 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCWGAN-GP Augmented CAE for Jamming Detection in 5G-NR in Non-IID Datasets
Jun 18, 2025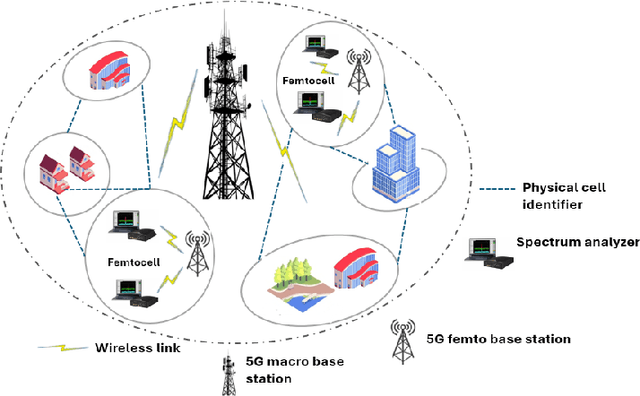

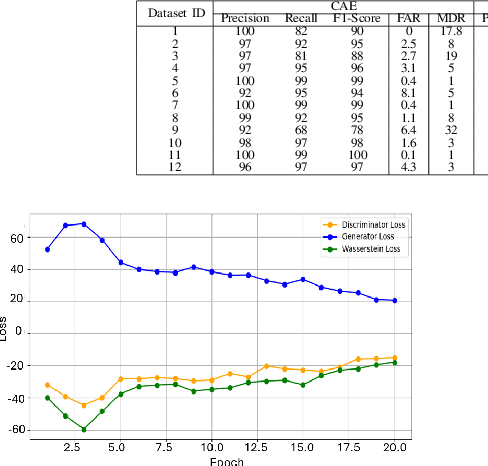
In the ever-expanding domain of 5G-NR wireless cellular networks, over-the-air jamming attacks are prevalent as security attacks, compromising the quality of the received signal. We simulate a jamming environment by incorporating additive white Gaussian noise (AWGN) into the real-world In-phase and Quadrature (I/Q) OFDM datasets. A Convolutional Autoencoder (CAE) is exploited to implement a jamming detection over various characteristics such as heterogenous I/Q datasets; extracting relevant information on Synchronization Signal Blocks (SSBs), and fewer SSB observations with notable class imbalance. Given the characteristics of datasets, balanced datasets are acquired by employing a Conv1D conditional Wasserstein Generative Adversarial Network-Gradient Penalty(CWGAN-GP) on both majority and minority SSB observations. Additionally, we compare the performance and detection ability of the proposed CAE model on augmented datasets with benchmark models: Convolutional Denoising Autoencoder (CDAE) and Convolutional Sparse Autoencoder (CSAE). Despite the complexity of data heterogeneity involved across all datasets, CAE depicts the robustness in detection performance of jammed signal by achieving average values of 97.33% precision, 91.33% recall, 94.08% F1-score, and 94.35% accuracy over CDAE and CSAE.
A Two-Stage CAE-Based Federated Learning Framework for Efficient Jamming Detection in 5G Networks
Jan 25, 2025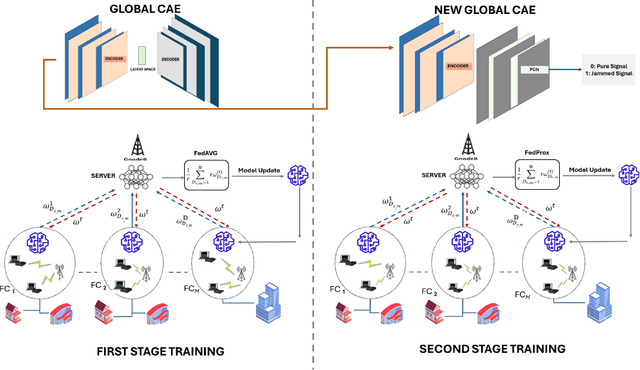
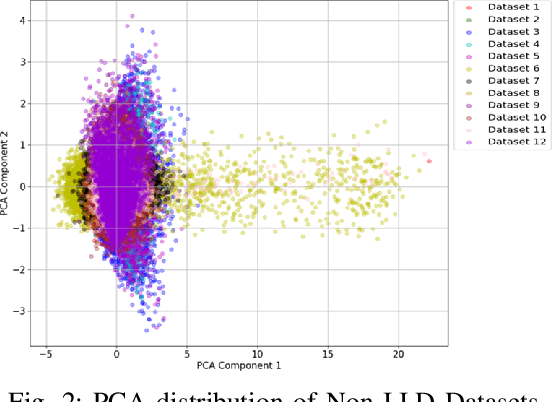
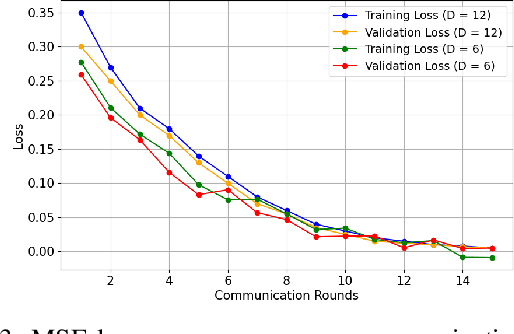
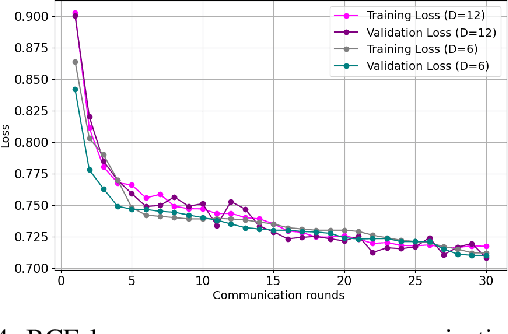
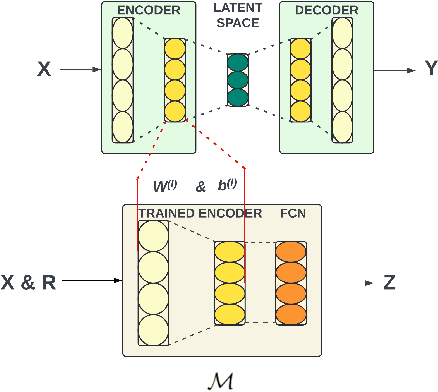
Cyber-security for 5G networks is drawing notable attention due to an increase in complex jamming attacks that could target the critical 5G Radio Frequency (RF) domain. These attacks pose a significant risk to heterogeneous network (HetNet) architectures, leading to degradation in network performance. Conventional machine-learning techniques for jamming detection rely on centralized training while increasing the odds of data privacy. To address these challenges, this paper proposes a decentralized two-stage federated learning (FL) framework for jamming detection in 5G femtocells. Our proposed distributed framework encompasses