 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHidden in plain sight: VLMs overlook their visual representations
Jun 09, 2025Language provides a natural interface to specify and evaluate performance on visual tasks. To realize this possibility, vision language models (VLMs) must successfully integrate visual and linguistic information. Our work compares VLMs to a direct readout of their visual encoders to understand their ability to integrate across these modalities. Across a series of vision-centric benchmarks (e.g., depth estimation, correspondence), we find that VLMs perform substantially worse than their visual encoders, dropping to near-chance performance. We investigate these results through a series of analyses across the entire VLM: namely 1) the degradation of vision representations, 2) brittleness to task prompt, and 3) the language model's role in solving the task. We find that the bottleneck in performing these vision-centric tasks lies in this third category; VLMs are not effectively using visual information easily accessible throughout the entire model, and they inherit the language priors present in the LLM. Our work helps diagnose the failure modes of open-source VLMs, and presents a series of evaluations useful for future investigations into visual understanding within VLMs.
Hyperbolic Active Learning for Semantic Segmentation under Domain Shift
Jun 26, 2023For the task of semantic segmentation (SS) under domain shift, active learning (AL) acquisition strategies based on image regions and pseudo labels are state-of-the-art (SoA). The presence of diverse pseudo-labels within a region identifies pixels between different classes, which is a labeling efficient active learning data acquisition strategy. However, by design, pseudo-label variations are limited to only select the contours of classes, limiting the final AL performance. We approach AL for SS in the Poincar\'e hyperbolic ball model for the first time and leverage the variations of the radii of pixel embeddings within regions as a novel data acquisition strategy. This stems from a novel geometric property of a hyperbolic space trained without enforced hierarchies, which we experimentally prove. Namely, classes are mapped into compact hyperbolic areas with a comparable intra-class radii variance, as the model places classes of increasing explainable difficulty at denser hyperbolic areas, i.e. closer to the Poincar\'e ball edge. The variation of pixel embedding radii identifies well the class contours, but they also select a few intra-class peculiar details, which boosts the final performance. Our proposed HALO (Hyperbolic Active Learning Optimization) surpasses the supervised learning performance for the first time in AL for SS under domain shift, by only using a small portion of labels (i.e., 1%). The extensive experimental analysis is based on two established benchmarks, i.e. GTAV $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes, where we set a new SoA. The code will be released.
Using Language to Extend to Unseen Domains
Oct 20, 2022
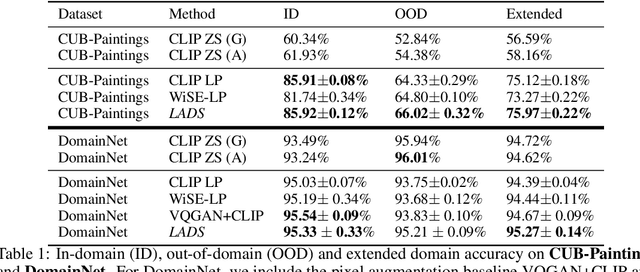
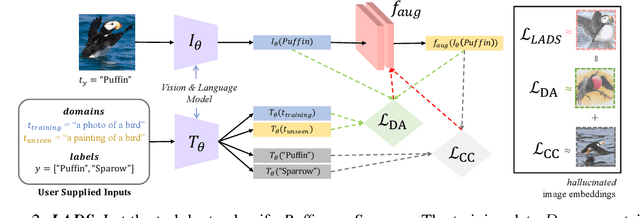

