 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthTensor: Evaluating LLMs through Human Imitation on Prediction Market under Drift and Holistic Reasoning
Jan 25, 2026Evaluating language models and AI agents remains fundamentally challenging because static benchmarks fail to capture real-world uncertainty, distribution shift, and the gap between isolated task accuracy and human-aligned decision-making under evolving conditions. This paper introduces TruthTensor, a novel, reproducible evaluation paradigm that measures reasoning models not only as prediction engines but as human-imitation systems operating in socially-grounded, high-entropy environments. Building on forward-looking, contamination-free tasks, our framework anchors evaluation to live prediction markets and combines probabilistic scoring to provide a holistic view of model behavior. TruthTensor complements traditional correctness metrics with drift-centric diagnostics and explicit robustness checks for reproducibility. It specify human vs. automated evaluation roles, annotation protocols, and statistical testing procedures to ensure interpretability and replicability of results. In experiments across 500+ real markets (political, economic, cultural, technological), TruthTensor demonstrates that models with similar forecast accuracy can diverge markedly in calibration, drift, and risk-sensitivity, underscoring the need to evaluate models along multiple axes (accuracy, calibration, narrative stability, cost, and resource efficiency). TruthTensor therefore operationalizes modern evaluation best practices, clear hypothesis framing, careful metric selection, transparent compute/cost reporting, human-in-the-loop validation, and open, versioned evaluation contracts, to produce defensible assessments of LLMs in real-world decision contexts. We publicly released TruthTensor at https://truthtensor.com.
TruthTensor: Evaluating LLMs Human Imitation through Prediction Market Drift and Holistic Reasoning
Jan 20, 2026Evaluating language models and AI agents remains fundamentally challenging because static benchmarks fail to capture real-world uncertainty, distribution shift, and the gap between isolated task accuracy and human-aligned decision-making under evolving conditions. This paper introduces TruthTensor, a novel, reproducible evaluation paradigm that measures Large Language Models (LLMs) not only as prediction engines but as human-imitation systems operating in socially-grounded, high-entropy environments. Building on forward-looking, contamination-free tasks, our framework anchors evaluation to live prediction markets and combines probabilistic scoring to provide a holistic view of model behavior. TruthTensor complements traditional correctness metrics with drift-centric diagnostics and explicit robustness checks for reproducibility. It specify human vs. automated evaluation roles, annotation protocols, and statistical testing procedures to ensure interpretability and replicability of results. In experiments across 500+ real markets (political, economic, cultural, technological), TruthTensor demonstrates that models with similar forecast accuracy can diverge markedly in calibration, drift, and risk-sensitivity, underscoring the need to evaluate models along multiple axes (accuracy, calibration, narrative stability, cost, and resource efficiency). TruthTensor therefore operationalizes modern evaluation best practices, clear hypothesis framing, careful metric selection, transparent compute/cost reporting, human-in-the-loop validation, and open, versioned evaluation contracts, to produce defensible assessments of LLMs in real-world decision contexts. We publicly release TruthTensor at https://truthtensor.com
DSperse: A Framework for Targeted Verification in Zero-Knowledge Machine Learning
Aug 09, 2025DSperse is a modular framework for distributed machine learning inference with strategic cryptographic verification. Operating within the emerging paradigm of distributed zero-knowledge machine learning, DSperse avoids the high cost and rigidity of full-model circuitization by enabling targeted verification of strategically chosen subcomputations. These verifiable segments, or "slices", may cover part or all of the inference pipeline, with global consistency enforced through audit, replication, or economic incentives. This architecture supports a pragmatic form of trust minimization, localizing zero-knowledge proofs to the components where they provide the greatest value. We evaluate DSperse using multiple proving systems and report empirical results on memory usage, runtime, and circuit behavior under sliced and unsliced configurations. By allowing proof boundaries to align flexibly with the model's logical structure, DSperse supports scalable, targeted verification strategies suited to diverse deployment needs.
