 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
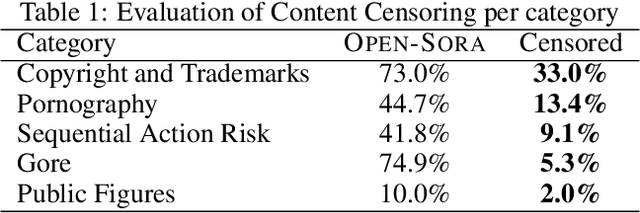
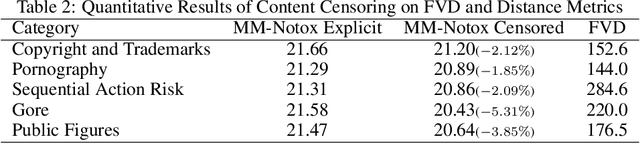

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
LongCodeBench: Evaluating Coding LLMs at 1M Context Windows
May 12, 2025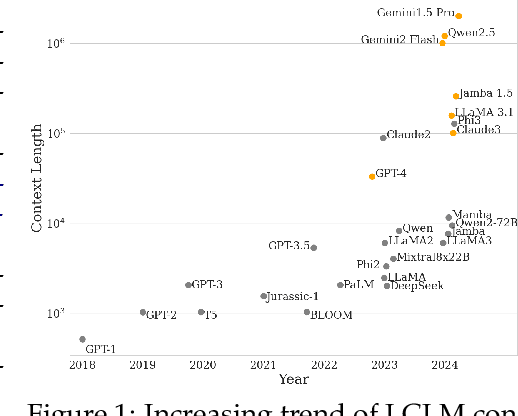
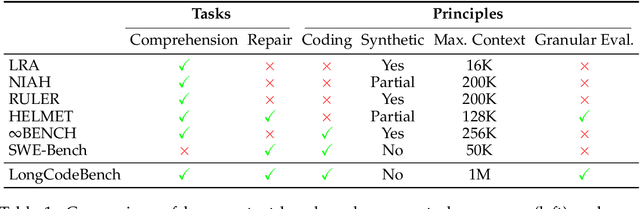
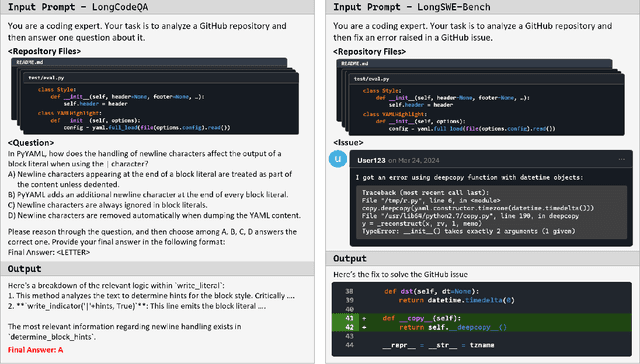
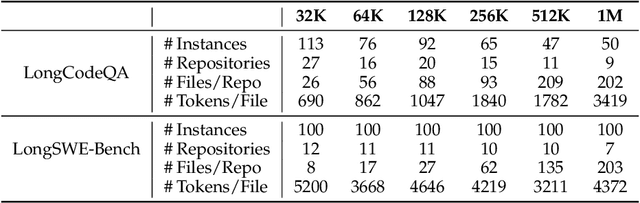
Context lengths for models have grown rapidly, from thousands to millions of tokens in just a few years. The extreme context sizes of modern long-context models have made it difficult to construct realistic long-context benchmarks -- not only due to the cost of collecting million-context tasks but also in identifying realistic scenarios that require significant contexts. We identify code comprehension and repair as a natural testbed and challenge task for long-context models and introduce LongCodeBench (LCB), a benchmark to test LLM coding abilities in long-context scenarios. Our benchmark tests both the comprehension and repair capabilities of LCLMs in realistic and important settings by drawing from real-world GitHub issues and constructing QA (LongCodeQA) and bug fixing (LongSWE-Bench) tasks. We carefully stratify the complexity of our benchmark, enabling us to evaluate models across different scales -- ranging from Qwen2.5 14B Instruct to Google's flagship Gemini model. We find that long-context remains a weakness for all models, with performance drops such as from 29% to 3% for Claude 3.5 Sonnet, or from 70.2% to 40% for Qwen2.5.
