 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMCTOP: A Multimodal Textualization and Mixture-of-Experts Framework for Clinical Trial Outcome Prediction
Dec 26, 2025Addressing the challenge of multimodal data fusion in high-dimensional biomedical informatics, we propose MMCTOP, a MultiModal Clinical-Trial Outcome Prediction framework that integrates heterogeneous biomedical signals spanning (i) molecular structure representations, (ii) protocol metadata and long-form eligibility narratives, and (iii) disease ontologies. MMCTOP couples schema-guided textualization and input-fidelity validation with modality-aware representation learning, in which domain-specific encoders generate aligned embeddings that are fused by a transformer backbone augmented with a drug-disease-conditioned sparse Mixture-of-Experts (SMoE). This design explicitly supports specialization across therapeutic and design subspaces while maintaining scalable computation through top-k routing. MMCTOP achieves consistent improvements in precision, F1, and AUC over unimodal and multimodal baselines on benchmark datasets, and ablations show that schema-guided textualization and selective expert routing contribute materially to performance and stability. We additionally apply temperature scaling to obtain calibrated probabilities, ensuring reliable risk estimation for downstream decision support. Overall, MMCTOP advances multimodal trial modeling by combining controlled narrative normalization, context-conditioned expert fusion, and operational safeguards aimed at auditability and reproducibility in biomedical informatics.
The Missing Reward: Active Inference in the Era of Experience
Aug 07, 2025
This paper argues that Active Inference (AIF) provides a crucial foundation for developing autonomous AI agents capable of learning from experience without continuous human reward engineering. As AI systems begin to exhaust high-quality training data and rely on increasingly large human workforces for reward design, the current paradigm faces significant scalability challenges that could impede progress toward genuinely autonomous intelligence. The proposal for an ``Era of Experience,'' where agents learn from self-generated data, is a promising step forward. However, this vision still depends on extensive human engineering of reward functions, effectively shifting the bottleneck from data curation to reward curation. This highlights what we identify as the \textbf{grounded-agency gap}: the inability of contemporary AI systems to autonomously formulate, adapt, and pursue objectives in response to changing circumstances. We propose that AIF can bridge this gap by replacing external reward signals with an intrinsic drive to minimize free energy, allowing agents to naturally balance exploration and exploitation through a unified Bayesian objective. By integrating Large Language Models as generative world models with AIF's principled decision-making framework, we can create agents that learn efficiently from experience while remaining aligned with human values. This synthesis offers a compelling path toward AI systems that can develop autonomously while adhering to both computational and physical constraints.
SmallThinker: A Family of Efficient Large Language Models Natively Trained for Local Deployment
Jul 28, 2025While frontier large language models (LLMs) continue to push capability boundaries, their deployment remains confined to GPU-powered cloud infrastructure. We challenge this paradigm with SmallThinker, a family of LLMs natively designed - not adapted - for the unique constraints of local devices: weak computational power, limited memory, and slow storage. Unlike traditional approaches that mainly compress existing models built for clouds, we architect SmallThinker from the ground up to thrive within these limitations. Our innovation lies in a deployment-aware architecture that transforms constraints into design principles. First, We introduce a two-level sparse structure combining fine-grained Mixture-of-Experts (MoE) with sparse feed-forward networks, drastically reducing computational demands without sacrificing model capacity. Second, to conquer the I/O bottleneck of slow storage, we design a pre-attention router that enables our co-designed inference engine to prefetch expert parameters from storage while computing attention, effectively hiding storage latency that would otherwise cripple on-device inference. Third, for memory efficiency, we utilize NoPE-RoPE hybrid sparse attention mechanism to slash KV cache requirements. We release SmallThinker-4B-A0.6B and SmallThinker-21B-A3B, which achieve state-of-the-art performance scores and even outperform larger LLMs. Remarkably, our co-designed system mostly eliminates the need for expensive GPU hardware: with Q4_0 quantization, both models exceed 20 tokens/s on ordinary consumer CPUs, while consuming only 1GB and 8GB of memory respectively. SmallThinker is publicly available at hf.co/PowerInfer/SmallThinker-4BA0.6B-Instruct and hf.co/PowerInfer/SmallThinker-21BA3B-Instruct.
