 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer Networks for Trajectory Forecasting
Paper and Code

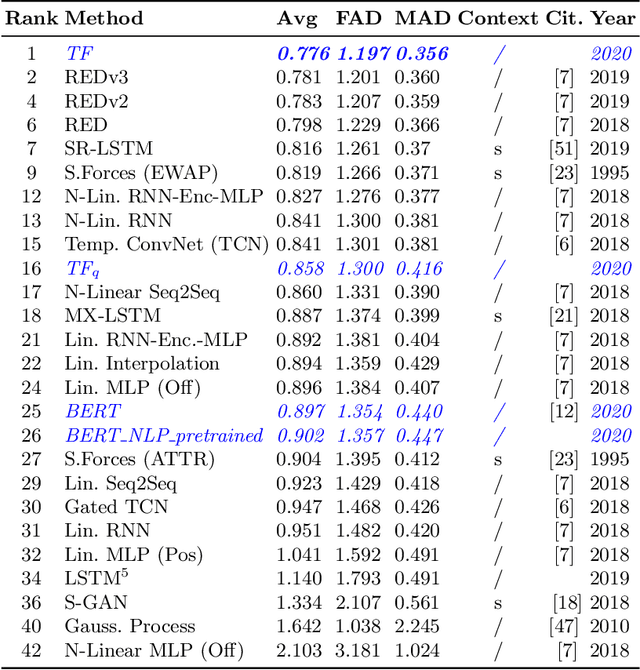
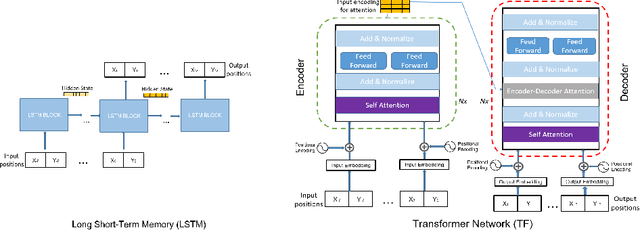
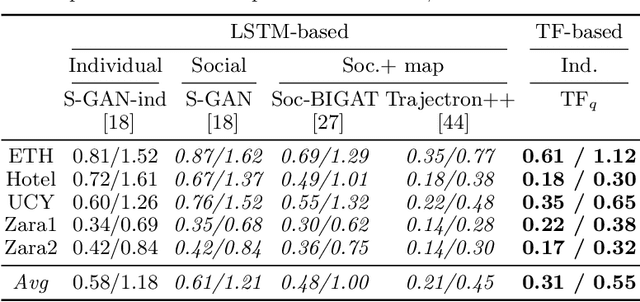
Most recent successes on forecasting the people motion are based on LSTM models and all most recent progress has been achieved by modelling the social interaction among people and the people interaction with the scene. We question the use of the LSTM models and propose the novel use of Transformer Networks for trajectory forecasting. This is a fundamental switch from the sequential step-by-step processing of LSTMs to the only-attention-based memory mechanisms of Transformers. In particular, we consider both the original Transformer Network (TF) and the larger Bidirectional Transformer (BERT), state-of-the-art on all natural language processing tasks. Our proposed Transformers predict the trajectories of the individual people in the scene. These are \simple" model because each person is modelled separately without any complex human-human nor scene interaction terms. In particular, the TF model without bells and whistles yields the best score on the largest and most challenging trajectory forecasting benchmark of TrajNet. Additionally, its extension which predicts multiple plausible future trajectories performs on par with more engineered techniques on the 5 datasets of ETH+UCY. Finally, we show that Transformers may deal with missing observations, as it may be the case with real sensor data.