It is expensive to collect training data for every possible domain that a vision model may encounter when deployed. We instead consider how simply verbalizing the training domain (e.g. "photos of birds") as well as domains we want to extend to but do not have data for (e.g. "paintings of birds") can improve robustness. Using a multimodal model with a joint image and language embedding space, our method LADS learns a transformation of the image embeddings from the training domain to each unseen test domain, while preserving task relevant information. Without using any images from the unseen test domain, we show that over the extended domain containing both training and unseen test domains, LADS outperforms standard fine-tuning and ensemble approaches over a suite of four benchmarks targeting domain adaptation and dataset bias
Studying Bias in GANs through the Lens of Race
Sep 15, 2022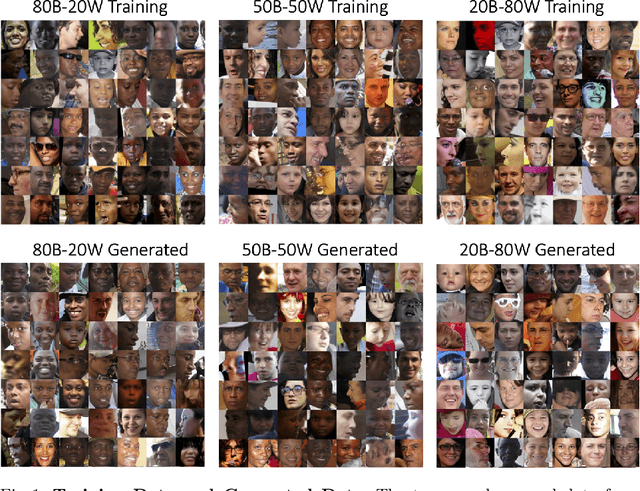



In this work, we study how the performance and evaluation of generative image models are impacted by the racial composition of their training datasets. By examining and controlling the racial distributions in various training datasets, we are able to observe the impacts of different training distributions on generated image quality and the racial distributions of the generated images. Our results show that the racial compositions of generated images successfully preserve that of the training data. However, we observe that truncation, a technique used to generate higher quality images during inference, exacerbates racial imbalances in the data. Lastly, when examining the relationship between image quality and race, we find that the highest perceived visual quality images of a given race come from a distribution where that race is well-represented, and that annotators consistently prefer generated images of white people over those of Black people.
Disentangled Action Recognition with Knowledge Bases
Jul 04, 2022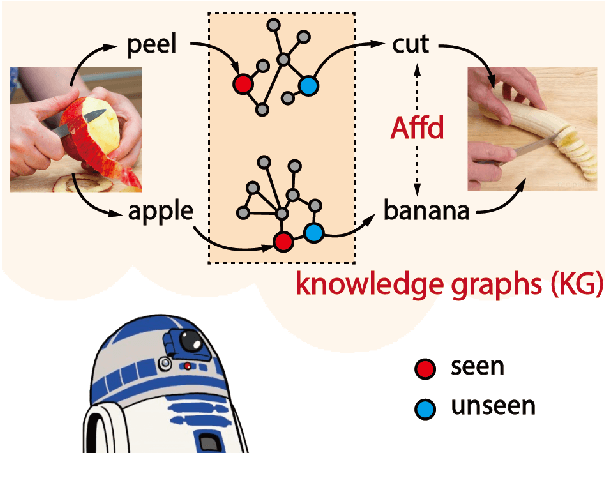
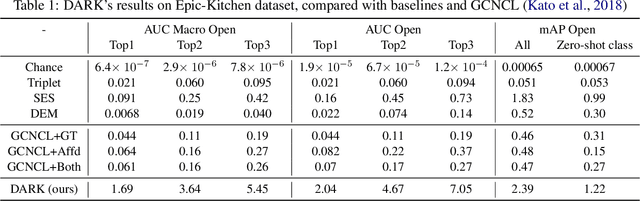
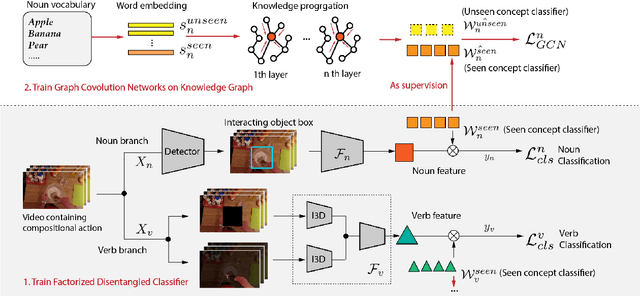
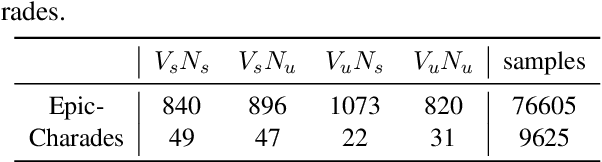
Action in video usually involves the interaction of human with objects. Action labels are typically composed of various combinations of verbs and nouns, but we may not have training data for all possible combinations. In this paper, we aim to improve the generalization ability of the compositional action recognition model to novel verbs or novel nouns that are unseen during training time, by leveraging the power of knowledge graphs. Previous work utilizes verb-noun compositional action nodes in the knowledge graph, making it inefficient to scale since the number of compositional action nodes grows quadratically with respect to the number of verbs and nouns. To address this issue, we propose our approach: Disentangled Action Recognition with Knowledge-bases (DARK), which leverages the inherent compositionality of actions. DARK trains a factorized model by first extracting disentangled feature representations for verbs and nouns, and then predicting classification weights using relations in external knowledge graphs. The type constraint between verb and noun is extracted from external knowledge bases and finally applied when composing actions. DARK has better scalability in the number of objects and verbs, and achieves state-of-the-art performance on the Charades dataset. We further propose a new benchmark split based on the Epic-kitchen dataset which is an order of magnitude bigger in the numbers of classes and samples, and benchmark various models on this benchmark.
