 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Modeling of Human-Machine Authentication Channels under Partial Information Leakage
May 03, 2026Reliable and secure human-machine communication is fundamental to IoT and cyber-physical ecosystems, where smartphones and wearables commonly serve as authentication controllers. PIN-based authentication can be viewed as a low-bandwidth communication channel through which users transmit numeric credentials under practical constraints. However, conventional evaluations adopt a binary view of security-treating such channels as either fully secure or fully compromised-thereby overlooking the progressive reliability degradation caused by partial information leakage in real-world IoT settings. In this paper, we model the PIN entry process as a stochastic human-IoT communication system and propose a context-conditioned probabilistic inference framework to quantify reliability loss and Quality-of-Service degradation under partial symbol exposure. The proposed approach treats missing digits as latent variables and estimates them using smoothed conditional probability distributions with fallback priors. Unlike traditional sequential models that assume contiguous positional dependencies, the method does not explicitly parameterize hidden-state transitions or emissions; instead, it performs context-driven probabilistic inference to approximate latent dependencies across digit positions. Using over one million real-world four-digit PIN samples, we evaluate single-, double-, and triple-digit leakage scenarios and derive position-dependent reliability metrics. The proposed model achieves up to 55.31% prediction accuracy for one missing digit and 12.12% for three missing digits, while consistently outperforming a standard sequence-model baseline and classical machine learning models in terms of precision, recall, and F1-score. These results formalize PIN entry as a noisy human--IoT communication channel and demonstrate substantial reliability degradation under realistic partial exposure conditions.
Toward Resilient 5G Networks: Comparative Analysis of Federated and Centralized Learning for RF Jamming Detection
May 03, 2026Jamming attacks are proliferating and pose a significant threat to the security of 5G and beyond networks. These attacks target 5G radio frequency (RF) domain and can disrupt the communication in wireless networks. While conventional machine learning and deep learning approaches demonstrate its potential for jamming detection, they typically require centralized data collection, compromising the privacy of user equipment (UEs). This work proposes a federated learning (FL)-based jamming detection framework that operates on over-the-air In-phase and Quadrature (IQ) samples extracted from Synchronization Signal Blocks (SSBs) in the RF domain. The framework enables collaborative model training across multiple UEs without sharing raw RF signal data. We adopt Federated Averaging (FedAvg) algorithm to train a 1D convolutional neural network (1DCNN) for effective detection of attacks. Numerical results demonstrate that the proposed FL framework achieves 97% accuracy and 97% F1-score, outperforming centralized baselines including MLP, 1DCNN, SVM, and logistic regression, while preserving the data privacy of all participating UEs
Proactive SFC Provisioning with Forecast-Driven DRL in Data Centers
Jan 28, 2026Service Function Chaining (SFC) requires efficient placement of Virtual Network Functions (VNFs) to satisfy diverse service requirements while maintaining high resource utilization in Data Centers (DCs). Conventional static resource allocation often leads to overprovisioning or underprovisioning due to the dynamic nature of traffic loads and application demands. To address this challenge, we propose a hybrid forecast-driven Deep reinforcement learning (DRL) framework that combines predictive intelligence with SFC provisioning. Specifically, we leverage DRL to generate datasets capturing DC resource utilization and service demands, which are then used to train deep learning forecasting models. Using Optuna-based hyperparameter optimization, the best-performing models, Spatio-Temporal Graph Neural Network, Temporal Graph Neural Network, and Long Short-Term Memory, are combined into an ensemble to enhance stability and accuracy. The ensemble predictions are integrated into the DC selection process, enabling proactive placement decisions that consider both current and future resource availability. Experimental results demonstrate that the proposed method not only sustains high acceptance ratios for resource-intensive services such as Cloud Gaming and VoIP but also significantly improves acceptance ratios for latency-critical categories such as Augmented Reality increases from 30% to 50%, while Industry 4.0 improves from 30% to 45%. Consequently, the prediction-based model achieves significantly lower E2E latencies of 20.5%, 23.8%, and 34.8% reductions for VoIP, Video Streaming, and Cloud Gaming, respectively. This strategy ensures more balanced resource allocation, and reduces contention.