Trustworthy Tree-based Machine Learning by $MoS_2$ Flash-based Analog CAM with Inherent Soft Boundaries
Jul 16, 2025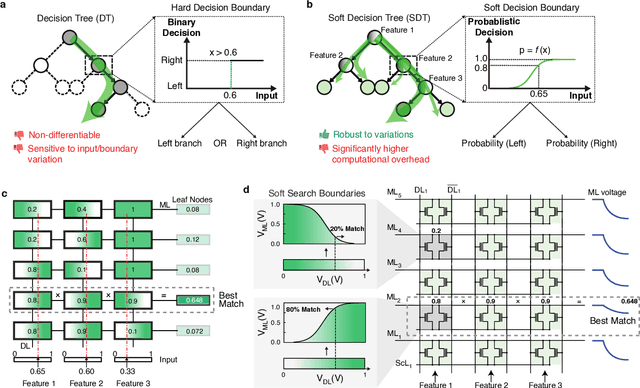
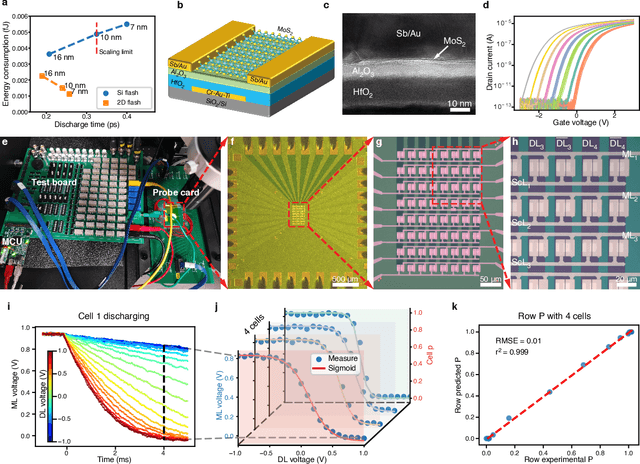
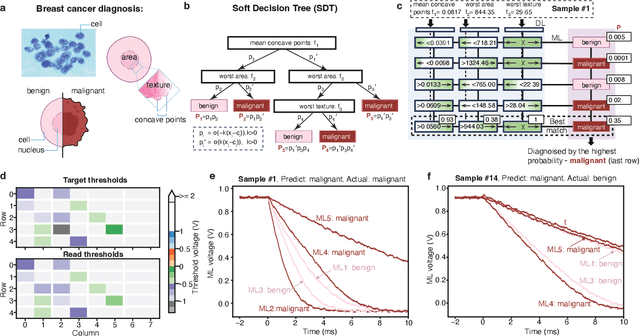
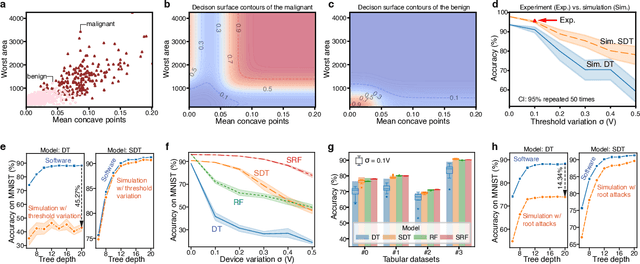
The rapid advancement of artificial intelligence has raised concerns regarding its trustworthiness, especially in terms of interpretability and robustness. Tree-based models like Random Forest and XGBoost excel in interpretability and accuracy for tabular data, but scaling them remains computationally expensive due to poor data locality and high data dependence. Previous efforts to accelerate these models with analog content addressable memory (CAM) have struggled, due to the fact that the difficult-to-implement sharp decision boundaries are highly susceptible to device variations, which leads to poor hardware performance and vulnerability to adversarial attacks. This work presents a novel hardware-software co-design approach using $MoS_2$ Flash-based analog CAM with inherent soft boundaries, enabling efficient inference with soft tree-based models. Our soft tree model inference experiments on $MoS_2$ analog CAM arrays show this method achieves exceptional robustness against device variation and adversarial attacks while achieving state-of-the-art accuracy. Specifically, our fabricated analog CAM arrays achieve $96\%$ accuracy on Wisconsin Diagnostic Breast Cancer (WDBC) database, while maintaining decision explainability. Our experimentally calibrated model validated only a $0.6\%$ accuracy drop on the MNIST dataset under $10\%$ device threshold variation, compared to a $45.3\%$ drop for traditional decision trees. This work paves the way for specialized hardware that enhances AI's trustworthiness and efficiency.
