 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInfGraND: An Influence-Guided GNN-to-MLP Knowledge Distillation
Jan 12, 2026Graph Neural Networks (GNNs) are the go-to model for graph data analysis. However, GNNs rely on two key operations - aggregation and update, which can pose challenges for low-latency inference tasks or resource-constrained scenarios. Simple Multi-Layer Perceptrons (MLPs) offer a computationally efficient alternative. Yet, training an MLP in a supervised setting often leads to suboptimal performance. Knowledge Distillation (KD) from a GNN teacher to an MLP student has emerged to bridge this gap. However, most KD methods either transfer knowledge uniformly across all nodes or rely on graph-agnostic indicators such as prediction uncertainty. We argue this overlooks a more fundamental, graph-centric inquiry: "How important is a node to the structure of the graph?" We introduce a framework, InfGraND, an Influence-guided Graph KNowledge Distillation from GNN to MLP that addresses this by identifying and prioritizing structurally influential nodes to guide the distillation process, ensuring that the MLP learns from the most critical parts of the graph. Additionally, InfGraND embeds structural awareness in MLPs through one-time multi-hop neighborhood feature pre-computation, which enriches the student MLP's input and thus avoids inference-time overhead. Our rigorous evaluation in transductive and inductive settings across seven homophilic graph benchmark datasets shows InfGraND consistently outperforms prior GNN to MLP KD methods, demonstrating its practicality for numerous latency-critical applications in real-world settings.
Survey: Transformer-based Models in Data Modality Conversion
Aug 08, 2024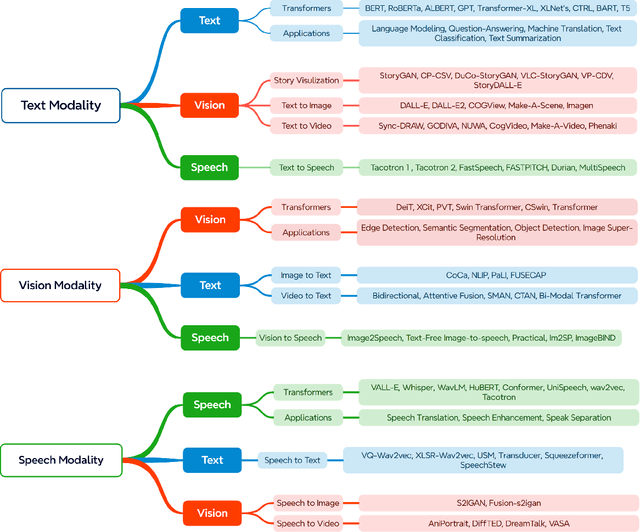
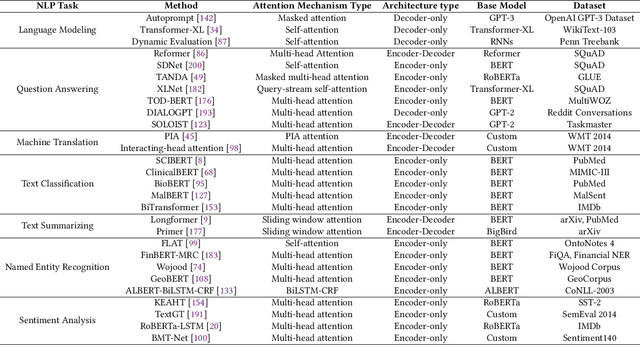

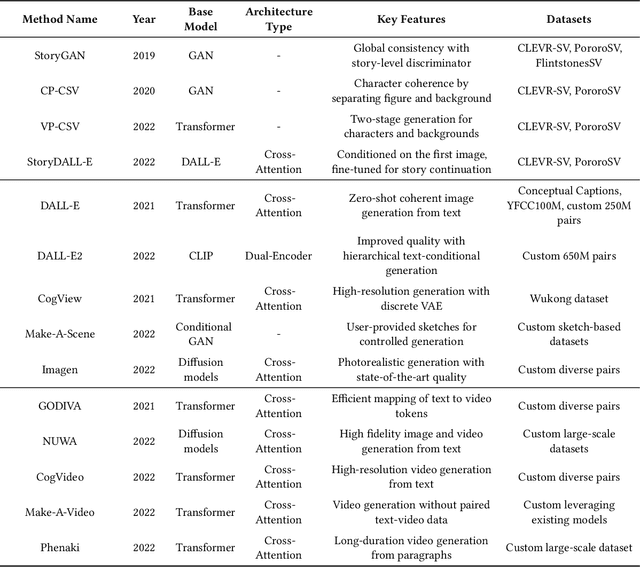
Transformers have made significant strides across various artificial intelligence domains, including natural language processing, computer vision, and audio processing. This success has naturally garnered considerable interest from both academic and industry researchers. Consequently, numerous Transformer variants (often referred to as X-formers) have been developed for these fields. However, a thorough and systematic review of these modality-specific conversions remains lacking. Modality Conversion involves the transformation of data from one form of representation to another, mimicking the way humans integrate and interpret sensory information. This paper provides a comprehensive review of transformer-based models applied to the primary modalities of text, vision, and speech, discussing their architectures, conversion methodologies, and applications. By synthesizing the literature on modality conversion, this survey aims to underline the versatility and scalability of transformers in advancing AI-driven content generation and understanding.