SeRpEnt: Selective Resampling for Expressive State Space Models
Jan 20, 2025



State Space Models (SSMs) have recently enjoyed a rise to prominence in the field of deep learning for sequence modeling, especially as an alternative to Transformers. Their success stems from avoiding two well-known drawbacks of attention-based models: quadratic complexity with respect to the sequence length and inability to model long-range dependencies. The SSM variant Mamba has demonstrated performance comparable to Transformers without any form of attention, thanks to the use of a selective mechanism for the state parameters. Selectivity, however, is only evaluated empirically and the reasons of its effectiveness remain unclear. In this work, we show how selectivity is related to the sequence processing. Our analysis shows that selective time intervals in Mamba act as linear approximators of information. Then, we propose our SeRpEnt architecture, a SSM that further exploits selectivity to compress sequences in an information-aware fashion. It employs a resampling mechanism that aggregates elements based on their information content. Our empirical results in the Long Range Arena benchmark and other language modeling tasks show benefits of the SeRpEnt's resampling mechanism.
Hyperbolic Learning with Multimodal Large Language Models
Aug 09, 2024Hyperbolic embeddings have demonstrated their effectiveness in capturing measures of uncertainty and hierarchical relationships across various deep-learning tasks, including image segmentation and active learning. However, their application in modern vision-language models (VLMs) has been limited. A notable exception is MERU, which leverages the hierarchical properties of hyperbolic space in the CLIP ViT-large model, consisting of hundreds of millions parameters. In our work, we address the challenges of scaling multi-modal hyperbolic models by orders of magnitude in terms of parameters (billions) and training complexity using the BLIP-2 architecture. Although hyperbolic embeddings offer potential insights into uncertainty not present in Euclidean embeddings, our analysis reveals that scaling these models is particularly difficult. We propose a novel training strategy for a hyperbolic version of BLIP-2, which allows to achieve comparable performance to its Euclidean counterpart, while maintaining stability throughout the training process and showing a meaningful indication of uncertainty with each embedding.
Hyperbolic Active Learning for Semantic Segmentation under Domain Shift
Jun 26, 2023For the task of semantic segmentation (SS) under domain shift, active learning (AL) acquisition strategies based on image regions and pseudo labels are state-of-the-art (SoA). The presence of diverse pseudo-labels within a region identifies pixels between different classes, which is a labeling efficient active learning data acquisition strategy. However, by design, pseudo-label variations are limited to only select the contours of classes, limiting the final AL performance. We approach AL for SS in the Poincar\'e hyperbolic ball model for the first time and leverage the variations of the radii of pixel embeddings within regions as a novel data acquisition strategy. This stems from a novel geometric property of a hyperbolic space trained without enforced hierarchies, which we experimentally prove. Namely, classes are mapped into compact hyperbolic areas with a comparable intra-class radii variance, as the model places classes of increasing explainable difficulty at denser hyperbolic areas, i.e. closer to the Poincar\'e ball edge. The variation of pixel embedding radii identifies well the class contours, but they also select a few intra-class peculiar details, which boosts the final performance. Our proposed HALO (Hyperbolic Active Learning Optimization) surpasses the supervised learning performance for the first time in AL for SS under domain shift, by only using a small portion of labels (i.e., 1%). The extensive experimental analysis is based on two established benchmarks, i.e. GTAV $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes, where we set a new SoA. The code will be released.
HYperbolic Self-Paced Learning for Self-Supervised Skeleton-based Action Representations
Mar 10, 2023Self-paced learning has been beneficial for tasks where some initial knowledge is available, such as weakly supervised learning and domain adaptation, to select and order the training sample sequence, from easy to complex. However its applicability remains unexplored in unsupervised learning, whereby the knowledge of the task matures during training. We propose a novel HYperbolic Self-Paced model (HYSP) for learning skeleton-based action representations. HYSP adopts self-supervision: it uses data augmentations to generate two views of the same sample, and it learns by matching one (named online) to the other (the target). We propose to use hyperbolic uncertainty to determine the algorithmic learning pace, under the assumption that less uncertain samples should be more strongly driving the training, with a larger weight and pace. Hyperbolic uncertainty is a by-product of the adopted hyperbolic neural networks, it matures during training and it comes with no extra cost, compared to the established Euclidean SSL framework counterparts. When tested on three established skeleton-based action recognition datasets, HYSP outperforms the state-of-the-art on PKU-MMD I, as well as on 2 out of 3 downstream tasks on NTU-60 and NTU-120. Additionally, HYSP only uses positive pairs and bypasses therefore the complex and computationally-demanding mining procedures required for the negatives in contrastive techniques. Code is available at https://github.com/paolomandica/HYSP.
