 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExa-PSD: a new Persian sentiment analysis dataset on Twitter
Feb 24, 2026Today, Social networks such as Twitter are the most widely used platforms for communication of people. Analyzing this data has useful information to recognize the opinion of people in tweets. Sentiment analysis plays a vital role in NLP, which identifies the opinion of the individuals about a specific topic. Natural language processing in Persian has many challenges despite the adventure of strong language models. The datasets available in Persian are generally in special topics such as products, foods, hotels, etc while users may use ironies, colloquial phrases in social media To overcome these challenges, there is a necessity for having a dataset of Persian sentiment analysis on Twitter. In this paper, we introduce the Exa sentiment analysis Persian dataset, which is collected from Persian tweets. This dataset contains 12,000 tweets, annotated by 5 native Persian taggers. The aforementioned data is labeled in 3 classes: positive, neutral and negative. We present the characteristics and statistics of this dataset and use the pre-trained Pars Bert and Roberta as the base model to evaluate this dataset. Our evaluation reached a 79.87 Macro F-score, which shows the model and data can be adequately valuable for a sentiment analysis system.
* This is the original submitted (preprint) version of a paper published in Language Resources and Evaluation. The final published version is available at Springer via DOI: https://doi.org/10.1007/s10579-025-09886-5
ExaASC: A General Target-Based Stance Detection Corpus in Arabic Language
Apr 29, 2022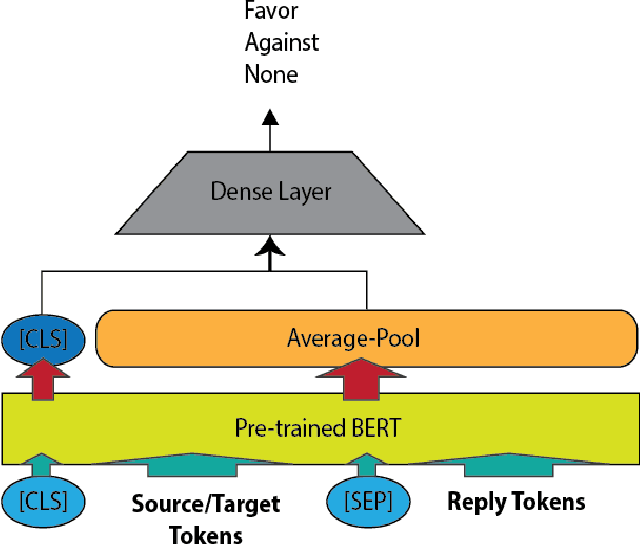
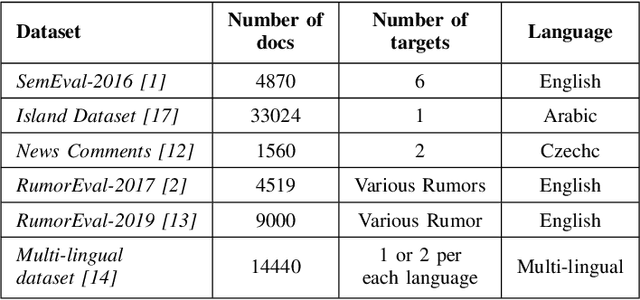
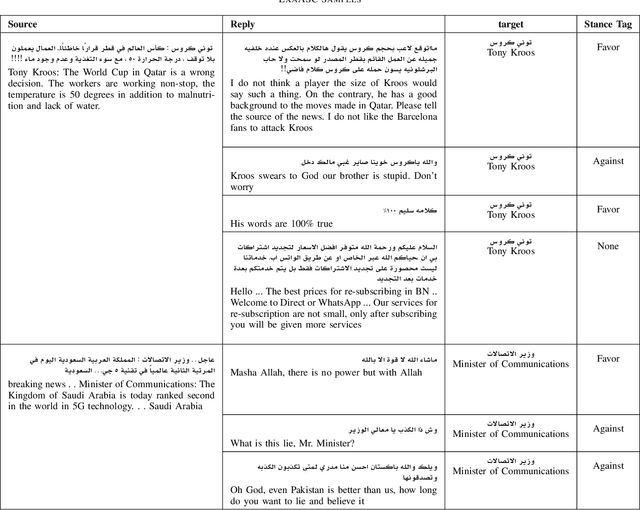
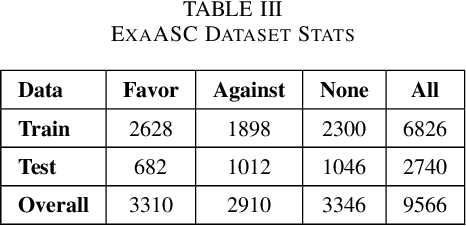
Target-based Stance Detection is the task of finding a stance toward a target. Twitter is one of the primary sources of political discussions in social media and one of the best resources to analyze Stance toward entities. This work proposes a new method toward Target-based Stance detection by using the stance of replies toward a most important and arguing target in source tweet. This target is detected with respect to the source tweet itself and not limited to a set of pre-defined targets which is the usual approach of the current state-of-the-art methods. Our proposed new attitude resulted in a new corpus called ExaASC for the Arabic Language, one of the low resource languages in this field. In the end, we used BERT to evaluate our corpus and reached a 70.69 Macro F-score. This shows that our data and model can work in a general Target-base Stance Detection system. The corpus is publicly available1.