Predicting with Confidence on Unseen Distributions
Jul 07, 2021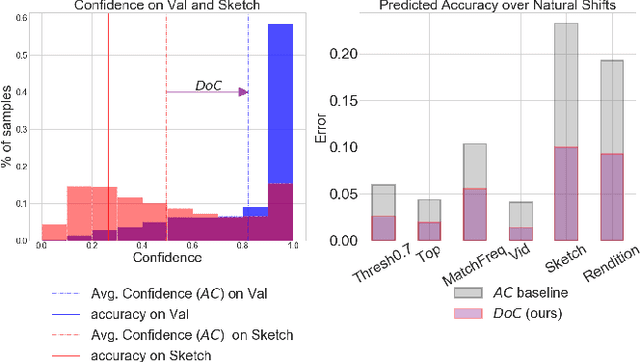
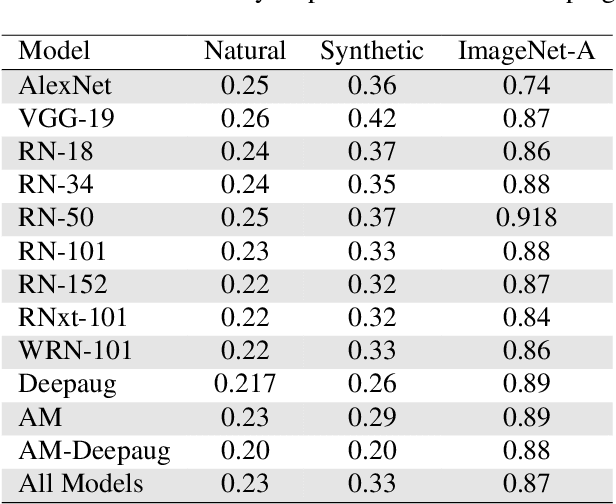
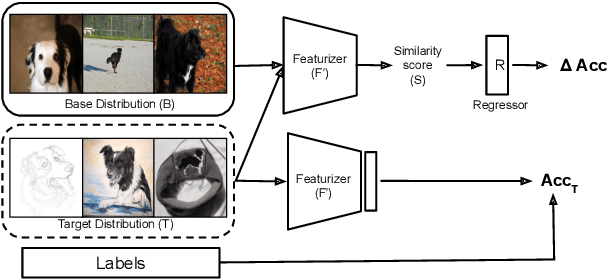
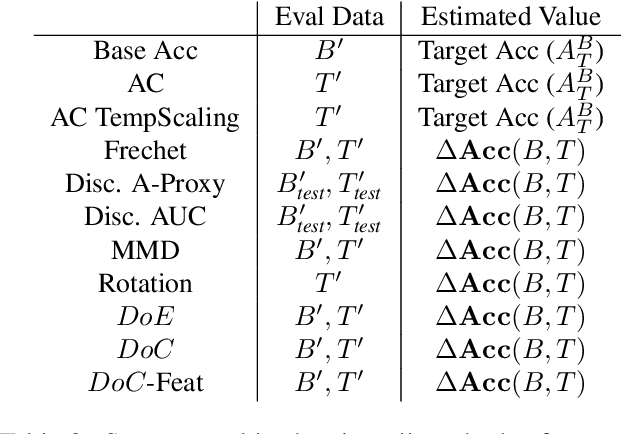
Recent work has shown that the performance of machine learning models can vary substantially when models are evaluated on data drawn from a distribution that is close to but different from the training distribution. As a result, predicting model performance on unseen distributions is an important challenge. Our work connects techniques from domain adaptation and predictive uncertainty literature, and allows us to predict model accuracy on challenging unseen distributions without access to labeled data. In the context of distribution shift, distributional distances are often used to adapt models and improve their performance on new domains, however accuracy estimation, or other forms of predictive uncertainty, are often neglected in these investigations. Through investigating a wide range of established distributional distances, such as Frechet distance or Maximum Mean Discrepancy, we determine that they fail to induce reliable estimates of performance under distribution shift. On the other hand, we find that the difference of confidences (DoC) of a classifier's predictions successfully estimates the classifier's performance change over a variety of shifts. We specifically investigate the distinction between synthetic and natural distribution shifts and observe that despite its simplicity DoC consistently outperforms other quantifications of distributional difference. $DoC$ reduces predictive error by almost half ($46\%$) on several realistic and challenging distribution shifts, e.g., on the ImageNet-Vid-Robust and ImageNet-Rendition datasets.