Anomaly Detection in Emails using Machine Learning and Header Information
Mar 19, 2022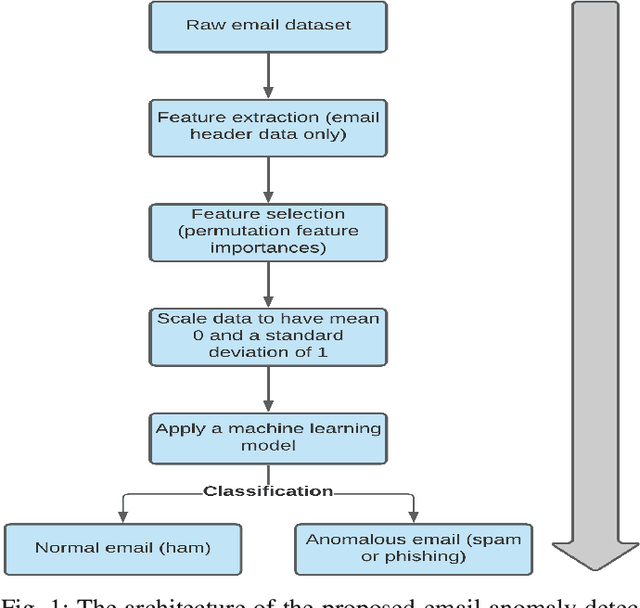
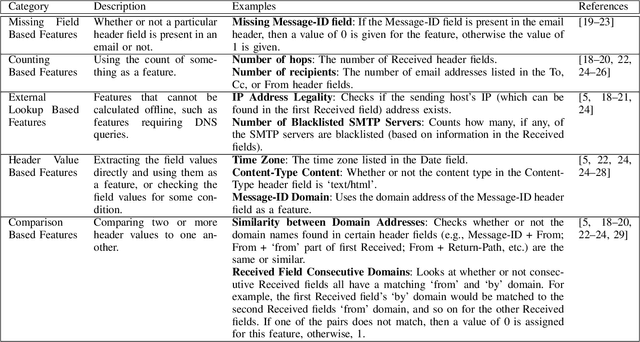
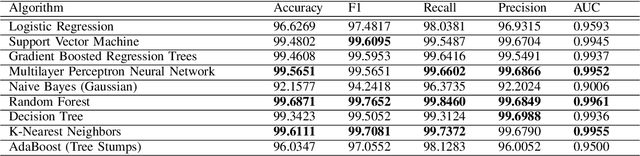
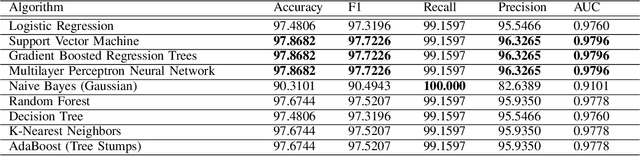
Anomalies in emails such as phishing and spam present major security risks such as the loss of privacy, money, and brand reputation to both individuals and organizations. Previous studies on email anomaly detection relied on a single type of anomaly and the analysis of the email body and subject content. A drawback of this approach is that it takes into account the written language of the email content. To overcome this deficit, this study conducted feature extraction and selection on email header datasets and leveraged both multi and one-class anomaly detection approaches. Experimental analysis results obtained demonstrate that email header information only is enough to reliably detect spam and phishing emails. Supervised learning algorithms such as Random Forest, SVM, MLP, KNN, and their stacked ensembles were found to be very successful, achieving high accuracy scores of 97% for phishing and 99% for spam emails. One-class classification with One-Class SVM achieved accuracy scores of 87% and 89% with spam and phishing emails, respectively. Real-world email filtering applications will benefit from the use of only the header information in terms of resources utilization and efficiency.