Deep learning for laboratory earthquake prediction and autoregressive forecasting of fault zone stress
Mar 24, 2022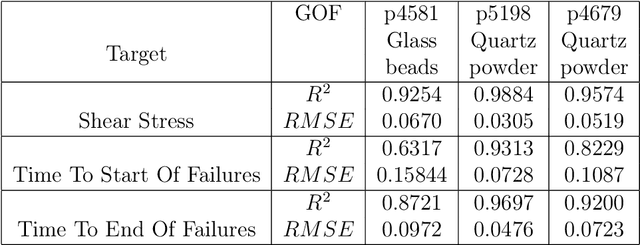
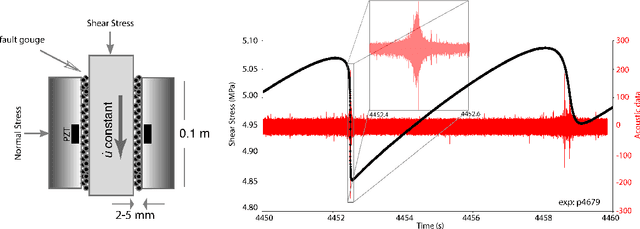
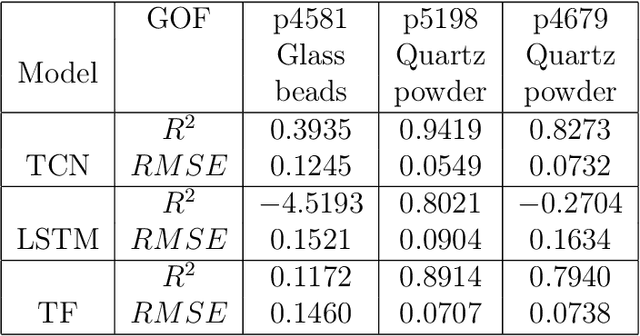
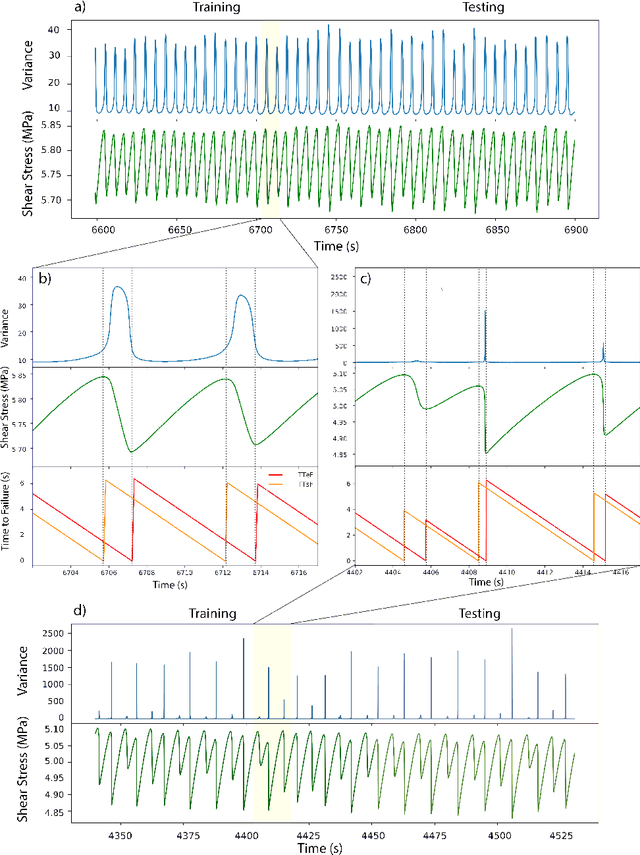
Earthquake forecasting and prediction have long and in some cases sordid histories but recent work has rekindled interest based on advances in early warning, hazard assessment for induced seismicity and successful prediction of laboratory earthquakes. In the lab, frictional stick-slip events provide an analog for earthquakes and the seismic cycle. Labquakes are ideal targets for machine learning (ML) because they can be produced in long sequences under controlled conditions. Recent works show that ML can predict several aspects of labquakes using fault zone acoustic emissions. Here, we generalize these results and explore deep learning (DL) methods for labquake prediction and autoregressive (AR) forecasting. DL improves existing ML methods of labquake prediction. AR methods allow forecasting at future horizons via iterative predictions. We demonstrate that DL models based on Long-Short Term Memory (LSTM) and Convolution Neural Networks predict labquakes under several conditions, and that fault zone stress can be predicted with fidelity, confirming that acoustic energy is a fingerprint of fault zone stress. We predict also time to start of failure (TTsF) and time to the end of Failure (TTeF) for labquakes. Interestingly, TTeF is successfully predicted in all seismic cycles, while the TTsF prediction varies with the amount of preseismic fault creep. We report AR methods to forecast the evolution of fault stress using three