using the Federated Averaging (FedAVG) algorithm to train a Convolutional Autoencoder (CAE) for unsupervised learning. In the second stage, we use a fully connected network (FCN) built on the pre-trained CAE encoder that is trained using Federated Proximal (FedProx) algorithm to perform supervised classification. Our experimental results depict that our proposed framework (FedAVG and FedProx) accomplishes efficient training and prediction across non-IID client datasets without compromising data privacy. Specifically, our framework achieves a precision of 0.94, recall of 0.90, F1-score of 0.92, and an accuracy of 0.92, while minimizing communication rounds to 30 and achieving robust convergence in detecting jammed signals with an optimal client count of 6.
Adversarial Machine Learning-Enabled Anonymization of OpenWiFi Data
Jan 03, 2024Data privacy and protection through anonymization is a critical issue for network operators or data owners before it is forwarded for other possible use of data. With the adoption of Artificial Intelligence (AI), data anonymization augments the likelihood of covering up necessary sensitive information; preventing data leakage and information loss. OpenWiFi networks are vulnerable to any adversary who is trying to gain access or knowledge on traffic regardless of the knowledge possessed by data owners. The odds for discovery of actual traffic information is addressed by applied conditional tabular generative adversarial network (CTGAN). CTGAN yields synthetic data; which disguises as actual data but fostering hidden acute information of actual data. In this paper, the similarity assessment of synthetic with actual data is showcased in terms of clustering algorithms followed by a comparison of performance for unsupervised cluster validation metrics. A well-known algorithm, K-means outperforms other algorithms in terms of similarity assessment of synthetic data over real data while achieving nearest scores 0.634, 23714.57, and 0.598 as Silhouette, Calinski and Harabasz and Davies Bouldin metric respectively. On exploiting a comparative analysis in validation scores among several algorithms, K-means forms the epitome of unsupervised clustering algorithms ensuring explicit usage of synthetic data at the same time a replacement for real data. Hence, the experimental results aim to show the viability of using CTGAN-generated synthetic data in lieu of publishing anonymized data to be utilized in various applications.