Intent2QoS: Language Model-Driven Automation of Traffic Shaping Configurations
Jan 26, 2026Traffic shaping and Quality of Service (QoS) enforcement are critical for managing bandwidth, latency, and fairness in networks. These tasks often rely on low-level traffic control settings, which require manual setup and technical expertise. This paper presents an automated framework that converts high-level traffic shaping intents in natural or declarative language into valid and correct traffic control rules. To the best of our knowledge, we present the first end-to-end pipeline that ties intent translation in a queuing-theoretic semantic model and, with a rule-based critic, yields deployable Linux traffic control configuration sets. The framework has three steps: (1) a queuing simulation with priority scheduling and Active Queue Management (AQM) builds a semantic model; (2) a language model, using this semantic model and a traffic profile, generates sub-intents and configuration rules; and (3) a rule-based critic checks and adjusts the rules for correctness and policy compliance. We evaluate multiple language models by generating traffic control commands from business intents that comply with relevant standards for traffic control protocols. Experimental results on 100 intents show significant gains, with LLaMA3 reaching 0.88 semantic similarity and 0.87 semantic coverage, outperforming other models by over 30\. A thorough sensitivity study demonstrates that AQM-guided prompting reduces variability threefold compared to zero-shot baselines.
Structure-Aware NL-to-SQL for SFC Provisioning via AST-Masking Empowered Language Models
Jan 24, 2026Effective Service Function Chain (SFC) provisioning requires precise orchestration in dynamic and latency-sensitive networks. Reinforcement Learning (RL) improves adaptability but often ignores structured domain knowledge, which limits generalization and interpretability. Large Language Models (LLMs) address this gap by translating natural language (NL) specifications into executable Structured Query Language (SQL) commands for specification-driven SFC management. Conventional fine-tuning, however, can cause syntactic inconsistencies and produce inefficient queries. To overcome this, we introduce Abstract Syntax Tree (AST)-Masking, a structure-aware fine-tuning method that uses SQL ASTs to assign weights to key components and enforce syntax-aware learning without adding inference overhead. Experiments show that AST-Masking significantly improves SQL generation accuracy across multiple language models. FLAN-T5 reaches an Execution Accuracy (EA) of 99.6%, while Gemma achieves the largest absolute gain from 7.5% to 72.0%. These results confirm the effectiveness of structure-aware fine-tuning in ensuring syntactically correct and efficient SQL generation for interpretable SFC orchestration.
Spatiotemporal Semantic V2X Framework for Cooperative Collision Prediction
Jan 23, 2026Intelligent Transportation Systems (ITS) demand real-time collision prediction to ensure road safety and reduce accident severity. Conventional approaches rely on transmitting raw video or high-dimensional sensory data from roadside units (RSUs) to vehicles, which is impractical under vehicular communication bandwidth and latency constraints. In this work, we propose a semantic V2X framework in which RSU-mounted cameras generate spatiotemporal semantic embeddings of future frames using the Video Joint Embedding Predictive Architecture (V-JEPA). To evaluate the system, we construct a digital twin of an urban traffic environment enabling the generation of d verse traffic scenarios with both safe and collision events. These embeddings of the future frame, extracted from V-JEPA, capture task-relevant traffic dynamics and are transmitted via V2X links to vehicles, where a lightweight attentive probe and classifier decode them to predict imminent collisions. By transmitting only semantic embeddings instead of raw frames, the proposed system significantly reduces communication overhead while maintaining predictive accuracy. Experimental results demonstrate that the framework with an appropriate processing method achieves a 10% F1-score improvement for collision prediction while reducing transmission requirements by four orders of magnitude compared to raw video. This validates the potential of semantic V2X communication to enable cooperative, real-time collision prediction in ITS.
A Digital Twin Framework for Metamorphic Testing of Autonomous Driving Systems Using Generative Model
Oct 08, 2025Ensuring the safety of self-driving cars remains a major challenge due to the complexity and unpredictability of real-world driving environments. Traditional testing methods face significant limitations, such as the oracle problem, which makes it difficult to determine whether a system's behavior is correct, and the inability to cover the full range of scenarios an autonomous vehicle may encounter. In this paper, we introduce a digital twin-driven metamorphic testing framework that addresses these challenges by creating a virtual replica of the self-driving system and its operating environment. By combining digital twin technology with AI-based image generative models such as Stable Diffusion, our approach enables the systematic generation of realistic and diverse driving scenes. This includes variations in weather, road topology, and environmental features, all while maintaining the core semantics of the original scenario. The digital twin provides a synchronized simulation environment where changes can be tested in a controlled and repeatable manner. Within this environment, we define three metamorphic relations inspired by real-world traffic rules and vehicle behavior. We validate our framework in the Udacity self-driving simulator and demonstrate that it significantly enhances test coverage and effectiveness. Our method achieves the highest true positive rate (0.719), F1 score (0.689), and precision (0.662) compared to baseline approaches. This paper highlights the value of integrating digital twins with AI-powered scenario generation to create a scalable, automated, and high-fidelity testing solution for autonomous vehicle safety.