* 6 pages, 1 figure, 4 tables. Accepted at ICCKE 2021
A Convolutional Neural Network model based on Neutrosophy for Noisy Speech Recognition
Jan 27, 2019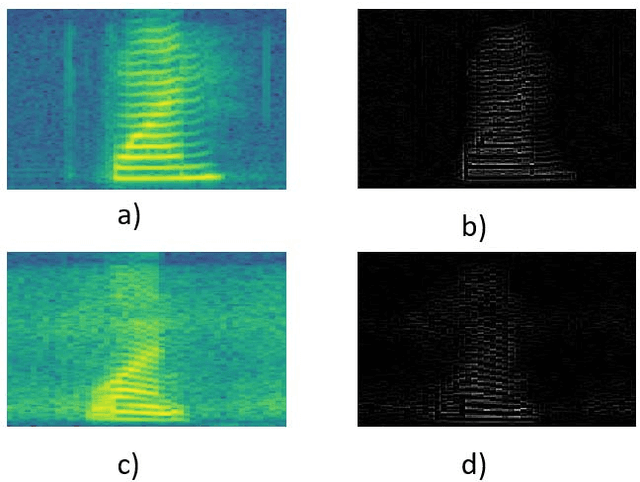
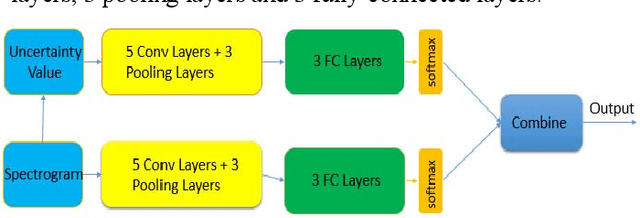
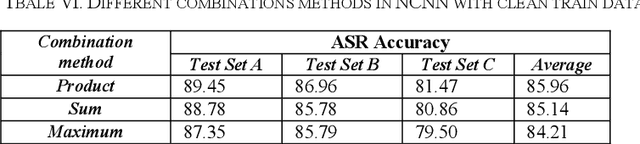
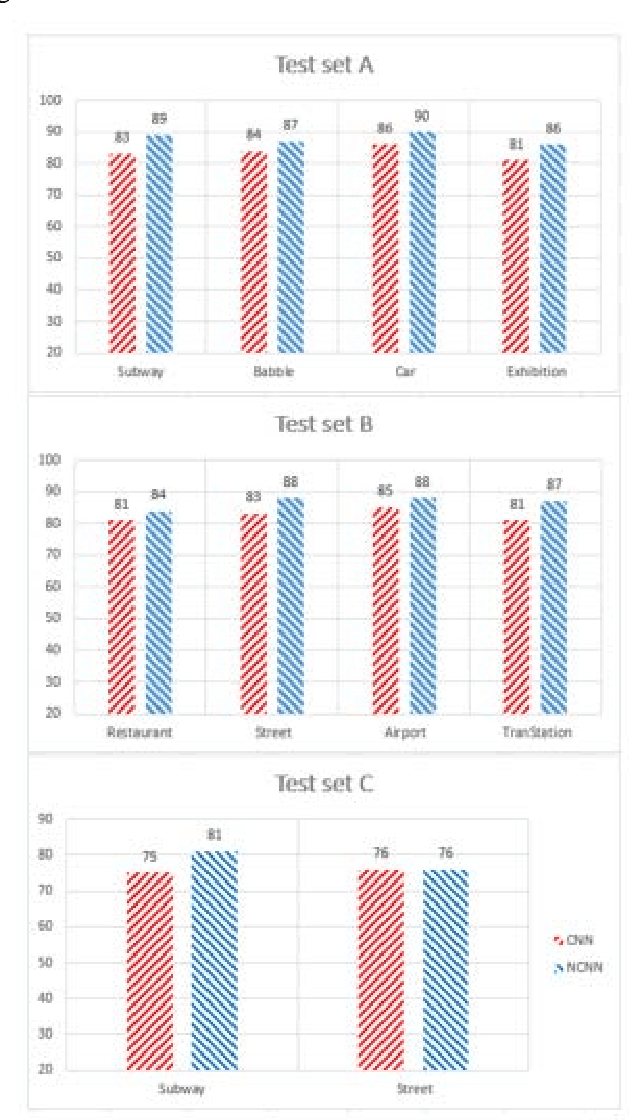
Convolutional neural networks are sensitive to unknown noisy condition in the test phase and so their performance degrades for the noisy data classification task including noisy speech recognition. In this research, a new convolutional neural network (CNN) model with data uncertainty handling; referred as NCNN (Neutrosophic Convolutional Neural Network); is proposed for classification task. Here, speech signals are used as input data and their noise is modeled as uncertainty. In this task, using speech spectrogram, a definition of uncertainty is proposed in neutrosophic (NS) domain. Uncertainty is computed for each Time-frequency point of speech spectrogram as like a pixel. Therefore, uncertainty matrix with the same size of spectrogram is created in NS domain. In the next step, a two parallel paths CNN classification model is proposed. Speech spectrogram is used as input of the first path and uncertainty matrix for the second path. The outputs of two paths are combined to compute the final output of the classifier. To show the effectiveness of the proposed method, it has been compared with conventional CNN on the isolated words of Aurora2 dataset. The proposed method achieves the average accuracy of 85.96 in noisy train data. It is more robust against Car, Airport and Subway noises with accuracies 90, 88 and 81 in test sets A, B and C, respectively. Results show that the proposed method outperforms conventional CNN with the improvement of 6, 5 and 2 percentage in test set A, test set B and test sets C, respectively. It means that the proposed method is more robust against noisy data and handle these data effectively.