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021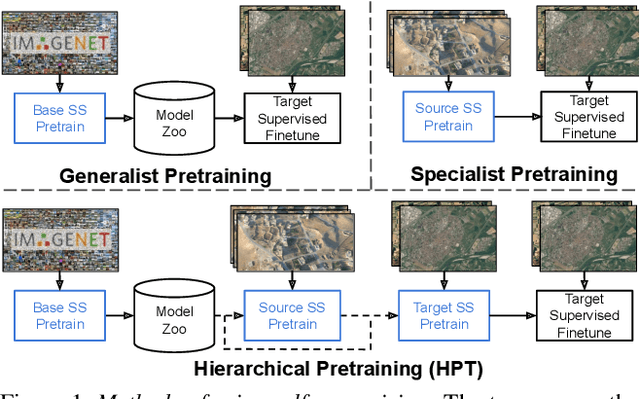
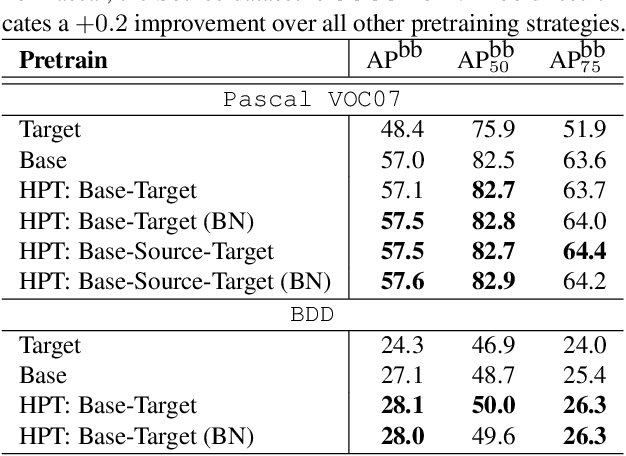
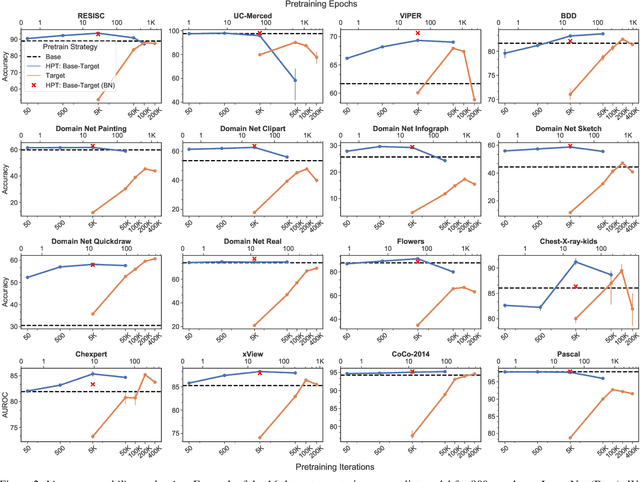
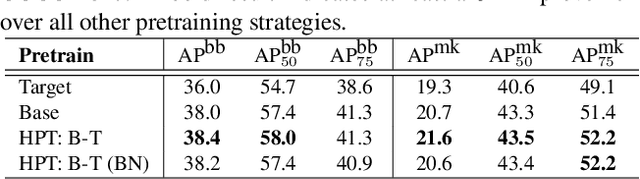
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.