CWGAN-GP Augmented CAE for Jamming Detection in 5G-NR in Non-IID Datasets
Jun 18, 2025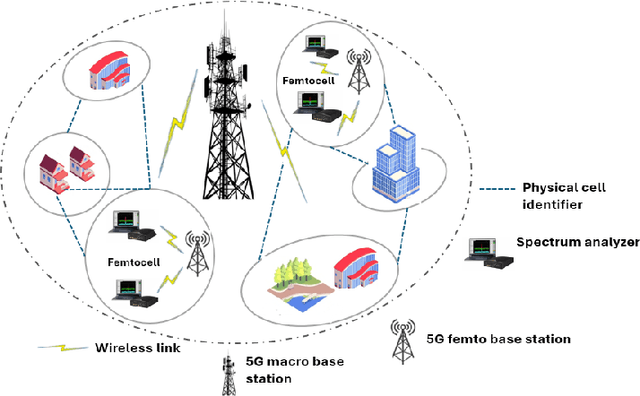
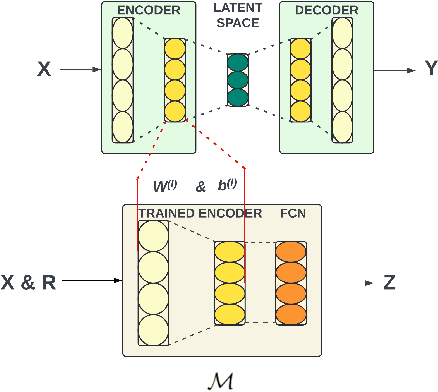

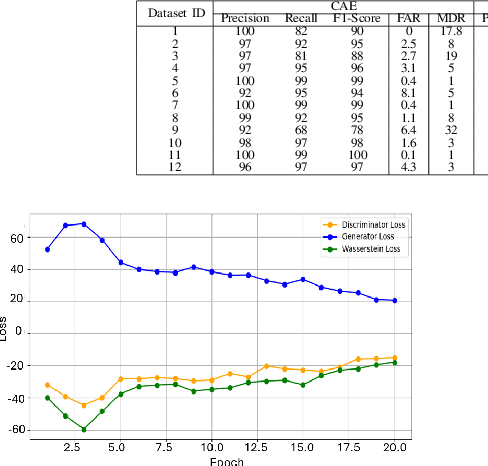
In the ever-expanding domain of 5G-NR wireless cellular networks, over-the-air jamming attacks are prevalent as security attacks, compromising the quality of the received signal. We simulate a jamming environment by incorporating additive white Gaussian noise (AWGN) into the real-world In-phase and Quadrature (I/Q) OFDM datasets. A Convolutional Autoencoder (CAE) is exploited to implement a jamming detection over various characteristics such as heterogenous I/Q datasets; extracting relevant information on Synchronization Signal Blocks (SSBs), and fewer SSB observations with notable class imbalance. Given the characteristics of datasets, balanced datasets are acquired by employing a Conv1D conditional Wasserstein Generative Adversarial Network-Gradient Penalty(CWGAN-GP) on both majority and minority SSB observations. Additionally, we compare the performance and detection ability of the proposed CAE model on augmented datasets with benchmark models: Convolutional Denoising Autoencoder (CDAE) and Convolutional Sparse Autoencoder (CSAE). Despite the complexity of data heterogeneity involved across all datasets, CAE depicts the robustness in detection performance of jammed signal by achieving average values of 97.33% precision, 91.33% recall, 94.08% F1-score, and 94.35% accuracy over CDAE and CSAE.
Partitioned Task Offloading for Low-Latency and Reliable Task Completion in 5G MEC
Mar 25, 2025The demand for MEC has increased with the rise of data-intensive applications and 5G networks, while conventional cloud models struggle to satisfy low-latency requirements. While task offloading is crucial for minimizing latency on resource-constrained User Equipment (UE), fully offloading of all tasks to MEC servers may result in overload and possible task drops. Overlooking the effect of number of dropped tasks can significantly undermine system efficiency, as each dropped task results in unfulfilled service demands and reduced reliability, directly impacting user experience and overall network performance. In this paper, we employ task partitioning, enabling partitions of task to be processed locally while assigning the rest to MEC, thus balancing the load and ensuring no task drops. This methodology enhances efficiency via Mixed Integer Linear Programming (MILP) and Cuckoo Search, resulting in effective task assignment and minimum latency. Moreover, we ensure each user's RB allocation stays within the maximum limit while keeping latency low. Experimental results indicate that this strategy surpasses both full offloading and full local processing, providing significant improvements in latency and task completion rates across diverse number of users. In our scenario, MILP task partitioning results in 24% reduction in latency compared to MILP task offloading for the maximum number of users, whereas Cuckoo search task partitioning yields 18% latency reduction in comparison with Cuckoo search task offloading.
