 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeASMa: Asymmetric Spatio-temporal Masking for Skeleton Action Representation Learning
Feb 05, 2026Self-supervised learning (SSL) has shown remarkable success in skeleton-based action recognition by leveraging data augmentations to learn meaningful representations. However, existing SSL methods rely on data augmentations that predominantly focus on masking high-motion frames and high-degree joints such as joints with degree 3 or 4. This results in biased and incomplete feature representations that struggle to generalize across varied motion patterns. To address this, we propose Asymmetric Spatio-temporal Masking (ASMa) for Skeleton Action Representation Learning, a novel combination of masking to learn a full spectrum of spatio-temporal dynamics inherent in human actions. ASMa employs two complementary masking strategies: one that selectively masks high-degree joints and low-motion, and another that masks low-degree joints and high-motion frames. These masking strategies ensure a more balanced and comprehensive skeleton representation learning. Furthermore, we introduce a learnable feature alignment module to effectively align the representations learned from both masked views. To facilitate deployment in resource-constrained settings and on low-resource devices, we compress the learned and aligned representation into a lightweight model using knowledge distillation. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, and PKU-MMD datasets demonstrate that our approach outperforms existing SSL methods with an average improvement of 2.7-4.4% in fine-tuning and up to 5.9% in transfer learning to noisy datasets and achieves competitive performance compared to fully supervised baselines. Our distilled model achieves 91.4% parameter reduction and 3x faster inference on edge devices while maintaining competitive accuracy, enabling practical deployment in resource-constrained scenarios.
InfGraND: An Influence-Guided GNN-to-MLP Knowledge Distillation
Jan 12, 2026Graph Neural Networks (GNNs) are the go-to model for graph data analysis. However, GNNs rely on two key operations - aggregation and update, which can pose challenges for low-latency inference tasks or resource-constrained scenarios. Simple Multi-Layer Perceptrons (MLPs) offer a computationally efficient alternative. Yet, training an MLP in a supervised setting often leads to suboptimal performance. Knowledge Distillation (KD) from a GNN teacher to an MLP student has emerged to bridge this gap. However, most KD methods either transfer knowledge uniformly across all nodes or rely on graph-agnostic indicators such as prediction uncertainty. We argue this overlooks a more fundamental, graph-centric inquiry: "How important is a node to the structure of the graph?" We introduce a framework, InfGraND, an Influence-guided Graph KNowledge Distillation from GNN to MLP that addresses this by identifying and prioritizing structurally influential nodes to guide the distillation process, ensuring that the MLP learns from the most critical parts of the graph. Additionally, InfGraND embeds structural awareness in MLPs through one-time multi-hop neighborhood feature pre-computation, which enriches the student MLP's input and thus avoids inference-time overhead. Our rigorous evaluation in transductive and inductive settings across seven homophilic graph benchmark datasets shows InfGraND consistently outperforms prior GNN to MLP KD methods, demonstrating its practicality for numerous latency-critical applications in real-world settings.
Interpreting Biomedical VLMs on High-Imbalance Out-of-Distributions: An Insight into BiomedCLIP on Radiology
Jun 17, 2025


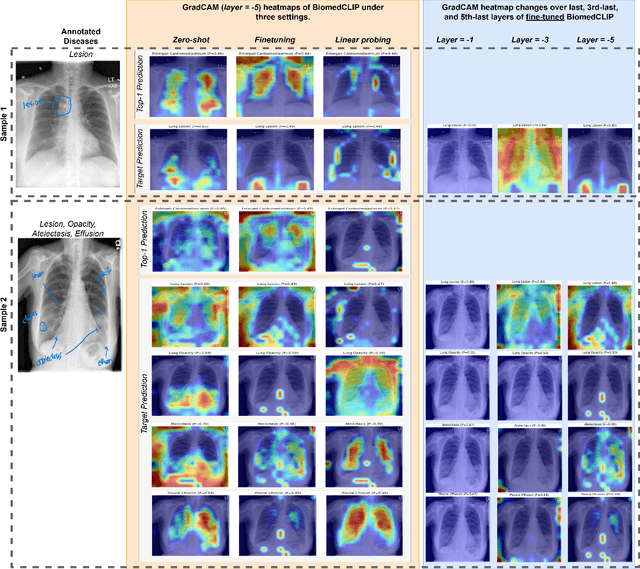
In this paper, we construct two research objectives: i) explore the learned embedding space of BiomedCLIP, an open-source large vision language model, to analyse meaningful class separations, and ii) quantify the limitations of BiomedCLIP when applied to a highly imbalanced, out-of-distribution multi-label medical dataset. We experiment on IU-xray dataset, which exhibits the aforementioned criteria, and evaluate BiomedCLIP in classifying images (radiographs) in three contexts: zero-shot inference, full finetuning, and linear probing. The results show that the model under zero-shot settings over-predicts all labels, leading to poor precision and inter-class separability. Full fine-tuning improves classification of distinct diseases, while linear probing detects overlapping features. We demonstrate visual understanding of the model using Grad-CAM heatmaps and compare with 15 annotations by a radiologist. We highlight the need for careful adaptations of the models to foster reliability and applicability in a real-world setting. The code for the experiments in this work is available and maintained on GitHub.