Weakly-Supervised Action Localization with Expectation-Maximization Multi-Instance Learning
Mar 31, 2020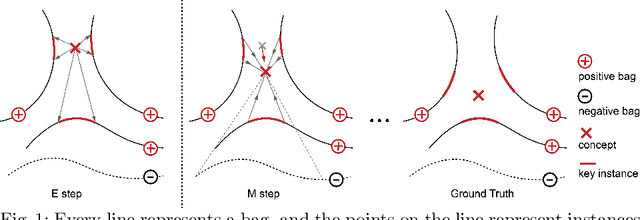
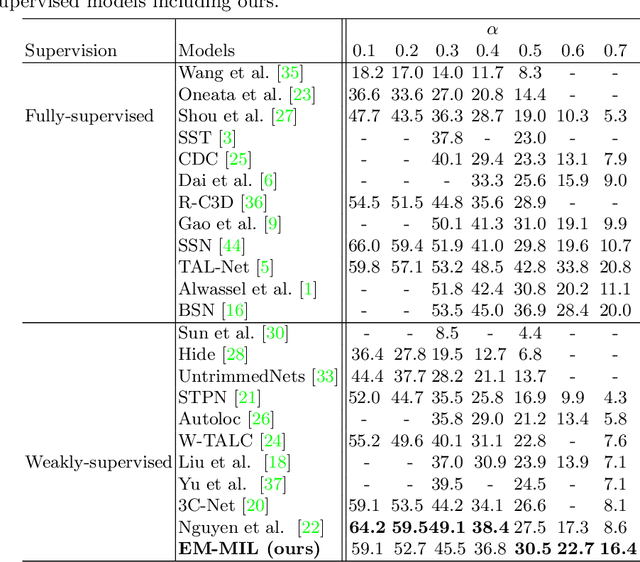
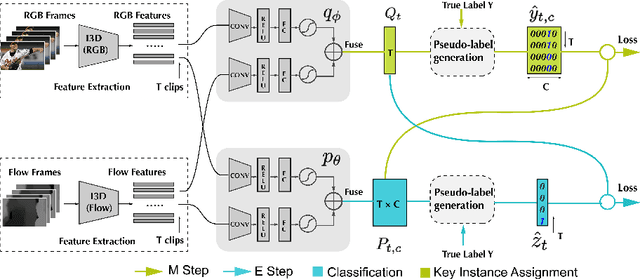
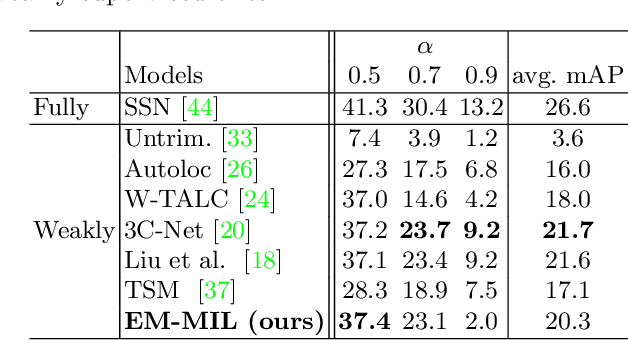
Weakly-supervised action localization problem requires training a model to localize the action segments in the video given only video level action label. It can be solved under the Multiple Instance Learning (MIL) framework, where a bag (video) contains multiple instances (action segments). Since only the bag's label is known, the main challenge is to assign which key instances within the bag trigger the bag's label. Most previous models use an attention-based approach. These models use attention to generate the bag's representation from instances and then train it via bag's classification. In this work, we explicitly model the key instances assignment as a hidden variable and adopt an Expectation-Maximization framework. We derive two pseudo-label generation schemes to model the E and M process and iteratively optimize the likelihood lower bound. We also show that previous attention-based models implicitly violate the MIL assumptions that instances in negative bags should be uniformly negative. In comparison, Our EM-MIL approach more accurately models these assumptions. Our model achieves state-of-the-art performance on two standard benchmarks, THUMOS14 and ActivityNet1.2, and shows the superiority of detecting relative complete action boundary in videos containing multiple actions.