 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePedestrian Detection: Domain Generalization, CNNs, Transformers and Beyond
Paper and Code
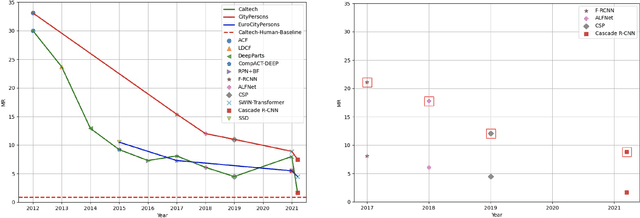


Pedestrian detection is the cornerstone of many vision based applications, starting from object tracking to video surveillance and more recently, autonomous driving. With the rapid development of deep learning in object detection, pedestrian detection has achieved very good performance in traditional single-dataset training and evaluation setting. However, in this study on generalizable pedestrian detectors, we show that, current pedestrian detectors poorly handle even small domain shifts in cross-dataset evaluation. We attribute the limited generalization to two main factors, the method and the current sources of data. Regarding the method, we illustrate that biasness present in the design choices (e.g anchor settings) of current pedestrian detectors are the main contributing factor to the limited generalization. Most modern pedestrian detectors are tailored towards target dataset, where they do achieve high performance in traditional single training and testing pipeline, but suffer a degrade in performance when evaluated through cross-dataset evaluation. Consequently, a general object detector performs better in cross-dataset evaluation compared with state of the art pedestrian detectors, due to its generic design. As for the data, we show that the autonomous driving benchmarks are monotonous in nature, that is, they are not diverse in scenarios and dense in pedestrians. Therefore, benchmarks curated by crawling the web (which contain diverse and dense scenarios), are an efficient source of pre-training for providing a more robust representation. Accordingly, we propose a progressive fine-tuning strategy which improves generalization. Code and models cab accessed at https://github.com/hasanirtiza/Pedestron.