Universal Vessel Segmentation for Multi-Modality Retinal Images
Feb 10, 2025
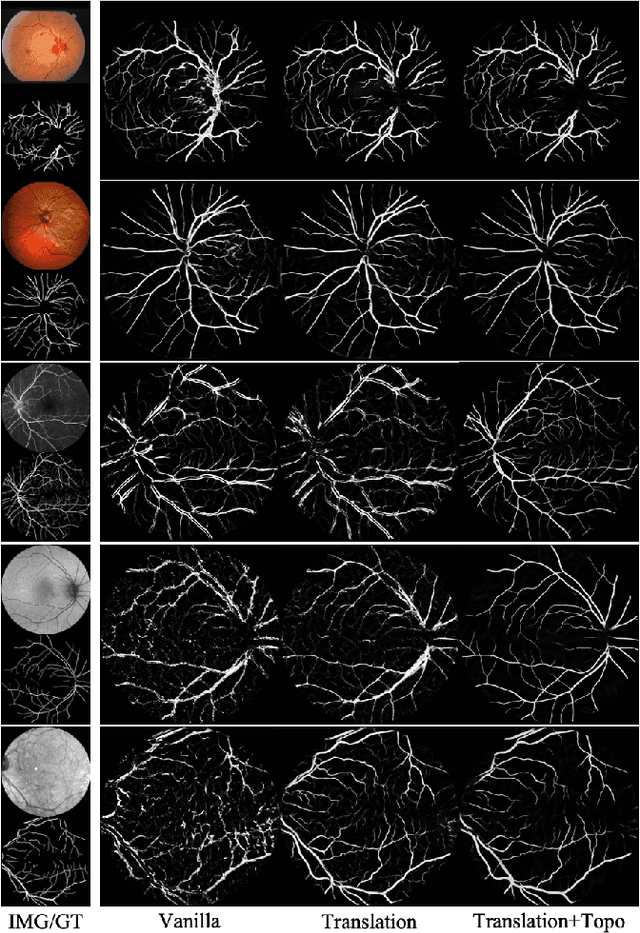
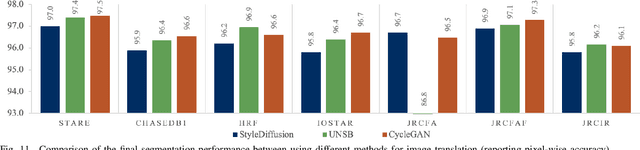
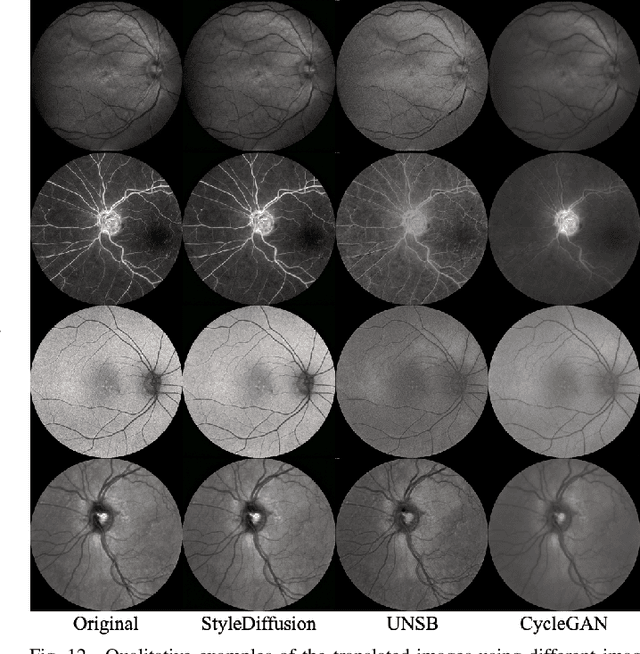
We identify two major limitations in the existing studies on retinal vessel segmentation: (1) Most existing works are restricted to one modality, i.e, the Color Fundus (CF). However, multi-modality retinal images are used every day in the study of retina and retinal diseases, and the study of vessel segmentation on the other modalities is scarce; (2) Even though a small amount of works extended their experiments to limited new modalities such as the Multi-Color Scanning Laser Ophthalmoscopy (MC), these works still require finetuning a separate model for the new modality. And the finetuning will require extra training data, which is difficult to acquire. In this work, we present a foundational universal vessel segmentation model (UVSM) for multi-modality retinal images. Not only do we perform the study on a much wider range of modalities, but also we propose a universal model to segment the vessels in all these commonly-used modalities. Despite being much more versatile comparing with existing methods, our universal model still demonstrates comparable performance with the state-of-the- art finetuned methods. To the best of our knowledge, this is the first work that achieves cross-modality retinal vessel segmentation and also the first work to study retinal vessel segmentation in some novel modalities.
Enhancing Reasoning to Adapt Large Language Models for Domain-Specific Applications
Feb 05, 2025