Incremental Community Detection in Distributed Dynamic Graph
Oct 12, 2021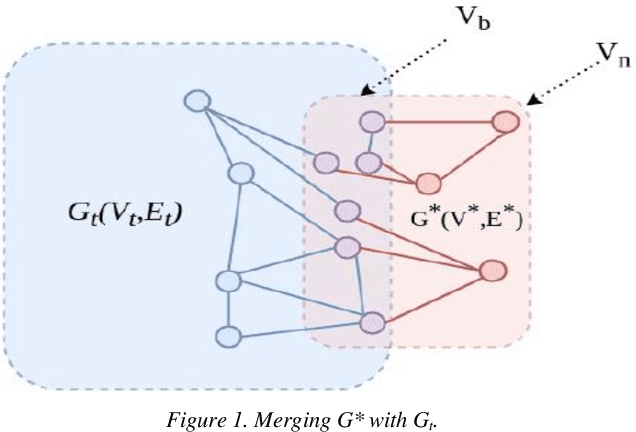
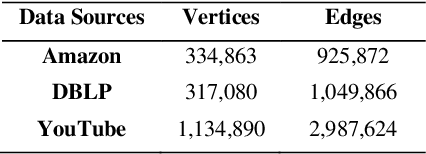
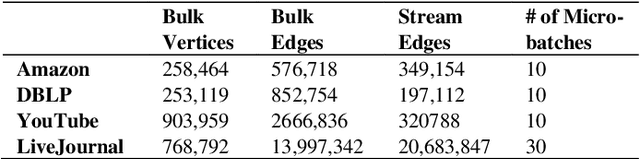
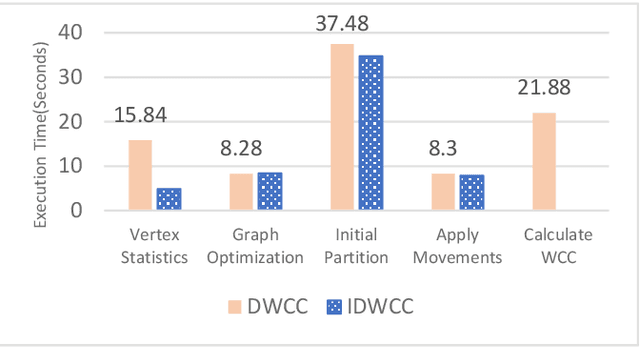
Community detection is an important research topic in graph analytics that has a wide range of applications. A variety of static community detection algorithms and quality metrics were developed in the past few years. However, most real-world graphs are not static and often change over time. In the case of streaming data, communities in the associated graph need to be updated either continuously or whenever new data streams are added to the graph, which poses a much greater challenge in devising good community detection algorithms for maintaining dynamic graphs over streaming data. In this paper, we propose an incremental community detection algorithm for maintaining a dynamic graph over streaming data. The contributions of this study include (a) the implementation of a Distributed Weighted Community Clustering (DWCC) algorithm, (b) the design and implementation of a novel Incremental Distributed Weighted Community Clustering (IDWCC) algorithm, and (c) an experimental study to compare the performance of our IDWCC algorithm with the DWCC algorithm. We validate the functionality and efficiency of our framework in processing streaming data and performing large in-memory distributed dynamic graph analytics. The results demonstrate that our IDWCC algorithm performs up to three times faster than the DWCC algorithm for a similar accuracy.