sequence modeling frameworks: LSTM, Temporal Convolution Network and Transformer Network. AR forecasting is distinct from existing predictive models, which predict only a target variable at a specific time. The results for forecasting beyond a single seismic cycle are limited but encouraging. Our ML/DL models outperform the state-of-the-art and our autoregressive model represents a novel framework that could enhance current methods of earthquake forecasting.
Under the Hood of Transformer Networks for Trajectory Forecasting
Mar 22, 2022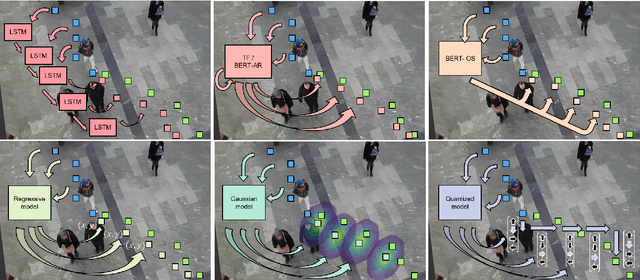
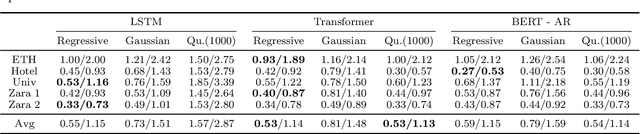
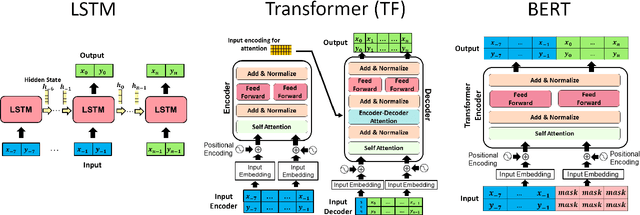
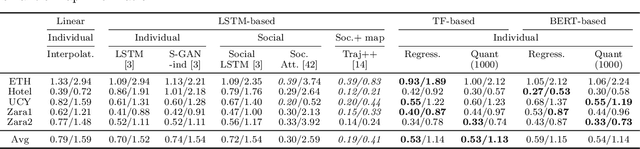
Transformer Networks have established themselves as the de-facto state-of-the-art for trajectory forecasting but there is currently no systematic study on their capability to model the motion patterns of people, without interactions with other individuals nor the social context. This paper proposes the first in-depth study of Transformer Networks (TF) and Bidirectional Transformers (BERT) for the forecasting of the individual motion of people, without bells and whistles. We conduct an exhaustive evaluation of input/output representations, problem formulations and sequence modeling, including a novel analysis of their capability to predict multi-modal futures. Out of comparative evaluation on the ETH+UCY benchmark, both TF and BERT are top performers in predicting individual motions, definitely overcoming RNNs and LSTMs. Furthermore, they remain within a narrow margin wrt more complex techniques, which include both social interactions and scene contexts. Source code will be released for all conducted experiments.