This paper presents SOLOMON, a novel Neuro-inspired Large Language Model (LLM) Reasoning Network architecture that enhances the adaptability of foundation models for domain-specific applications. Through a case study in semiconductor layout design, we demonstrate how SOLOMON enables swift adaptation of general-purpose LLMs to specialized tasks by leveraging Prompt Engineering and In-Context Learning techniques. Our experiments reveal the challenges LLMs face in spatial reasoning and applying domain knowledge to practical problems. Results show that SOLOMON instances significantly outperform their baseline LLM counterparts and achieve performance comparable to state-of-the-art reasoning model, o1-preview. We discuss future research directions for developing more adaptive AI systems that can continually learn, adapt, and evolve in response to new information and changing requirements.
* NeurIPS 2024 Workshop AFM (Adaptive Foundation Models: Evolving AI for Personalized and Efficient Learning)
Topology-Preserving Image Segmentation with Spatial-Aware Persistent Feature Matching
Dec 03, 2024



Topological correctness is critical for segmentation of tubular structures. Existing topological segmentation loss functions are primarily based on the persistent homology of the image. They match the persistent features from the segmentation with the persistent features from the ground truth and minimize the difference between them. However, these methods suffer from an ambiguous matching problem since the matching only relies on the information in the topological space. In this work, we propose an effective and efficient Spatial-Aware Topological Loss Function that further leverages the information in the original spatial domain of the image to assist the matching of persistent features. Extensive experiments on images of various types of tubular structures show that the proposed method has superior performance in improving the topological accuracy of the segmentation compared with state-of-the-art methods.