A Big Data Lake for Multilevel Streaming Analytics
Sep 25, 2020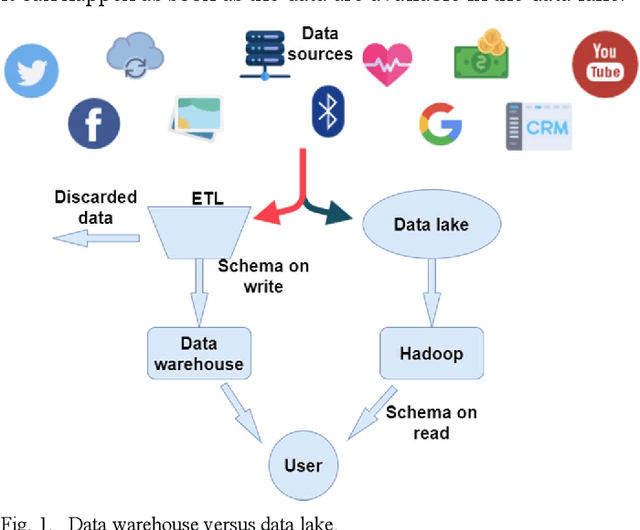
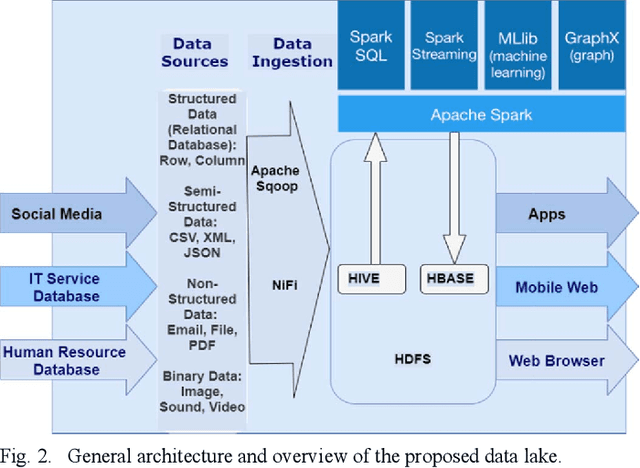
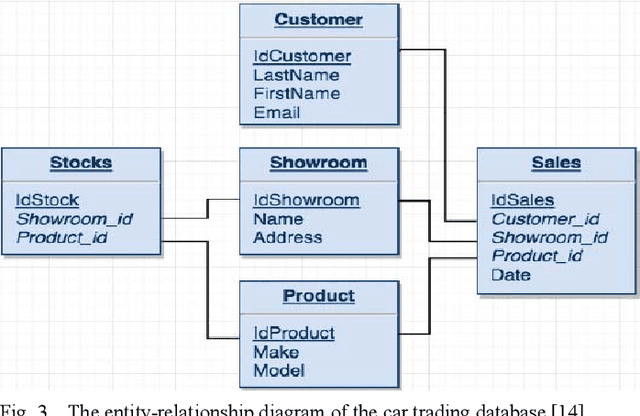
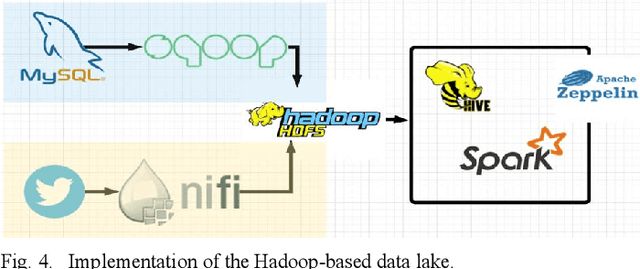
Large organizations are seeking to create new architectures and scalable platforms to effectively handle data management challenges due to the explosive nature of data rarely seen in the past. These data management challenges are largely posed by the availability of streaming data at high velocity from various sources in multiple formats. The changes in data paradigm have led to the emergence of new data analytics and management architecture. This paper focuses on storing high volume, velocity and variety data in the raw formats in a data storage architecture called a data lake. First, we present our study on the limitations of traditional data warehouses in handling recent changes in data paradigms. We discuss and compare different open source and commercial platforms that can be used to develop a data lake. We then describe our end-to-end data lake design and implementation approach using the Hadoop Distributed File System (HDFS) on the Hadoop Data Platform (HDP). Finally, we present a real-world data lake development use case for data stream ingestion, staging, and multilevel streaming analytics which combines structured and unstructured data. This study can serve as a guide for individuals or organizations planning to implement a data lake solution for their use cases.
