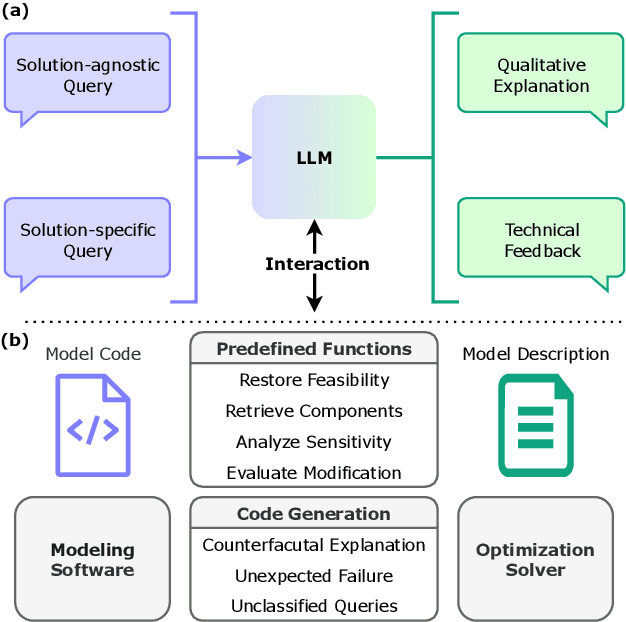


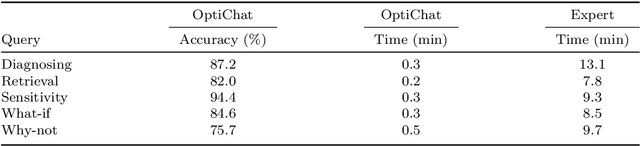
Optimization models have been applied to solve a wide variety of decision-making problems. These models are usually developed by optimization experts but are used by practitioners without optimization expertise in various application domains. As a result, practitioners often struggle to interact with and draw useful conclusions from optimization models independently. To fill this gap, we introduce OptiChat, a natural language dialogue system designed to help practitioners interpret model formulation, diagnose infeasibility, analyze sensitivity, retrieve information, evaluate modifications, and provide counterfactual explanations. By augmenting large language models (LLMs) with functional calls and code generation tailored for optimization models, we enable seamless interaction and minimize the risk of hallucinations in OptiChat. We develop a new dataset to evaluate OptiChat's performance in explaining optimization models. Experiments demonstrate that OptiChat effectively bridges the gap between optimization models and practitioners, delivering autonomous, accurate, and instant responses.
FaultExplainer: Leveraging Large Language Models for Interpretable Fault Detection and Diagnosis
Dec 19, 2024Machine learning algorithms are increasingly being applied to fault detection and diagnosis (FDD) in chemical processes. However, existing data-driven FDD platforms often lack interpretability for process operators and struggle to identify root causes of previously unseen faults. This paper presents FaultExplainer, an interactive tool designed to improve fault detection, diagnosis, and explanation in the Tennessee Eastman Process (TEP). FaultExplainer integrates real-time sensor data visualization, Principal Component Analysis (PCA)-based fault detection, and identification of top contributing variables within an interactive user interface powered by large language models (LLMs). We evaluate the LLMs' reasoning capabilities in two scenarios: one where historical root causes are provided, and one where they are not to mimic the challenge of previously unseen faults. Experimental results using GPT-4o and o1-preview models demonstrate the system's strengths in generating plausible and actionable explanations, while also highlighting its limitations, including reliance on PCA-selected features and occasional hallucinations.