Space-Time-Separable Graph Convolutional Network for Pose Forecasting
Oct 09, 2021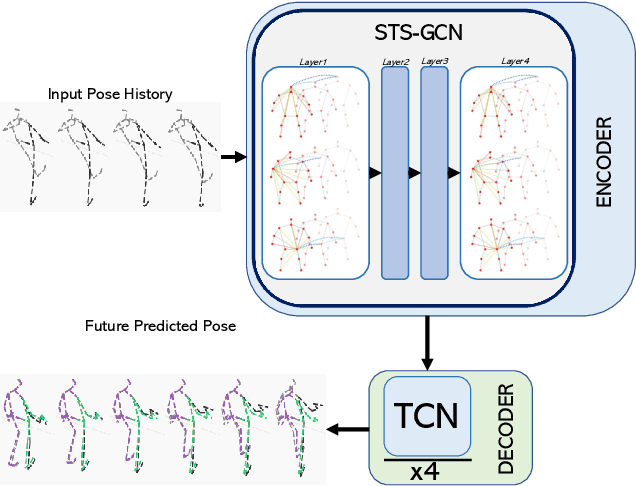
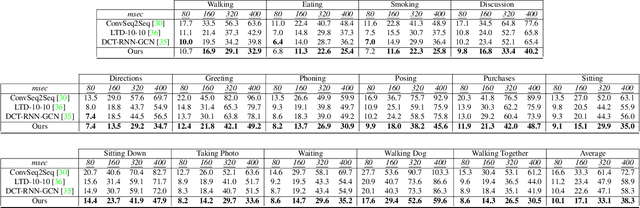
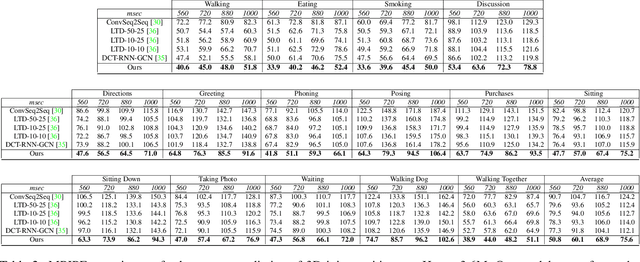
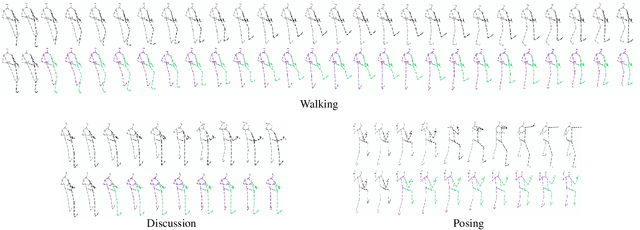
Human pose forecasting is a complex structured-data sequence-modelling task, which has received increasing attention, also due to numerous potential applications. Research has mainly addressed the temporal dimension as time series and the interaction of human body joints with a kinematic tree or by a graph. This has decoupled the two aspects and leveraged progress from the relevant fields, but it has also limited the understanding of the complex structural joint spatio-temporal dynamics of the human pose. Here we propose a novel Space-Time-Separable Graph Convolutional Network (STS-GCN) for pose forecasting. For the first time, STS-GCN models the human pose dynamics only with a graph convolutional network (GCN), including the temporal evolution and the spatial joint interaction within a single-graph framework, which allows the cross-talk of motion and spatial correlations. Concurrently, STS-GCN is the first space-time-separable GCN: the space-time graph connectivity is factored into space and time affinity matrices, which bottlenecks the space-time cross-talk, while enabling full joint-joint and time-time correlations. Both affinity matrices are learnt end-to-end, which results in connections substantially deviating from the standard kinematic tree and the linear-time time series. In experimental evaluation on three complex, recent and large-scale benchmarks, Human3.6M [Ionescu et al. TPAMI'14], AMASS [Mahmood et al. ICCV'19] and 3DPW [Von Marcard et al. ECCV'18], STS-GCN outperforms the state-of-the-art, surpassing the current best technique [Mao et al. ECCV'20] by over 32% in average at the most difficult long-term predictions, while only requiring 1.7% of its parameters. We explain the results qualitatively and illustrate the graph interactions by the factored joint-joint and time-time learnt graph connections. Our source code is available at: https://github.com/FraLuca/STSGCN