Towards a Natural Language Query Processing System
Sep 25, 2020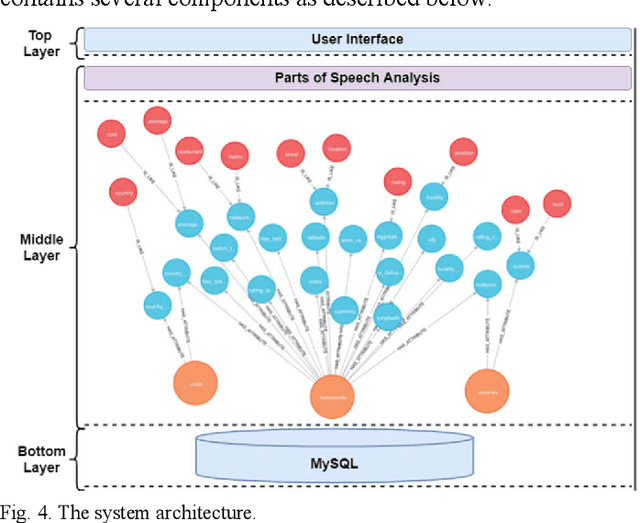
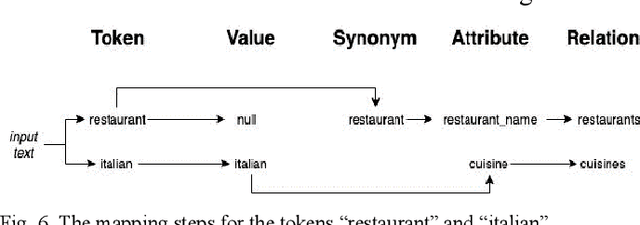

Tackling the information retrieval gap between non-technical database end-users and those with the knowledge of formal query languages has been an interesting area of data management and analytics research. The use of natural language interfaces to query information from databases offers the opportunity to bridge the communication challenges between end-users and systems that use formal query languages. Previous research efforts mainly focused on developing structured query interfaces to relational databases. However, the evolution of unstructured big data such as text, images, and video has exposed the limitations of traditional structured query interfaces. While the existing web search tools prove the popularity and usability of natural language query, they return complete documents and web pages instead of focused query responses and are not applicable to database systems. This paper reports our study on the design and development of a natural language query interface to a backend relational database. The novelty in the study lies in defining a graph database as a middle layer to store necessary metadata needed to transform a natural language query into structured query language that can be executed on backend databases. We implemented and evaluated our approach using a restaurant dataset. The translation results for some sample queries yielded a 90% accuracy rate.
A Voice Interactive Multilingual Student Support System using IBM Watson
Dec 20, 2019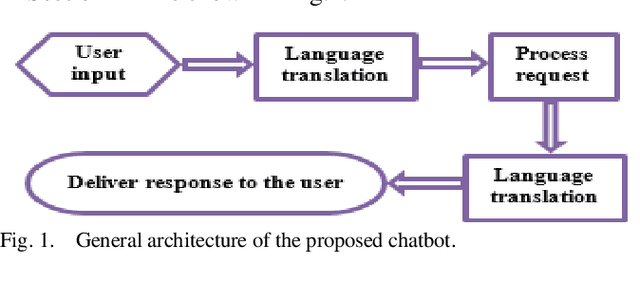