Fluid segmentation in Neutrosophic domain
Dec 23, 2019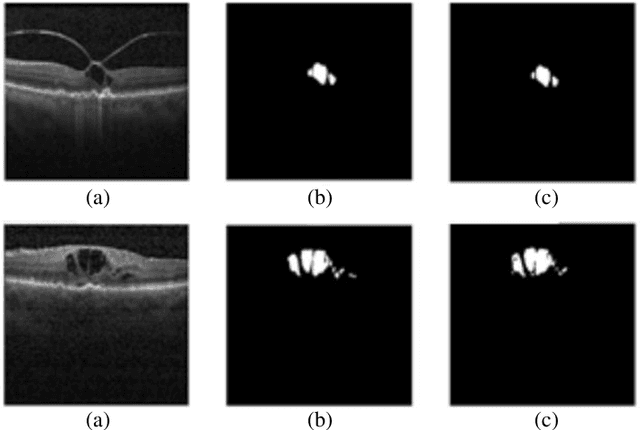
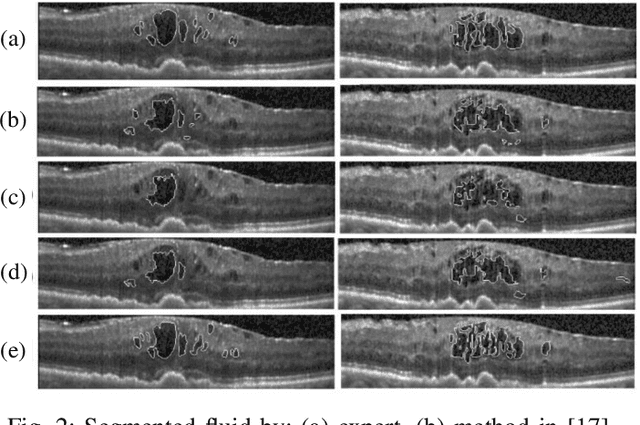
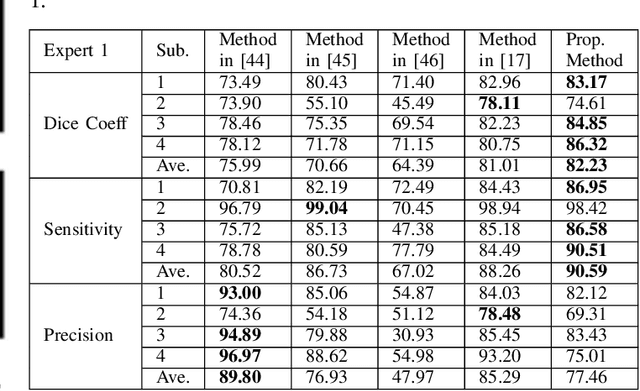
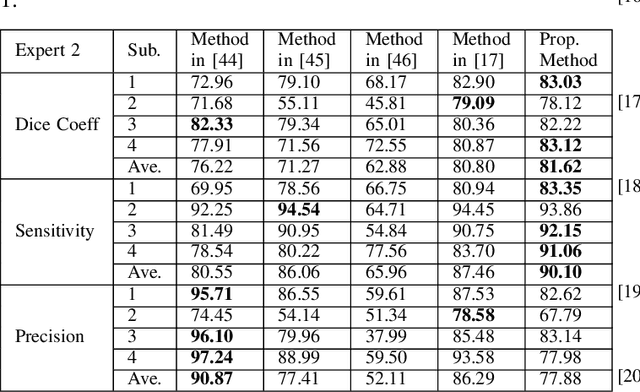
Optical coherence tomography (OCT) as retina imaging technology is currently used by ophthalmologist as a non-invasive and non-contact method for diagnosis of agerelated degeneration (AMD) and diabetic macular edema (DME) diseases. Fluid regions in OCT images reveal the main signs of AMD and DME. In this paper, an efficient and fast clustering in neutrosophic (NS) domain referred as neutrosophic C-means is adapted for fluid segmentation. For this task, a NCM cost function in NS domain is adapted for fluid segmentation and then optimized by gradient descend methods which leads to binary segmentation of OCT Bscans to fluid and tissue regions. The proposed method is evaluated in OCT datasets of subjects with DME abnormalities. Results showed that the proposed method outperforms existing fluid segmentation methods by 6% in dice coefficient and sensitivity criteria.