FeBiM: Efficient and Compact Bayesian Inference Engine Empowered with Ferroelectric In-Memory Computing
Oct 25, 2024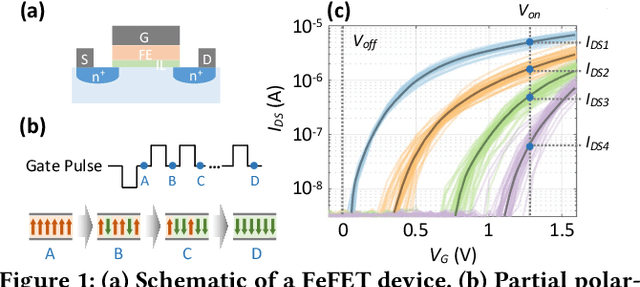
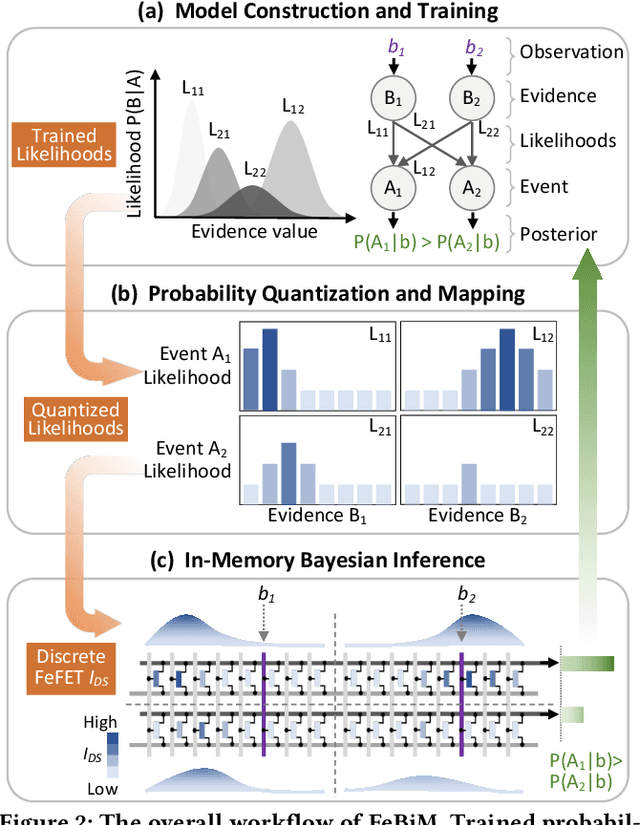
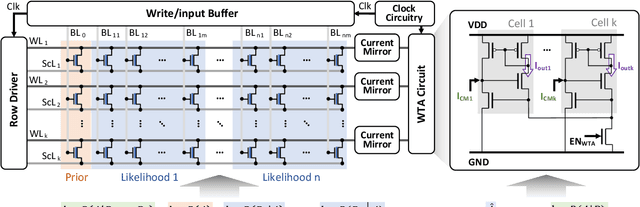
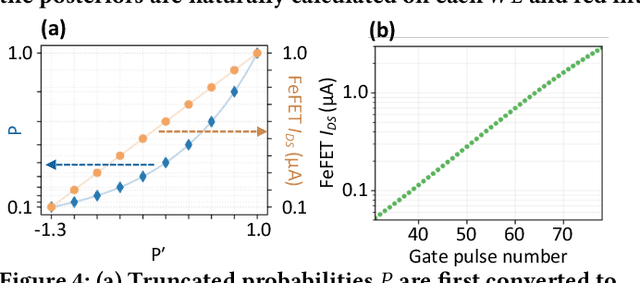
In scenarios with limited training data or where explainability is crucial, conventional neural network-based machine learning models often face challenges. In contrast, Bayesian inference-based algorithms excel in providing interpretable predictions and reliable uncertainty estimation in these scenarios. While many state-of-the-art in-memory computing (IMC) architectures leverage emerging non-volatile memory (NVM) technologies to offer unparalleled computing capacity and energy efficiency for neural network workloads, their application in Bayesian inference is limited. This is because the core operations in Bayesian inference differ significantly from the multiplication-accumulation (MAC) operations common in neural networks, rendering them generally unsuitable for direct implementation in most existing IMC designs. In this paper, we propose FeBiM, an efficient and compact Bayesian inference engine powered by multi-bit ferroelectric field-effect transistor (FeFET)-based IMC. FeBiM effectively encodes the trained probabilities of a Bayesian inference model within a compact FeFET-based crossbar. It maps quantized logarithmic probabilities to discrete FeFET states. As a result, the accumulated outputs of the crossbar naturally represent the posterior probabilities, i.e., the Bayesian inference model's output given a set of observations. This approach enables efficient in-memory Bayesian inference without the need for additional calculation circuitry. As the first FeFET-based in-memory Bayesian inference engine, FeBiM achieves an impressive storage density of 26.32 Mb/mm$^{2}$ and a computing efficiency of 581.40 TOPS/W in a representative Bayesian classification task. These results demonstrate 10.7$\times$/43.4$\times$ improvement in compactness/efficiency compared to the state-of-the-art hardware implementation of Bayesian inference.