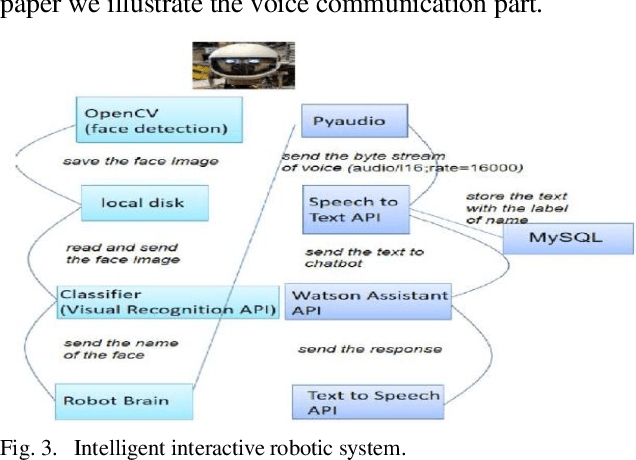
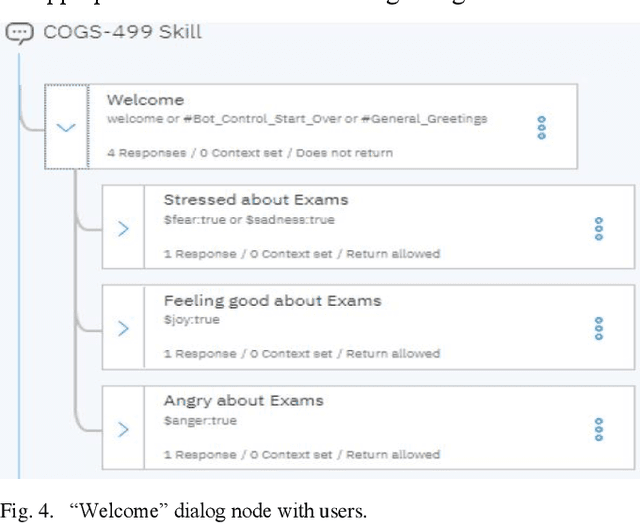
Systems powered by artificial intelligence are being developed to be more user-friendly by communicating with users in a progressively human-like conversational way. Chatbots, also known as dialogue systems, interactive conversational agents, or virtual agents are an example of such systems used in a wide variety of applications ranging from customer support in the business domain to companionship in the healthcare sector. It is becoming increasingly important to develop chatbots that can best respond to the personalized needs of their users so that they can be as helpful to the user as possible in a real human way. This paper investigates and compares three popular existing chatbots API offerings and then propose and develop a voice interactive and multilingual chatbot that can effectively respond to users mood, tone, and language using IBM Watson Assistant, Tone Analyzer, and Language Translator. The chatbot was evaluated using a use case that was targeted at responding to users needs regarding exam stress based on university students survey data generated using Google Forms. The results of measuring the chatbot effectiveness at analyzing responses regarding exam stress indicate that the chatbot responding appropriately to the user queries regarding how they are feeling about exams 76.5%. The chatbot could also be adapted for use in other application areas such as student info-centers, government kiosks, and mental health support systems.
A Scalable Framework for Multilevel Streaming Data Analytics using Deep Learning
Jul 15, 2019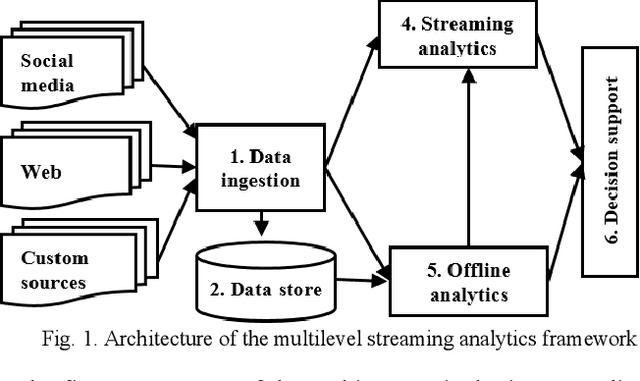
