 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning
Jan 02, 2023
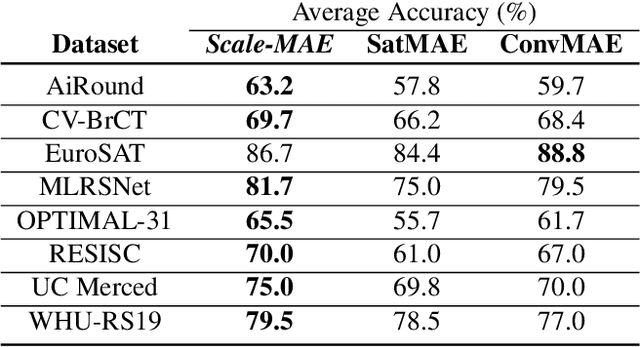
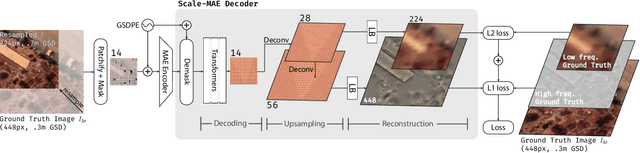

Remote sensing imagery provides comprehensive views of the Earth, where different sensors collect complementary data at different spatial scales. Large, pretrained models are commonly finetuned with imagery that is heavily augmented to mimic different conditions and scales, with the resulting models used for various tasks with imagery from a range of spatial scales. Such models overlook scale-specific information in the data. In this paper, we present Scale-MAE, a pretraining method that explicitly learns relationships between data at different, known scales throughout the pretraining process. Scale-MAE pretrains a network by masking an input image at a known input scale, where the area of the Earth covered by the image determines the scale of the ViT positional encoding, not the image resolution. Scale-MAE encodes the masked image with a standard ViT backbone, and then decodes the masked image through a bandpass filter to reconstruct low/high frequency images at lower/higher scales. We find that tasking the network with reconstructing both low/high frequency images leads to robust multiscale representations for remote sensing imagery. Scale-MAE achieves an average of a $5.0\%$ non-parametric kNN classification improvement across eight remote sensing datasets compared to current state-of-the-art and obtains a $0.9$ mIoU to $3.8$ mIoU improvement on the SpaceNet building segmentation transfer task for a range of evaluation scales.
Invariant Information Bottleneck for Domain Generalization
Jun 14, 2021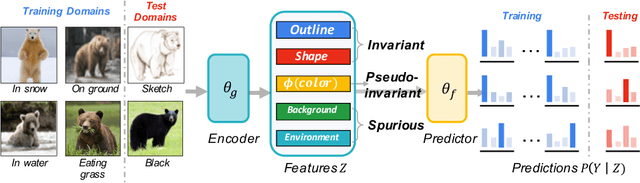
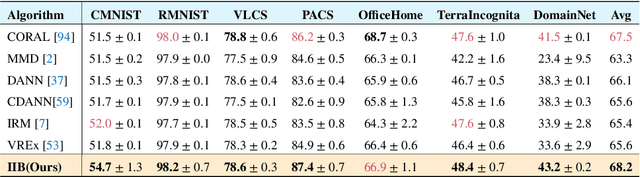
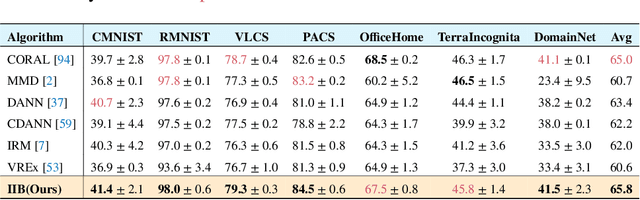
The main challenge for domain generalization (DG) is to overcome the potential distributional shift between multiple training domains and unseen test domains. One popular class of DG algorithms aims to learn representations that have an invariant causal relation across the training domains. However, certain features, called \emph{pseudo-invariant features}, may be invariant in the training domain but not the test domain and can substantially decreases the performance of existing algorithms. To address this issue, we propose a novel algorithm, called Invariant Information Bottleneck (IIB), that learns a minimally sufficient representation that is invariant across training and testing domains. By minimizing the mutual information between the representation and inputs, IIB alleviates its reliance on pseudo-invariant features, which is desirable for DG. To verify the effectiveness of the IIB principle, we conduct extensive experiments on large-scale DG benchmarks. The results show that IIB outperforms invariant learning baseline (e.g. IRM) by an average of 2.8\% and 3.8\% accuracy over two evaluation metrics.