A Two-Stage CAE-Based Federated Learning Framework for Efficient Jamming Detection in 5G Networks
Jan 25, 2025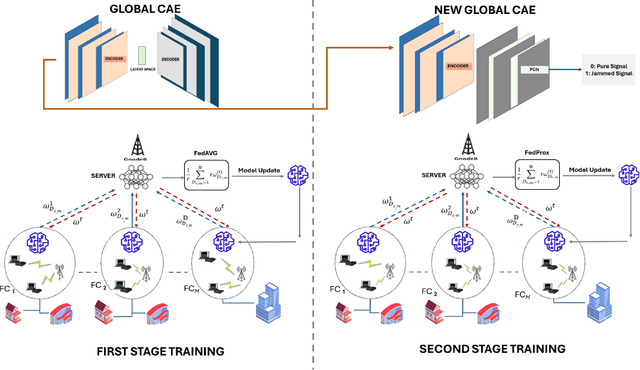
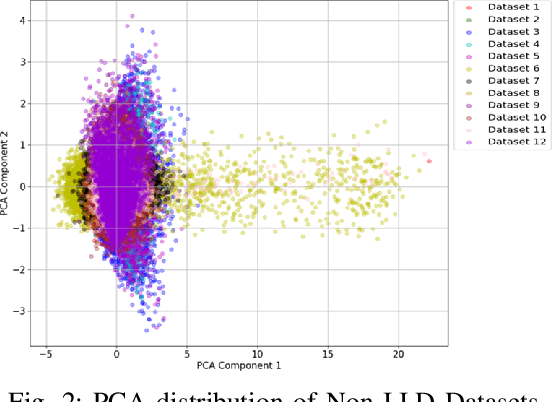
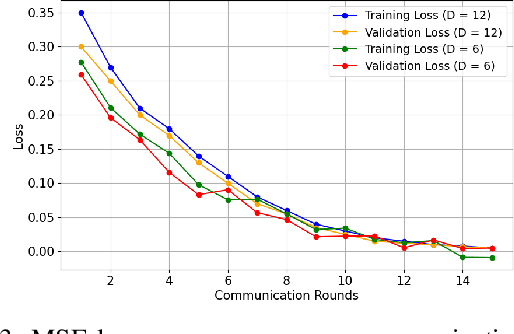
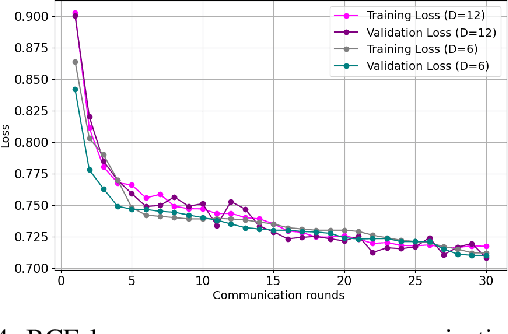
Cyber-security for 5G networks is drawing notable attention due to an increase in complex jamming attacks that could target the critical 5G Radio Frequency (RF) domain. These attacks pose a significant risk to heterogeneous network (HetNet) architectures, leading to degradation in network performance. Conventional machine-learning techniques for jamming detection rely on centralized training while increasing the odds of data privacy. To address these challenges, this paper proposes a decentralized two-stage federated learning (FL) framework for jamming detection in 5G femtocells. Our proposed distributed framework encompasses using the Federated Averaging (FedAVG) algorithm to train a Convolutional Autoencoder (CAE) for unsupervised learning. In the second stage, we use a fully connected network (FCN) built on the pre-trained CAE encoder that is trained using Federated Proximal (FedProx) algorithm to perform supervised classification. Our experimental results depict that our proposed framework (FedAVG and FedProx) accomplishes efficient training and prediction across non-IID client datasets without compromising data privacy. Specifically, our framework achieves a precision of 0.94, recall of 0.90, F1-score of 0.92, and an accuracy of 0.92, while minimizing communication rounds to 30 and achieving robust convergence in detecting jammed signals with an optimal client count of 6.