SDA-GRIN for Adaptive Spatial-Temporal Multivariate Time Series Imputation
Oct 04, 2024



In various applications, the multivariate time series often suffers from missing data. This issue can significantly disrupt systems that rely on the data. Spatial and temporal dependencies can be leveraged to impute the missing samples. Existing imputation methods often ignore dynamic changes in spatial dependencies. We propose a Spatial Dynamic Aware Graph Recurrent Imputation Network (SDA-GRIN) which is capable of capturing dynamic changes in spatial dependencies.SDA-GRIN leverages a multi-head attention mechanism to adapt graph structures with time. SDA-GRIN models multivariate time series as a sequence of temporal graphs and uses a recurrent message-passing architecture for imputation. We evaluate SDA-GRIN on four real-world datasets: SDA-GRIN improves MSE by 9.51% for the AQI and 9.40% for AQI-36. On the PEMS-BAY dataset, it achieves a 1.94% improvement in MSE. Detailed ablation study demonstrates the effect of window sizes and missing data on the performance of the method. Project page:https://ameskandari.github.io/sda-grin/
Survey: Transformer-based Models in Data Modality Conversion
Aug 08, 2024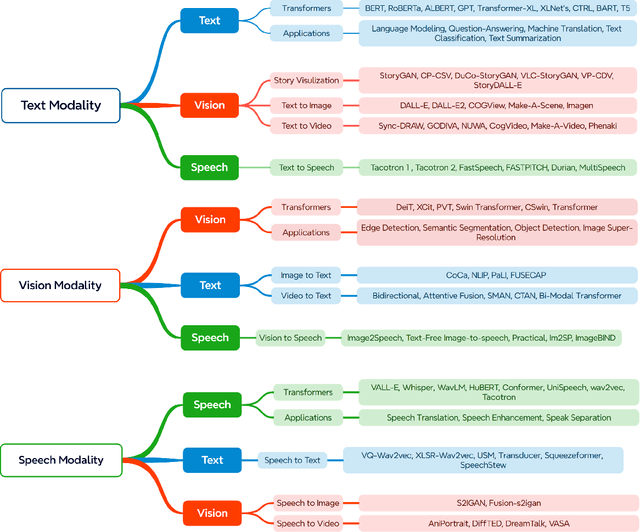
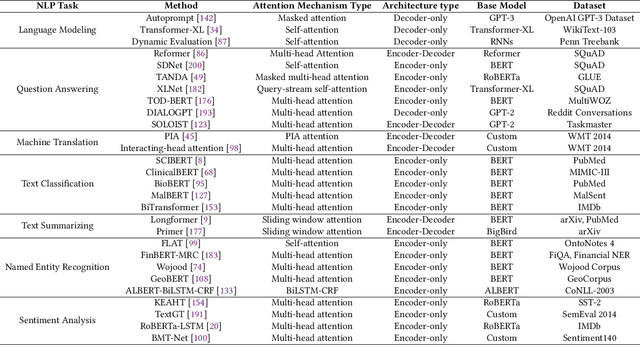

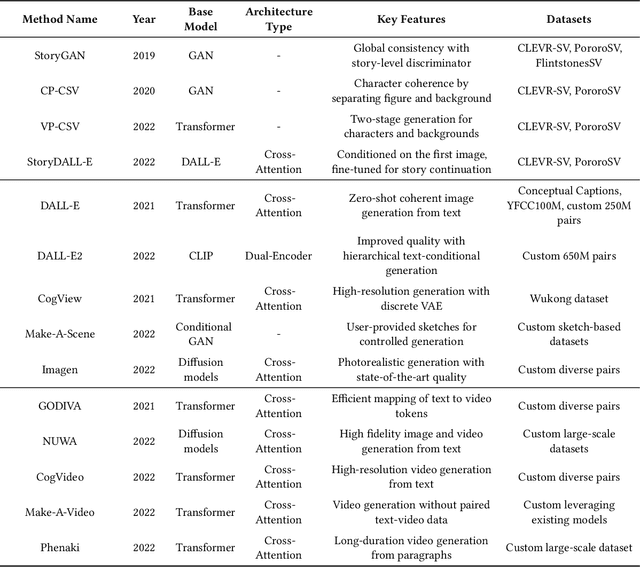
Transformers have made significant strides across various artificial intelligence domains, including natural language processing, computer vision, and audio processing. This success has naturally garnered considerable interest from both academic and industry researchers. Consequently, numerous Transformer variants (often referred to as X-formers) have been developed for these fields. However, a thorough and systematic review of these modality-specific conversions remains lacking. Modality Conversion involves the transformation of data from one form of representation to another, mimicking the way humans integrate and interpret sensory information. This paper provides a comprehensive review of transformer-based models applied to the primary modalities of text, vision, and speech, discussing their architectures, conversion methodologies, and applications. By synthesizing the literature on modality conversion, this survey aims to underline the versatility and scalability of transformers in advancing AI-driven content generation and understanding.