Self-Supervised Pretraining Improves Self-Supervised Pretraining
Mar 25, 2021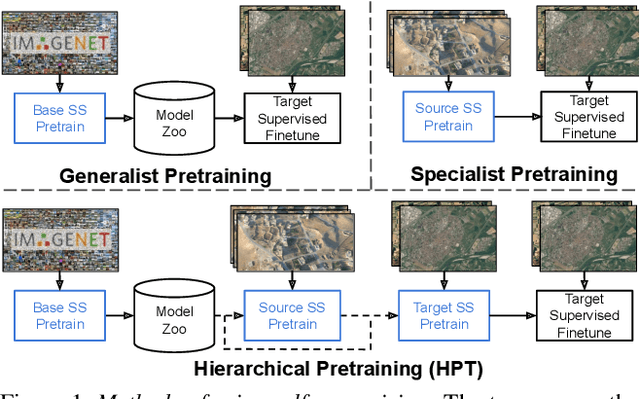
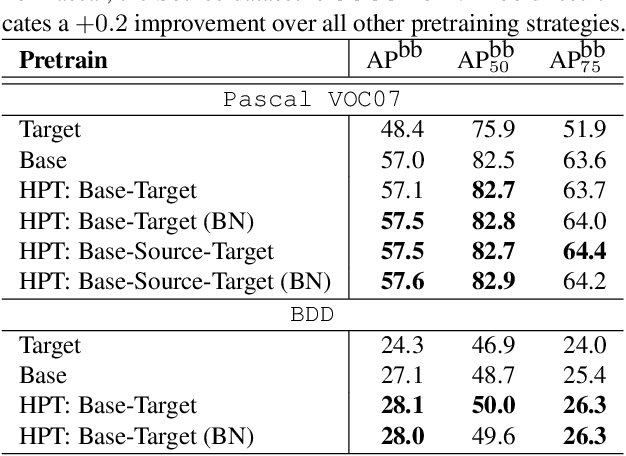
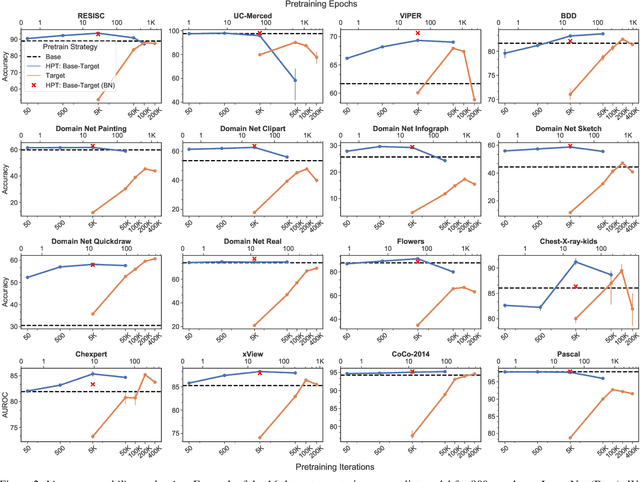
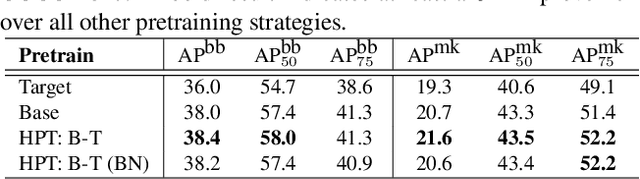
While self-supervised pretraining has proven beneficial for many computer vision tasks, it requires expensive and lengthy computation, large amounts of data, and is sensitive to data augmentation. Prior work demonstrates that models pretrained on datasets dissimilar to their target data, such as chest X-ray models trained on ImageNet, underperform models trained from scratch. Users that lack the resources to pretrain must use existing models with lower performance. This paper explores Hierarchical PreTraining (HPT), which decreases convergence time and improves accuracy by initializing the pretraining process with an existing pretrained model. Through experimentation on 16 diverse vision datasets, we show HPT converges up to 80x faster, improves accuracy across tasks, and improves the robustness of the self-supervised pretraining process to changes in the image augmentation policy or amount of pretraining data. Taken together, HPT provides a simple framework for obtaining better pretrained representations with less computational resources.