 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransmit or Idle: Efficient AoI Optimal Transmission Policy for Gossiping Receivers
Feb 12, 2026We study the optimal transmission and scheduling policy for a transmitter (source) communicating with two gossiping receivers aiming at tracking the source's status over time using the age of information (AoI) metric. Gossiping enables local information exchange in a decentralized manner without relying solely on the transmitter's direct communication, which we assume incurs a transmission cost. On the other hand, gossiping may be communicating stale information, necessitating the transmitter's intervention. With communication links having specific success probabilities, we formulate an average-cost Markov Decision Process (MDP) to jointly minimize the sum AoI and transmission cost for such a system in a time-slotted setting. We employ the Relative Value Iteration (RVI) algorithm to evaluate the optimal policy for the transmitter and then prove several structural properties showing that it has an age-difference threshold structure with minimum age activation in the case where gossiping is relatively more reliable. Specifically, direct transmission is optimal only if the minimum AoI of the receivers is large enough and their age difference is below a certain threshold. Otherwise, the transmitter idles to effectively take advantage of gossiping and reduce direct transmission costs. Numerical evaluations demonstrate the significance of our optimal policy compared to multiple baselines. Our result is a first step towards characterizing optimal freshness and transmission cost trade-offs in gossiping networks.
Version Age of Information with Contact Mobility in Gossip Networks
Sep 18, 2025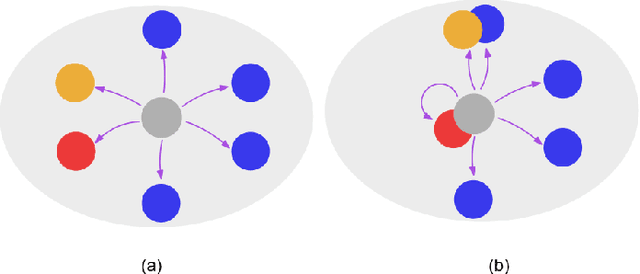



A gossip network is considered in which a source node updates its status while other nodes in the network aim at keeping track of it as it varies over time. Information gets disseminated by the source sending status updates to the nodes, and the nodes gossiping with each other. In addition, the nodes in the network are mobile, and can move to other nodes to get information, which we term contact mobility. The goal for the nodes is to remain as fresh as possible, i.e., to have the same information as the source's. To evaluate the freshness of information, we use the Version Age-of-Information (VAoI) metric, defined as the difference between the version of information available at a given node and that at the source. We analyze the effect of contact mobility on information dissemination in the gossip network using a Stochastic Hybrid System (SHS) framework for different topologies and mobility scalings with increasing number of nodes. It is shown that with the presence of contact mobility the freshness of the network improves in both ends of the network connectivity spectrum: disconnected and fully connected gossip networks. We mathematically analyze the average version age scalings and validate our theoretical results via simulations. Finally, we incorporate the cost of mobility for the network by formulating and solving an optimization problem that minimizes a weighted sum of version age and mobility cost. Our results show that contact mobility, with optimized mobility cost, improves the average version age in the network.
Adversarial Machine Learning-Enabled Anonymization of OpenWiFi Data
Jan 03, 2024Data privacy and protection through anonymization is a critical issue for network operators or data owners before it is forwarded for other possible use of data. With the adoption of Artificial Intelligence (AI), data anonymization augments the likelihood of covering up necessary sensitive information; preventing data leakage and information loss. OpenWiFi networks are vulnerable to any adversary who is trying to gain access or knowledge on traffic regardless of the knowledge possessed by data owners. The odds for discovery of actual traffic information is addressed by applied conditional tabular generative adversarial network (CTGAN). CTGAN yields synthetic data; which disguises as actual data but fostering hidden acute information of actual data. In this paper, the similarity assessment of synthetic with actual data is showcased in terms of clustering algorithms followed by a comparison of performance for unsupervised cluster validation metrics. A well-known algorithm, K-means outperforms other algorithms in terms of similarity assessment of synthetic data over real data while achieving nearest scores 0.634, 23714.57, and 0.598 as Silhouette, Calinski and Harabasz and Davies Bouldin metric respectively. On exploiting a comparative analysis in validation scores among several algorithms, K-means forms the epitome of unsupervised clustering algorithms ensuring explicit usage of synthetic data at the same time a replacement for real data. Hence, the experimental results aim to show the viability of using CTGAN-generated synthetic data in lieu of publishing anonymized data to be utilized in various applications.