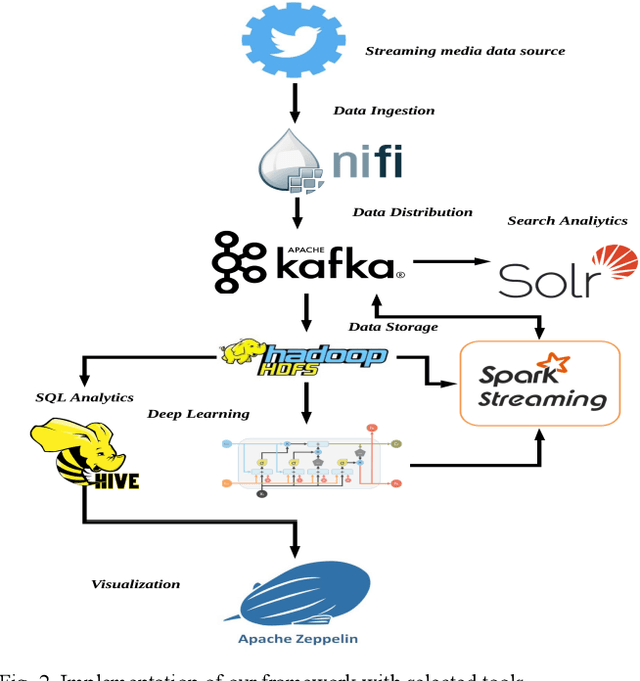
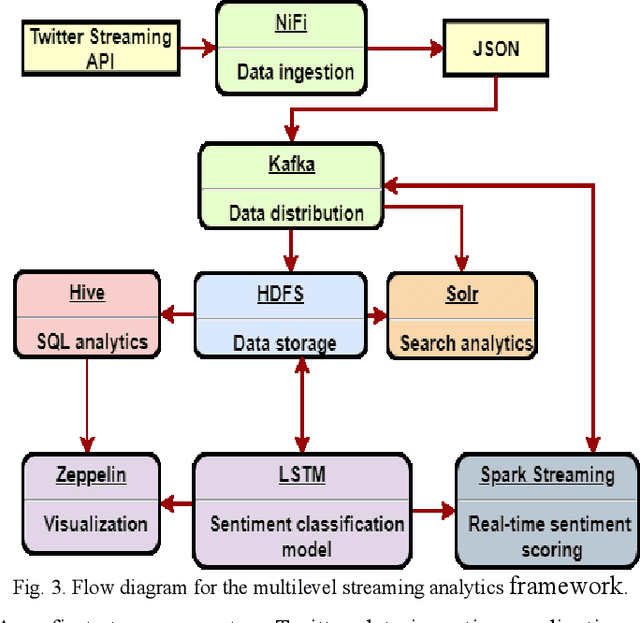
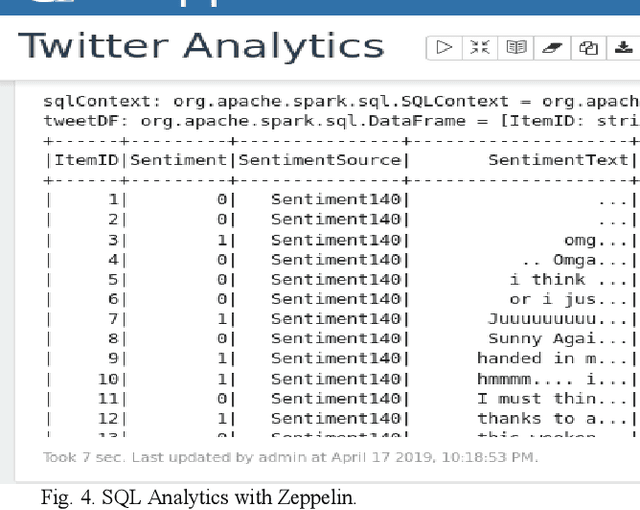
The rapid growth of data in velocity, volume, value, variety, and veracity has enabled exciting new opportunities and presented big challenges for businesses of all types. Recently, there has been considerable interest in developing systems for processing continuous data streams with the increasing need for real-time analytics for decision support in the business, healthcare, manufacturing, and security. The analytics of streaming data usually relies on the output of offline analytics on static or archived data. However, businesses and organizations like our industry partner Gnowit, strive to provide their customers with real time market information and continuously look for a unified analytics framework that can integrate both streaming and offline analytics in a seamless fashion to extract knowledge from large volumes of hybrid streaming data. We present our study on designing a multilevel streaming text data analytics framework by comparing leading edge scalable open-source, distributed, and in-memory technologies. We demonstrate the functionality of the framework for a use case of multilevel text analytics using deep learning for language understanding and sentiment analysis including data indexing and query processing. Our framework combines Spark streaming for real time text processing, the Long Short Term Memory (LSTM) deep learning model for higher level sentiment analysis, and other tools for SQL-based analytical processing to provide a scalable solution for multilevel streaming text analytics.