Content-based image retrieval speedup
Dec 22, 2019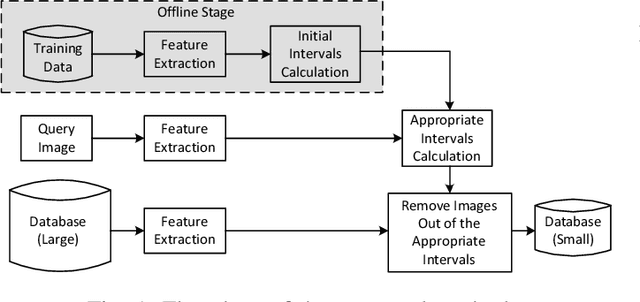
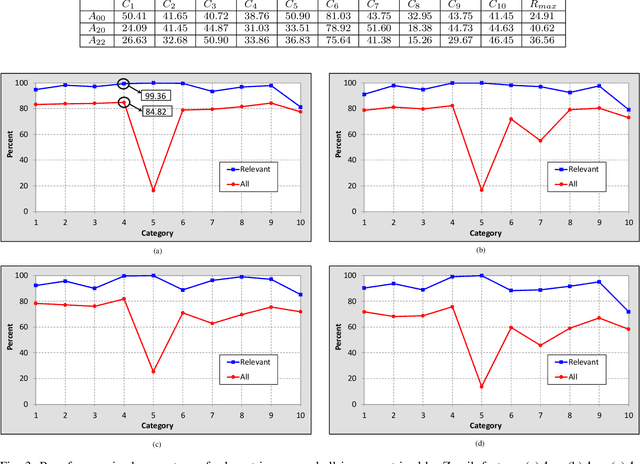
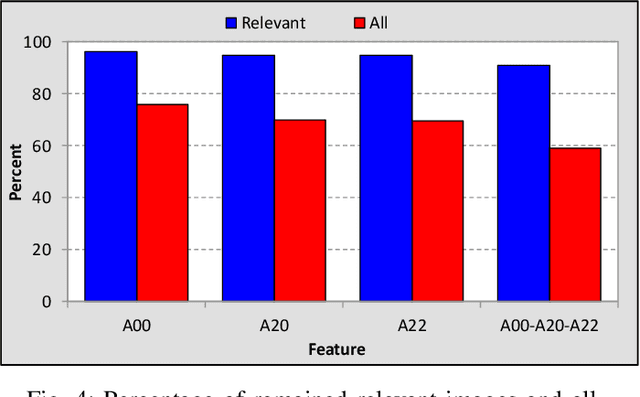
Content-based image retrieval (CBIR) is a task of retrieving images from their contents. Since retrieval process is a time-consuming task in large image databases, acceleration methods can be very useful. This paper presents a novel method to speed up CBIR systems. In the proposed method, first Zernike moments are extracted from query image and an interval is calculated for that query. Images in database which are out of the interval are ignored in retrieval process. Therefore, a database reduction occurs before retrieval which leads to speed up. It is shown that in reduced database, relevant images to query image are preserved and irrelevant images are throwed away. Therefore, the proposed method speed up retrieval process and preserve CBIR accuracy, simultaneously.
Content-based image retrieval system with most relevant features among wavelet and color features
Feb 06, 2019



Content-based image retrieval (CBIR) has become one of the most important research directions in the domain of digital data management. In this paper, a new feature extraction schema including the norm of low frequency components in wavelet transformation and color features in RGB and HSV domains are proposed as representative feature vector for images in database followed by appropriate similarity measure for each feature type. In CBIR systems, retrieving results are so sensitive to image features. We address this problem with selection of most relevant features among complete feature set by ant colony optimization (ACO)-based feature selection which minimize the number of features as well as maximize F-measure in CBIR system. To evaluate the performance of our proposed CBIR system, it has been compared with three older proposed systems. Results show that the precision and recall of our proposed system are higher than older ones for the majority of image categories in Corel database.