Data-Efficient Training of CNNs and Transformers with Coresets: A Stability Perspective
Mar 10, 2023



Coreset selection is among the most effective ways to reduce the training time of CNNs, however, only limited is known on how the resultant models will behave under variations of the coreset size, and choice of datasets and models. Moreover, given the recent paradigm shift towards transformer-based models, it is still an open question how coreset selection would impact their performance. There are several similar intriguing questions that need to be answered for a wide acceptance of coreset selection methods, and this paper attempts to answer some of these. We present a systematic benchmarking setup and perform a rigorous comparison of different coreset selection methods on CNNs and transformers. Our investigation reveals that under certain circumstances, random selection of subsets is more robust and stable when compared with the SOTA selection methods. We demonstrate that the conventional concept of uniform subset sampling across the various classes of the data is not the appropriate choice. Rather samples should be adaptively chosen based on the complexity of the data distribution for each class. Transformers are generally pretrained on large datasets, and we show that for certain target datasets, it helps to keep their performance stable at even very small coreset sizes. We further show that when no pretraining is done or when the pretrained transformer models are used with non-natural images (e.g. medical data), CNNs tend to generalize better than transformers at even very small coreset sizes. Lastly, we demonstrate that in the absence of the right pretraining, CNNs are better at learning the semantic coherence between spatially distant objects within an image, and these tend to outperform transformers at almost all choices of the coreset size.
Under the Hood of Transformer Networks for Trajectory Forecasting
Mar 22, 2022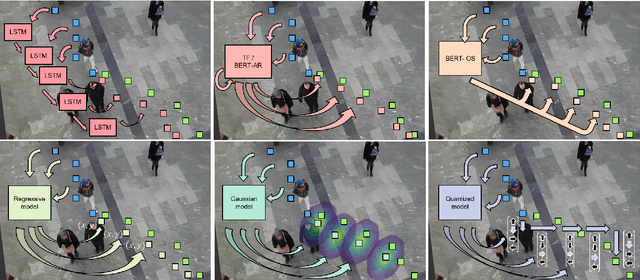
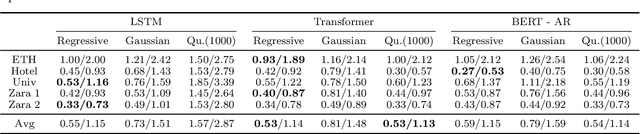
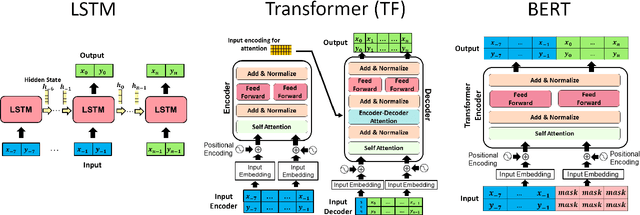
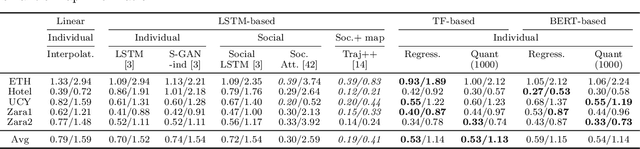
Transformer Networks have established themselves as the de-facto state-of-the-art for trajectory forecasting but there is currently no systematic study on their capability to model the motion patterns of people, without interactions with other individuals nor the social context. This paper proposes the first in-depth study of Transformer Networks (TF) and Bidirectional Transformers (BERT) for the forecasting of the individual motion of people, without bells and whistles. We conduct an exhaustive evaluation of input/output representations, problem formulations and sequence modeling, including a novel analysis of their capability to predict multi-modal futures. Out of comparative evaluation on the ETH+UCY benchmark, both TF and BERT are top performers in predicting individual motions, definitely overcoming RNNs and LSTMs. Furthermore, they remain within a narrow margin wrt more complex techniques, which include both social interactions and scene contexts. Source code will be released for all conducted experiments.