Predicting the Effects of News Sentiments on the Stock Market
Dec 11, 2018
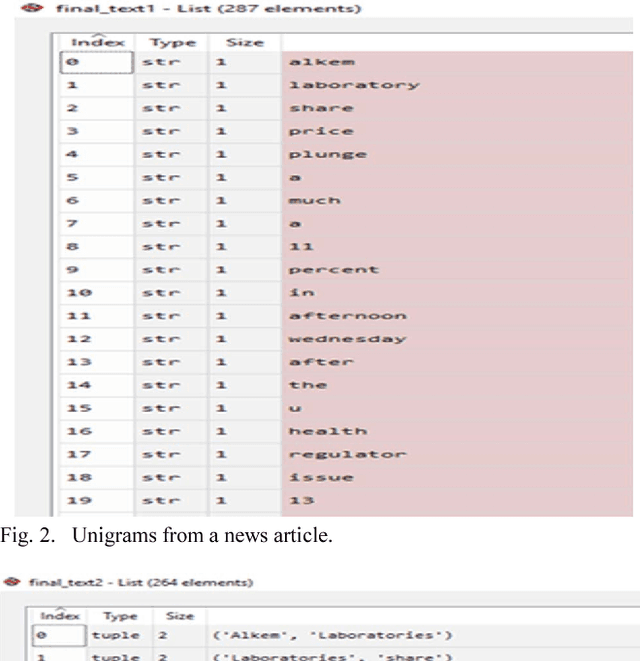
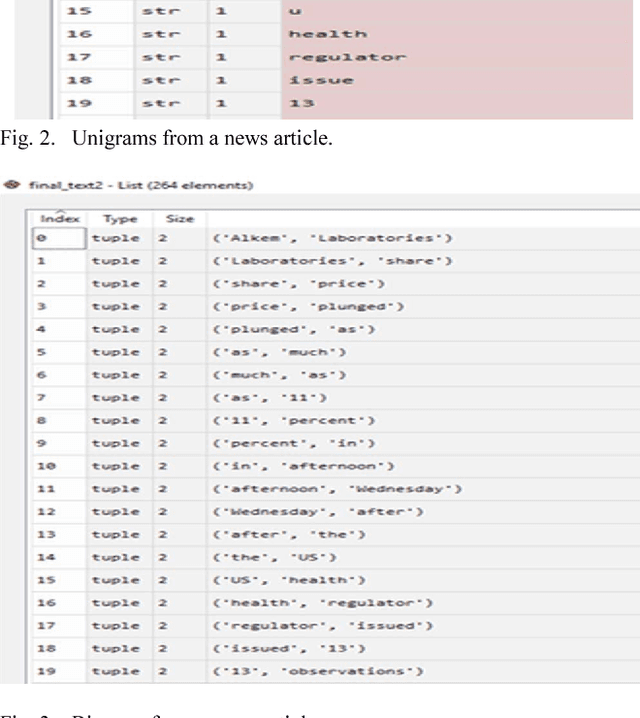
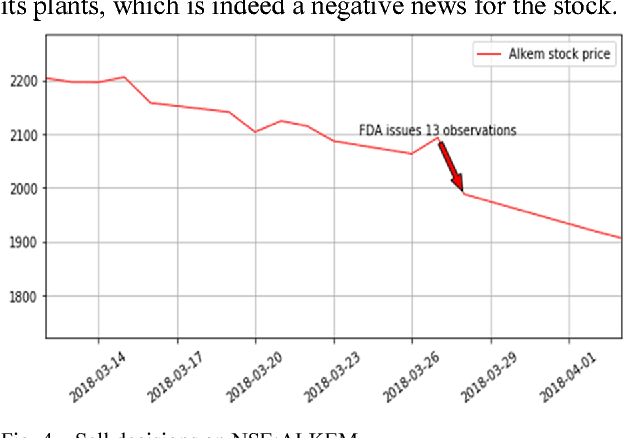
Stock market forecasting is very important in the planning of business activities. Stock price prediction has attracted many researchers in multiple disciplines including computer science, statistics, economics, finance, and operations research. Recent studies have shown that the vast amount of online information in the public domain such as Wikipedia usage pattern, news stories from the mainstream media, and social media discussions can have an observable effect on investors opinions towards financial markets. The reliability of the computational models on stock market prediction is important as it is very sensitive to the economy and can directly lead to financial loss. In this paper, we retrieved, extracted, and analyzed the effects of news sentiments on the stock market. Our main contributions include the development of a sentiment analysis dictionary for the financial sector, the development of a dictionary-based sentiment analysis model, and the evaluation of the model for gauging the effects of news sentiments on stocks for the pharmaceutical market. Using only news sentiments, we achieved a directional accuracy of 70.59% in predicting the trends in short-term stock price movement.