 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Cropped versus Uncropped Training Sets in Tabular Structure Detection
Oct 07, 2021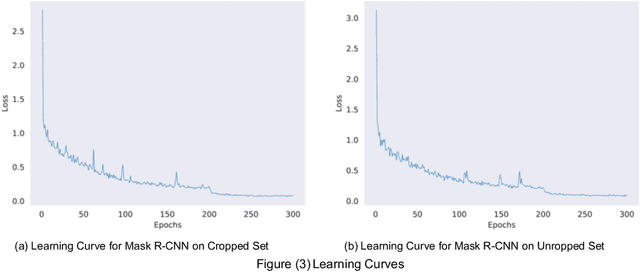
Automated document processing for tabular information extraction is highly desired in many organizations, from industry to government. Prior works have addressed this problem under table detection and table structure detection tasks. Proposed solutions leveraging deep learning approaches have been giving promising results in these tasks. However, the impact of dataset structures on table structure detection has not been investigated. In this study, we provide a comparison of table structure detection performance with cropped and uncropped datasets. The cropped set consists of only table images that are cropped from documents assuming tables are detected perfectly. The uncropped set consists of regular document images. Experiments show that deep learning models can improve the detection performance by up to 9% in average precision and average recall on the cropped versions. Furthermore, the impact of cropped images is negligible under the Intersection over Union (IoU) values of 50%-70% when compared to the uncropped versions. However, beyond 70% IoU thresholds, cropped datasets provide significantly higher detection performance.
A Scalable Framework for Multilevel Streaming Data Analytics using Deep Learning
Jul 15, 2019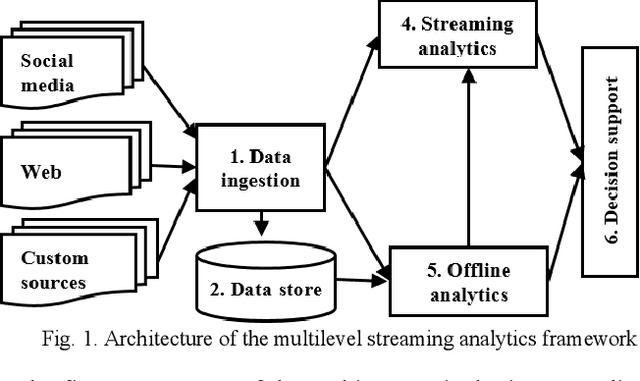
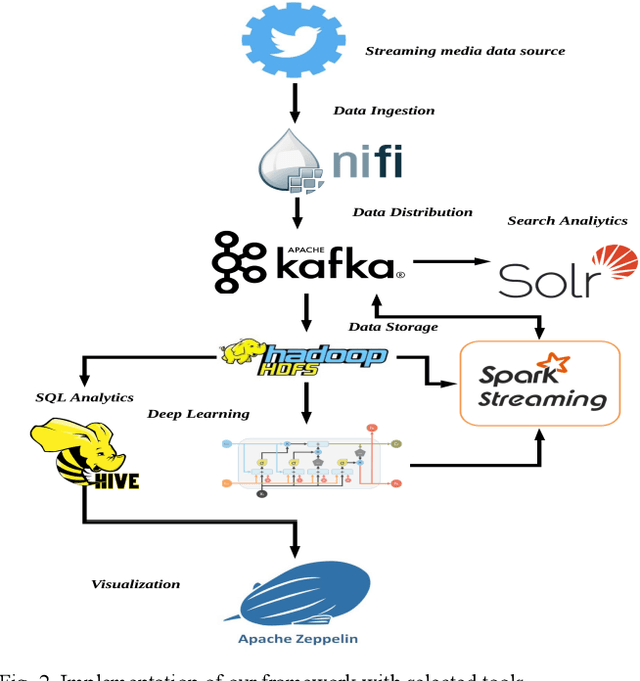
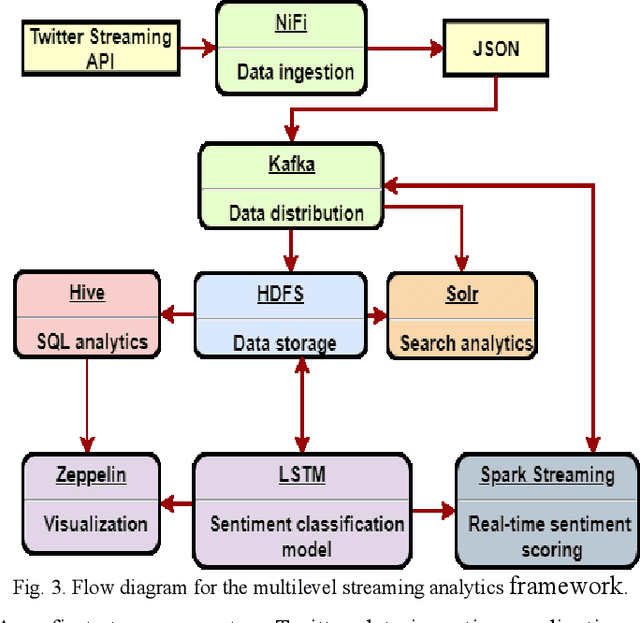
The rapid growth of data in velocity, volume, value, variety, and veracity has enabled exciting new opportunities and presented big challenges for businesses of all types. Recently, there has been considerable interest in developing systems for processing continuous data streams with the increasing need for real-time analytics for decision support in the business, healthcare, manufacturing, and security. The analytics of streaming data usually relies on the output of offline analytics on static or archived data. However, businesses and organizations like our industry partner Gnowit, strive to provide their customers with real time market information and continuously look for a unified analytics framework that can integrate both streaming and offline analytics in a seamless fashion to extract knowledge from large volumes of hybrid streaming data. We present our study on designing a multilevel streaming text data analytics framework by comparing leading edge scalable open-source, distributed, and in-memory technologies. We demonstrate the functionality of the framework for a use case of multilevel text analytics using deep learning for language understanding and sentiment analysis including data indexing and query processing. Our framework combines Spark streaming for real time text processing, the Long Short Term Memory (LSTM) deep learning model for higher level sentiment analysis, and other tools for SQL-based analytical processing to provide a scalable solution for multilevel streaming text analytics.