Pedestrian Detection: Domain Generalization, CNNs, Transformers and Beyond
Jan 10, 2022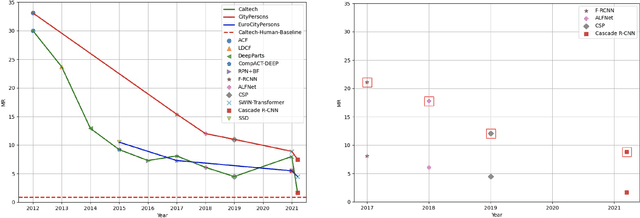
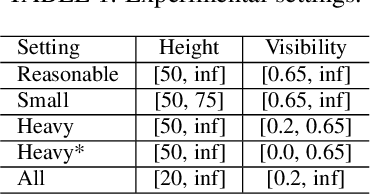


Pedestrian detection is the cornerstone of many vision based applications, starting from object tracking to video surveillance and more recently, autonomous driving. With the rapid development of deep learning in object detection, pedestrian detection has achieved very good performance in traditional single-dataset training and evaluation setting. However, in this study on generalizable pedestrian detectors, we show that, current pedestrian detectors poorly handle even small domain shifts in cross-dataset evaluation. We attribute the limited generalization to two main factors, the method and the current sources of data. Regarding the method, we illustrate that biasness present in the design choices (e.g anchor settings) of current pedestrian detectors are the main contributing factor to the limited generalization. Most modern pedestrian detectors are tailored towards target dataset, where they do achieve high performance in traditional single training and testing pipeline, but suffer a degrade in performance when evaluated through cross-dataset evaluation. Consequently, a general object detector performs better in cross-dataset evaluation compared with state of the art pedestrian detectors, due to its generic design. As for the data, we show that the autonomous driving benchmarks are monotonous in nature, that is, they are not diverse in scenarios and dense in pedestrians. Therefore, benchmarks curated by crawling the web (which contain diverse and dense scenarios), are an efficient source of pre-training for providing a more robust representation. Accordingly, we propose a progressive fine-tuning strategy which improves generalization. Code and models cab accessed at https://github.com/hasanirtiza/Pedestron.
An integrated light management system with real-time light measurement and human perception
Apr 17, 2020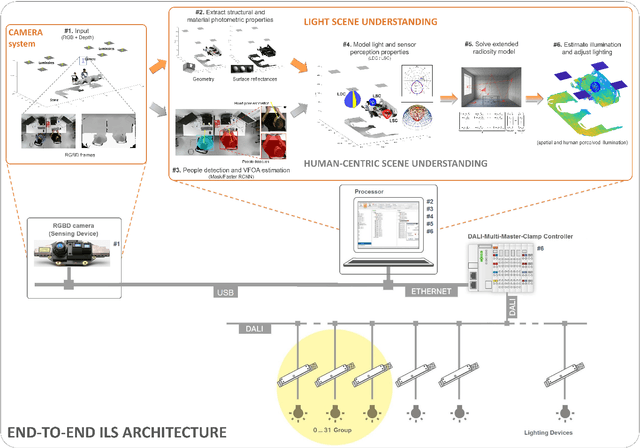
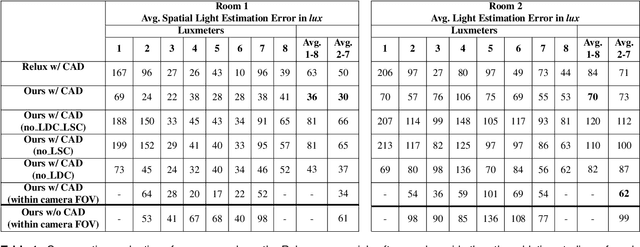

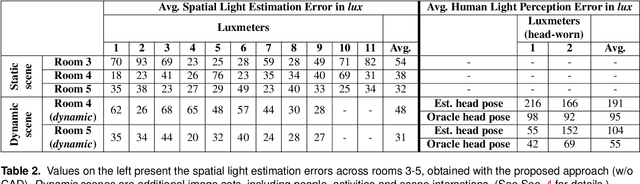
Illumination is important for well-being, productivity and safety across several environments, including offices, retail shops and industrial warehouses. Current techniques for setting up lighting require extensive and expert support and need to be repeated if the scene changes. Here we propose the first fully-automated light management system (LMS) which measures lighting in real-time, leveraging an RGBD sensor and a radiosity-based light propagation model. Thanks to the integration of light distribution and perception curves into the radiosity, we outperform a commercial software (Relux) on a newly introduced dataset. Furthermore, our proposed LMS is the first to estimate both the presence and the attention of the people in the environment, as well as their light perception. Our new LMS adapts therefore lighting to the scene and human activity and it is capable of saving up to 66%, as we experimentally quantify,without compromising the lighting quality.