Leveraging Large Language Models for Patient Engagement: The Power of Conversational AI in Digital Health
Jun 19, 2024



The rapid advancements in large language models (LLMs) have opened up new opportunities for transforming patient engagement in healthcare through conversational AI. This paper presents an overview of the current landscape of LLMs in healthcare, specifically focusing on their applications in analyzing and generating conversations for improved patient engagement. We showcase the power of LLMs in handling unstructured conversational data through four case studies: (1) analyzing mental health discussions on Reddit, (2) developing a personalized chatbot for cognitive engagement in seniors, (3) summarizing medical conversation datasets, and (4) designing an AI-powered patient engagement system. These case studies demonstrate how LLMs can effectively extract insights and summarizations from unstructured dialogues and engage patients in guided, goal-oriented conversations. Leveraging LLMs for conversational analysis and generation opens new doors for many patient-centered outcomes research opportunities. However, integrating LLMs into healthcare raises important ethical considerations regarding data privacy, bias, transparency, and regulatory compliance. We discuss best practices and guidelines for the responsible development and deployment of LLMs in healthcare settings. Realizing the full potential of LLMs in digital health will require close collaboration between the AI and healthcare professionals communities to address technical challenges and ensure these powerful tools' safety, efficacy, and equity.
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
May 29, 2024
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
CoBEVFusion: Cooperative Perception with LiDAR-Camera Bird's-Eye View Fusion
Oct 09, 2023Autonomous Vehicles (AVs) use multiple sensors to gather information about their surroundings. By sharing sensor data between Connected Autonomous Vehicles (CAVs), the safety and reliability of these vehicles can be improved through a concept known as cooperative perception. However, recent approaches in cooperative perception only share single sensor information such as cameras or LiDAR. In this research, we explore the fusion of multiple sensor data sources and present a framework, called CoBEVFusion, that fuses LiDAR and camera data to create a Bird's-Eye View (BEV) representation. The CAVs process the multi-modal data locally and utilize a Dual Window-based Cross-Attention (DWCA) module to fuse the LiDAR and camera features into a unified BEV representation. The fused BEV feature maps are shared among the CAVs, and a 3D Convolutional Neural Network is applied to aggregate the features from the CAVs. Our CoBEVFusion framework was evaluated on the cooperative perception dataset OPV2V for two perception tasks: BEV semantic segmentation and 3D object detection. The results show that our DWCA LiDAR-camera fusion model outperforms perception models with single-modal data and state-of-the-art BEV fusion models. Our overall cooperative perception architecture, CoBEVFusion, also achieves comparable performance with other cooperative perception models.
A Preliminary Study on Pattern Reconstruction for Optimal Storage of Wearable Sensor Data
Feb 25, 2023
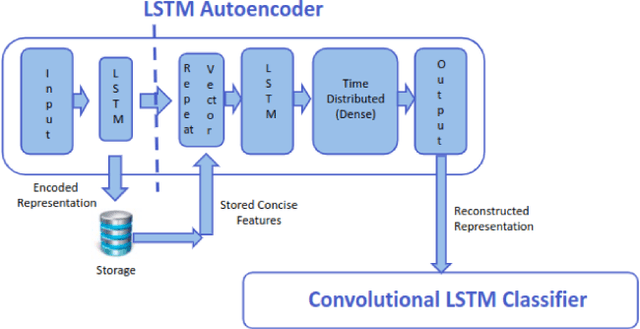
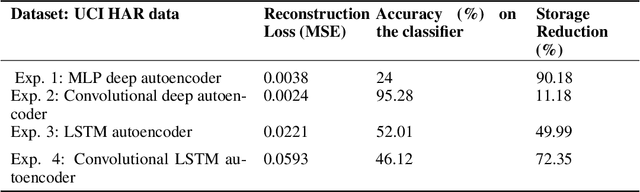
Efficient querying and retrieval of healthcare data is posing a critical challenge today with numerous connected devices continuously generating petabytes of images, text, and internet of things (IoT) sensor data. One approach to efficiently store the healthcare data is to extract the relevant and representative features and store only those features instead of the continuous streaming data. However, it raises a question as to the amount of information content we can retain from the data and if we can reconstruct the pseudo-original data when needed. By facilitating relevant and representative feature extraction, storage and reconstruction of near original pattern, we aim to address some of the challenges faced by the explosion of the streaming data. We present a preliminary study, where we explored multiple autoencoders for concise feature extraction and reconstruction for human activity recognition (HAR) sensor data. Our Multi-Layer Perceptron (MLP) deep autoencoder achieved a storage reduction of 90.18% compared to the three other implemented autoencoders namely convolutional autoencoder, Long-Short Term Memory (LSTM) autoencoder, and convolutional LSTM autoencoder which achieved storage reductions of 11.18%, 49.99%, and 72.35% respectively. Encoded features from the autoencoders have smaller size and dimensions which help to reduce the storage space. For higher dimensions of the representation, storage reduction was low. But retention of relevant information was high, which was validated by classification performed on the reconstructed data.