AlcLaM: Arabic Dialectal Language Model
Jul 18, 2024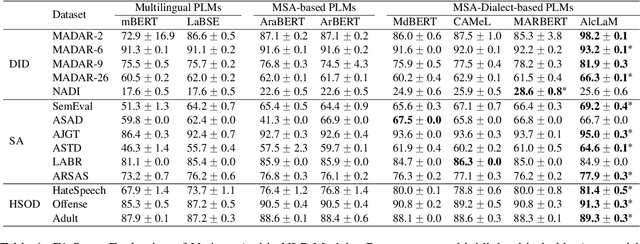
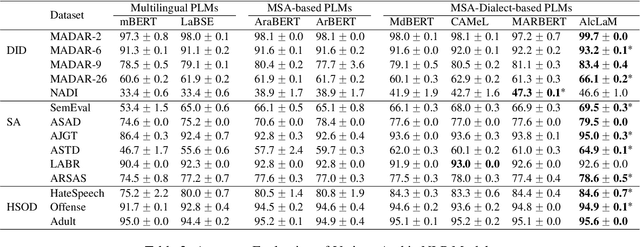
Pre-trained Language Models (PLMs) are integral to many modern natural language processing (NLP) systems. Although multilingual models cover a wide range of languages, they often grapple with challenges like high inference costs and a lack of diverse non-English training data. Arabic-specific PLMs are trained predominantly on modern standard Arabic, which compromises their performance on regional dialects. To tackle this, we construct an Arabic dialectal corpus comprising 3.4M sentences gathered from social media platforms. We utilize this corpus to expand the vocabulary and retrain a BERT-based model from scratch. Named AlcLaM, our model was trained using only 13 GB of text, which represents a fraction of the data used by existing models such as CAMeL, MARBERT, and ArBERT, compared to 7.8%, 10.2%, and 21.3%, respectively. Remarkably, AlcLaM demonstrates superior performance on a variety of Arabic NLP tasks despite the limited training data. AlcLaM is available at GitHub https://github.com/amurtadha/Alclam and HuggingFace https://huggingface.co/rahbi.
Leveraging Large Language Models for Patient Engagement: The Power of Conversational AI in Digital Health
Jun 19, 2024



The rapid advancements in large language models (LLMs) have opened up new opportunities for transforming patient engagement in healthcare through conversational AI. This paper presents an overview of the current landscape of LLMs in healthcare, specifically focusing on their applications in analyzing and generating conversations for improved patient engagement. We showcase the power of LLMs in handling unstructured conversational data through four case studies: (1) analyzing mental health discussions on Reddit, (2) developing a personalized chatbot for cognitive engagement in seniors, (3) summarizing medical conversation datasets, and (4) designing an AI-powered patient engagement system. These case studies demonstrate how LLMs can effectively extract insights and summarizations from unstructured dialogues and engage patients in guided, goal-oriented conversations. Leveraging LLMs for conversational analysis and generation opens new doors for many patient-centered outcomes research opportunities. However, integrating LLMs into healthcare raises important ethical considerations regarding data privacy, bias, transparency, and regulatory compliance. We discuss best practices and guidelines for the responsible development and deployment of LLMs in healthcare settings. Realizing the full potential of LLMs in digital health will require close collaboration between the AI and healthcare professionals communities to address technical challenges and ensure these powerful tools' safety, efficacy, and equity.