Pedestrian Detection: The Elephant In The Room
Mar 22, 2020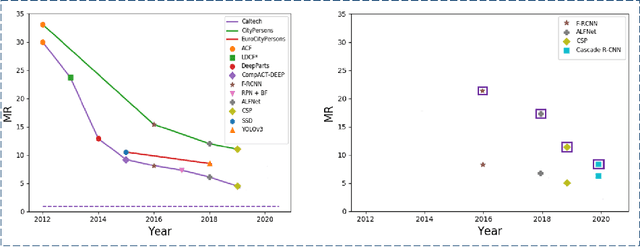
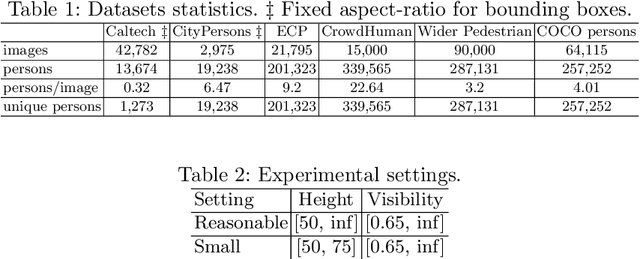

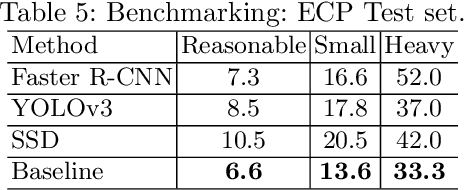
Pedestrian detection is used in many vision based applications ranging from video surveillance to autonomous driving. Despite achieving high performance, it is still largely unknown how well existing detectors generalize to unseen data. To this end, we conduct a comprehensive study in this paper, using a general principle of direct cross-dataset evaluation. Through this study, we find that existing state-of-the-art pedestrian detectors generalize poorly from one dataset to another. We demonstrate that there are two reasons for this trend. Firstly, they over-fit on popular datasets in a traditional single-dataset training and test pipeline. Secondly, the training source is generally not dense in pedestrians and diverse in scenarios. Accordingly, through experiments we find that a general purpose object detector works better in direct cross-dataset evaluation compared with state-of-the-art pedestrian detectors and we illustrate that diverse and dense datasets, collected by crawling the web, serve to be an efficient source of pre-training for pedestrian detection. Furthermore, we find that a progressive training pipeline works good for autonomous driving oriented detector. We improve upon previous state-of-the-art on reasonable/heavy subsets of CityPersons dataset by 1.3%/1.7% and on Caltech by 1.8%/14.9% in terms of log average miss rate (MR^2) points without any fine-tuning on the test set. Detector trained through proposed pipeline achieves top rank at the leaderborads of CityPersons [42] and ECP [4]. Code and models will be available at https://github.com/hasanirtiza/Pedestron.
Transformer Networks for Trajectory Forecasting
Mar 18, 2020
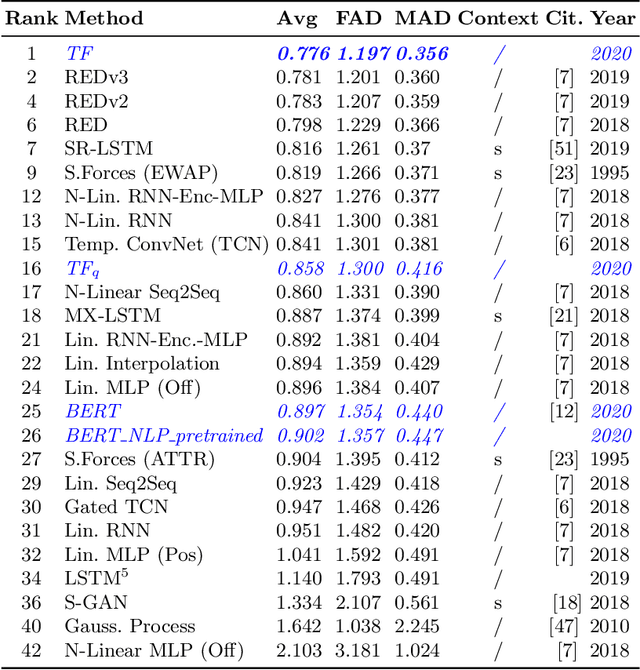
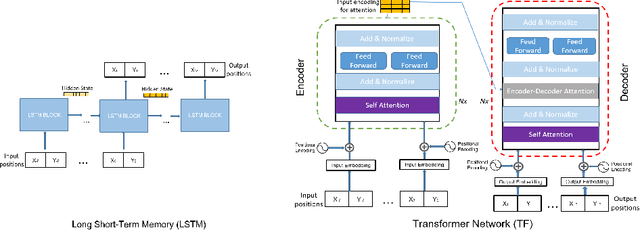
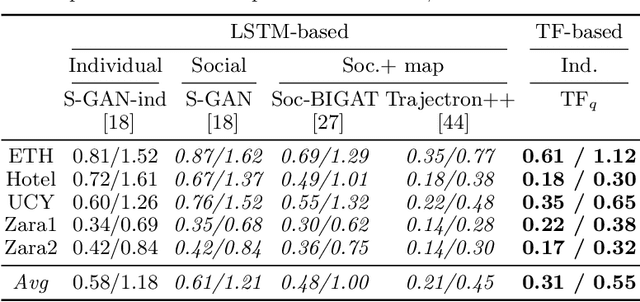
Most recent successes on forecasting the people motion are based on LSTM models and all most recent progress has been achieved by modelling the social interaction among people and the people interaction with the scene. We question the use of the LSTM models and propose the novel use of Transformer Networks for trajectory forecasting. This is a fundamental switch from the sequential step-by-step processing of LSTMs to the only-attention-based memory mechanisms of Transformers. In particular, we consider both the original Transformer Network (TF) and