A Convolutional Neural Network model based on Neutrosophy for Noisy Speech Recognition
Jan 27, 2019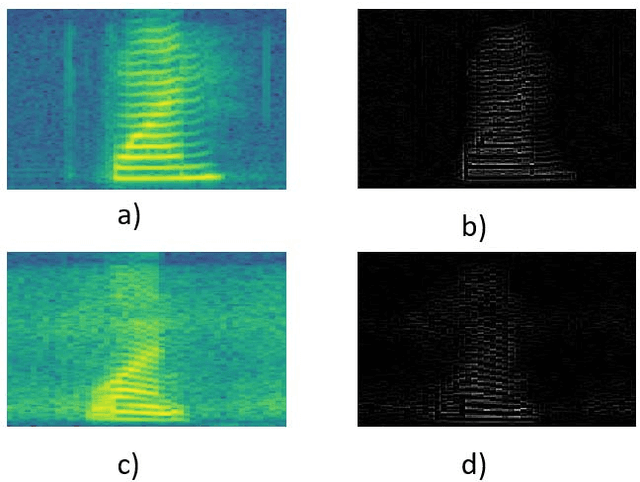
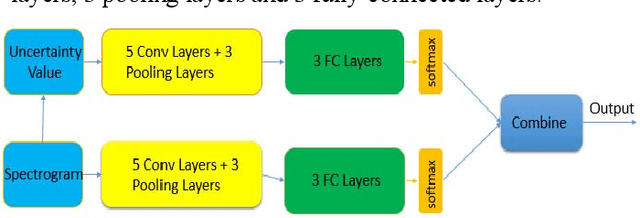
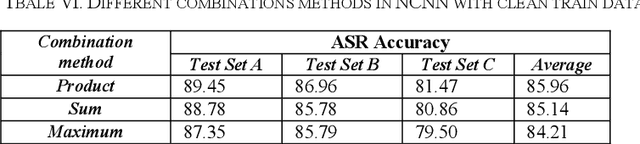
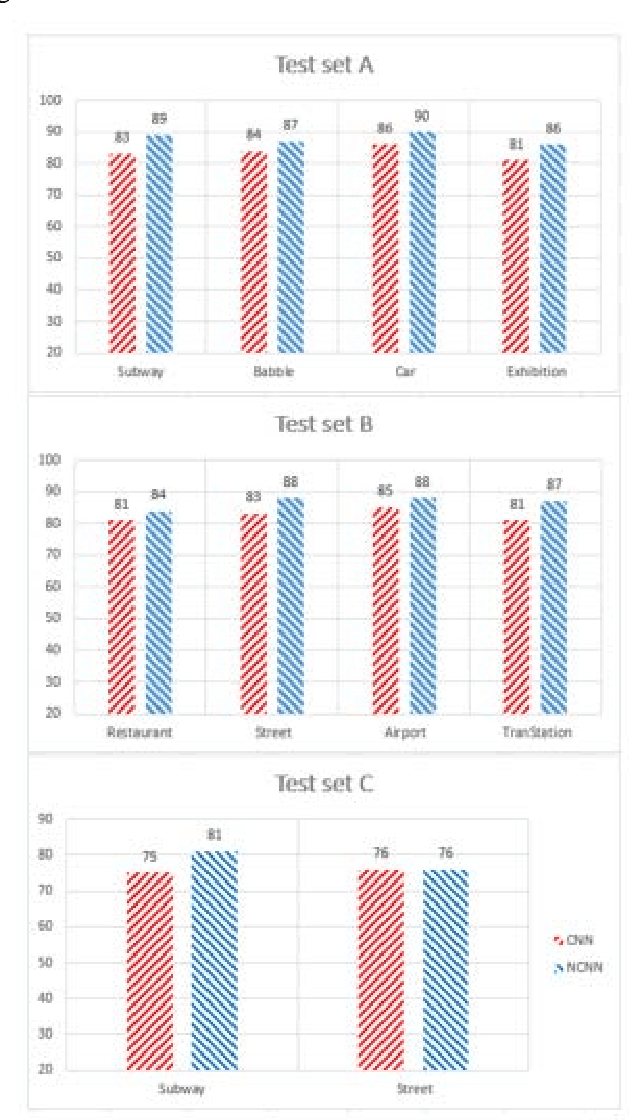
Convolutional neural networks are sensitive to unknown noisy condition in the test phase and so their performance degrades for the noisy data classification task including noisy speech recognition. In this research, a new convolutional neural network (CNN) model with data uncertainty handling; referred as NCNN (Neutrosophic Convolutional Neural Network); is proposed for classification task. Here, speech signals are used as input data and their noise is modeled as uncertainty. In this task, using speech spectrogram, a definition of uncertainty is proposed in neutrosophic (NS) domain. Uncertainty is computed for each Time-frequency point of speech spectrogram as like a pixel. Therefore, uncertainty matrix with the same size of spectrogram is created in NS domain. In the next step, a two parallel paths CNN classification model is proposed. Speech spectrogram is used as input of the first path and uncertainty matrix for the second path. The outputs of two paths are combined to compute the final output of the classifier. To show the effectiveness of the proposed method, it has been compared with conventional CNN on the isolated words of Aurora2 dataset. The proposed method achieves the average accuracy of 85.96 in noisy train data. It is more robust against Car, Airport and Subway noises with accuracies 90, 88 and 81 in test sets A, B and C, respectively. Results show that the proposed method outperforms conventional CNN with the improvement of 6, 5 and 2 percentage in test set A, test set B and test sets C, respectively. It means that the proposed method is more robust against noisy data and handle these data effectively.