A Web Application for Experimenting and Validating Remote Measurement of Vital Signs
Aug 21, 2022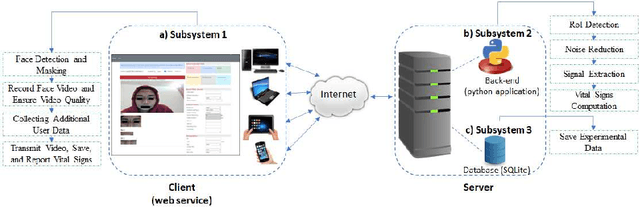

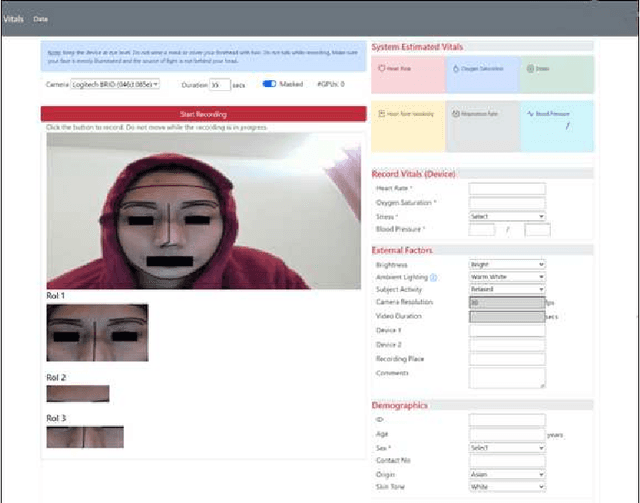
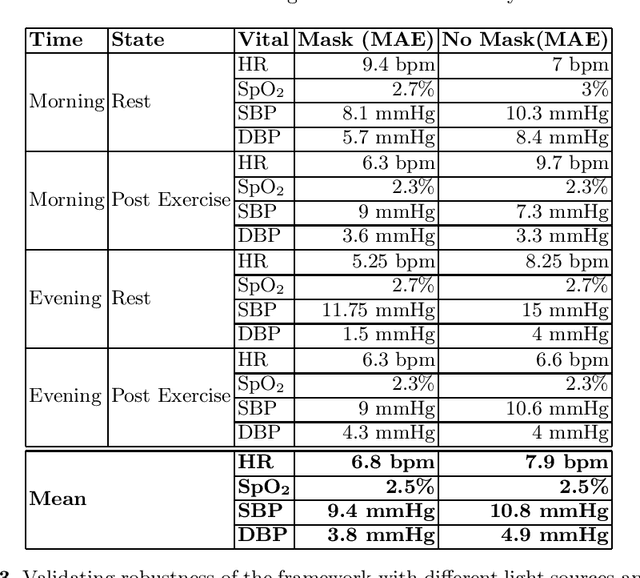
With a surge in online medical advising remote monitoring of patient vitals is required. This can be facilitated with the Remote Photoplethysmography (rPPG) techniques that compute vital signs from facial videos. It involves processing video frames to obtain skin pixels, extracting the cardiac data from it and applying signal processing filters to extract the Blood Volume Pulse (BVP) signal. Different algorithms are applied to the BVP signal to estimate the various vital signs. We implemented a web application framework to measure a person's Heart Rate (HR), Heart Rate Variability (HRV), Oxygen Saturation (SpO2), Respiration Rate (RR), Blood Pressure (BP), and stress from the face video. The rPPG technique is highly sensitive to illumination and motion variation. The web application guides the users to reduce the noise due to these variations and thereby yield a cleaner BVP signal. The accuracy and robustness of the framework was validated with the help of volunteers.