the larger Bidirectional Transformer (BERT), state-of-the-art on all natural language processing tasks. Our proposed Transformers predict the trajectories of the individual people in the scene. These are \simple" model because each person is modelled separately without any complex human-human nor scene interaction terms. In particular, the TF model without bells and whistles yields the best score on the largest and most challenging trajectory forecasting benchmark of TrajNet. Additionally, its extension which predicts multiple plausible future trajectories performs on par with more engineered techniques on the 5 datasets of ETH+UCY. Finally, we show that Transformers may deal with missing observations, as it may be the case with real sensor data.
Human-centric light sensing and estimation from RGBD images: The invisible light switch
Jan 30, 2019
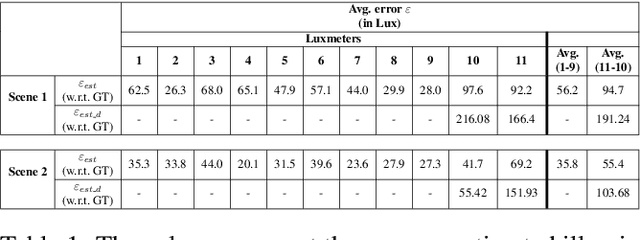
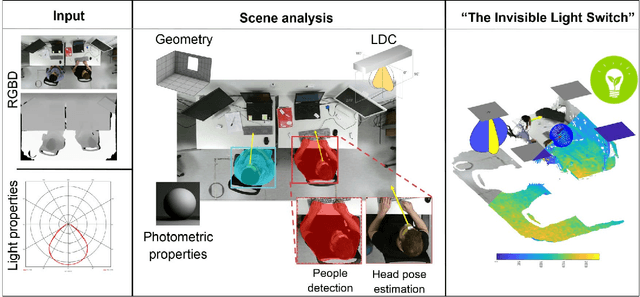
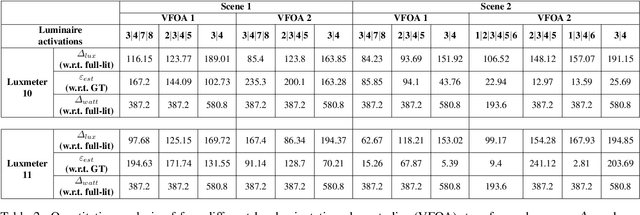
Lighting design in indoor environments is of primary importance for at least two reasons: 1) people should perceive an adequate light; 2) an effective lighting design means consistent energy saving. We present the Invisible Light Switch (ILS) to address both aspects. ILS dynamically adjusts the room illumination level to save energy while maintaining constant the light level perception of the users. So the energy saving is invisible to them. Our proposed ILS leverages a radiosity model to estimate the light level which is perceived by a person within an indoor environment, taking into account the person position and her/his viewing frustum (head pose). ILS may therefore dim those luminaires, which are not seen by the user, resulting in an effective energy saving, especially in large open offices (where light may otherwise be ON everywhere for a single person). To quantify the system performance, we have collected a new dataset where people wear luxmeter devices while working in office rooms. The luxmeters measure the amount of light (in Lux) reaching the people gaze, which we consider a proxy to their illumination level perception. Our initial results are promising: in a room with 8 LED luminaires, the energy consumption in a day may be reduced from 18585 to 6206 watts with ILS (currently needing 1560 watts for operations). While doing so, the drop in perceived lighting decreases by just 200 lux, a value considered negligible when the original illumination level is above 1200 lux, as is normally the case in offices.