 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotationally Invariant Latent Distances for Uncertainty Estimation of Relaxed Energy Predictions by Graph Neural Network Potentials
Jul 15, 2024Graph neural networks (GNNs) have been shown to be astonishingly capable models for molecular property prediction, particularly as surrogates for expensive density functional theory calculations of relaxed energy for novel material discovery. However, one limitation of GNNs in this context is the lack of useful uncertainty prediction methods, as this is critical to the material discovery pipeline. In this work, we show that uncertainty quantification for relaxed energy calculations is more complex than uncertainty quantification for other kinds of molecular property prediction, due to the effect that structure optimizations have on the error distribution. We propose that distribution-free techniques are more useful tools for assessing calibration, recalibrating, and developing uncertainty prediction methods for GNNs performing relaxed energy calculations. We also develop a relaxed energy task for evaluating uncertainty methods for equivariant GNNs, based on distribution-free recalibration and using the Open Catalyst Project dataset. We benchmark a set of popular uncertainty prediction methods on this task, and show that latent distance methods, with our novel improvements, are the most well-calibrated and economical approach for relaxed energy calculations. Finally, we demonstrate that our latent space distance method produces results which align with our expectations on a clustering example, and on specific equation of state and adsorbate coverage examples from outside the training dataset.
The Open DAC 2023 Dataset and Challenges for Sorbent Discovery in Direct Air Capture
Nov 01, 2023
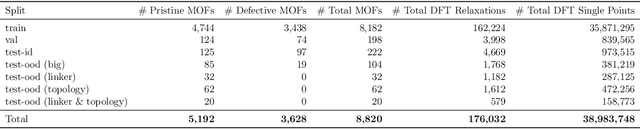
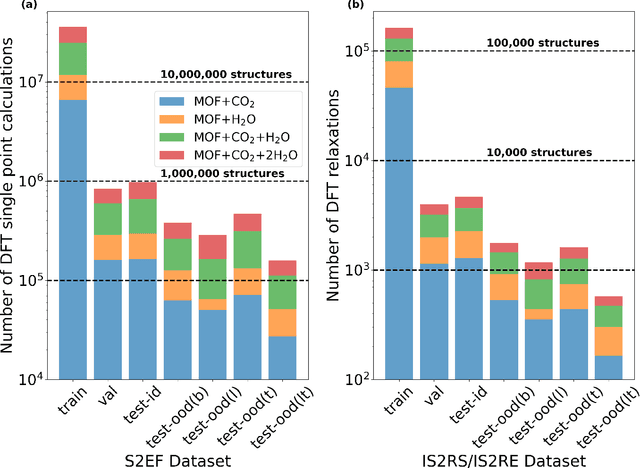

New methods for carbon dioxide removal are urgently needed to combat global climate change. Direct air capture (DAC) is an emerging technology to capture carbon dioxide directly from ambient air. Metal-organic frameworks (MOFs) have been widely studied as potentially customizable adsorbents for DAC. However, discovering promising MOF sorbents for DAC is challenging because of the vast chemical space to explore and the need to understand materials as functions of humidity and temperature. We explore a computational approach benefiting from recent innovations in machine learning (ML) and present a dataset named Open DAC 2023 (ODAC23) consisting of more than 38M density functional theory (DFT) calculations on more than 8,800 MOF materials containing adsorbed CO2 and/or H2O. ODAC23 is by far the largest dataset of MOF adsorption calculations at the DFT level of accuracy currently available. In addition to probing properties of adsorbed molecules, the dataset is a rich source of information on structural relaxation of MOFs, which will be useful in many contexts beyond specific applications for DAC. A large number of MOFs with promising properties for DAC are identified directly in ODAC23. We also trained state-of-the-art ML models on this dataset to approximate calculations at the DFT level. This open-source dataset and our initial ML models will provide an important baseline for future efforts to identify MOFs for a wide range of applications, including DAC.
Scale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning
Jan 02, 2023
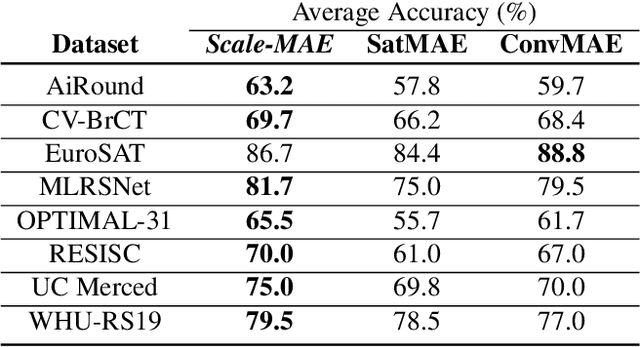
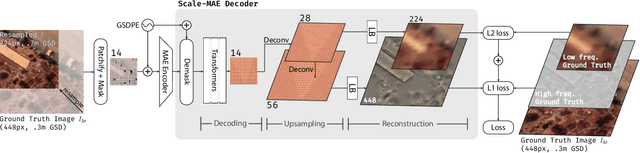

Remote sensing imagery provides comprehensive views of the Earth, where different sensors collect complementary data at different spatial scales. Large, pretrained models are commonly finetuned with imagery that is heavily augmented to mimic different conditions and scales, with the resulting models used for various tasks with imagery from a range of spatial scales. Such models overlook scale-specific information in the data. In this paper, we present Scale-MAE, a pretraining method that explicitly learns relationships between data at different, known scales throughout the pretraining process. Scale-MAE pretrains a network by masking an input image at a known input scale, where the area of the Earth covered by the image determines the scale of the ViT positional encoding, not the image resolution. Scale-MAE encodes the masked image with a standard ViT backbone, and then decodes the masked image through a bandpass filter to reconstruct low/high frequency images at lower/higher scales. We find that tasking the network with reconstructing both low/high frequency images leads to robust multiscale representations for remote sensing imagery. Scale-MAE achieves an average of a $5.0\%$ non-parametric kNN classification improvement across eight remote sensing datasets compared to current state-of-the-art and obtains a $0.9$ mIoU to $3.8$ mIoU improvement on the SpaceNet building segmentation transfer task for a range of evaluation scales.
AdsorbML: Accelerating Adsorption Energy Calculations with Machine Learning
Nov 29, 2022Computational catalysis is playing an increasingly significant role in the design of catalysts across a wide range of applications. A common task for many computational methods is the need to accurately compute the minimum binding energy - the adsorption energy - for an adsorbate and a catalyst surface of interest. Traditionally, the identification of low energy adsorbate-surface configurations relies on heuristic methods and researcher intuition. As the desire to perform high-throughput screening increases, it becomes challenging to use heuristics and intuition alone. In this paper, we demonstrate machine learning potentials can be leveraged to identify low energy adsorbate-surface configurations more accurately and efficiently. Our algorithm provides a spectrum of trade-offs between accuracy and efficiency, with one balanced option finding the lowest energy configuration, within a 0.1 eV threshold, 86.63% of the time, while achieving a 1387x speedup in computation. To standardize benchmarking, we introduce the Open Catalyst Dense dataset containing nearly 1,000 diverse surfaces and 87,045 unique configurations.
A Practical Stereo Depth System for Smart Glasses
Nov 19, 2022



We present the design of a productionized end-to-end stereo depth sensing system that does pre-processing, online stereo rectification, and stereo depth estimation with a fallback to monocular depth estimation when rectification is unreliable. The output of our depth sensing system is then used in a novel view generation pipeline to create 3D computational photography effect using point-of-view images captured by smart glasses. All these steps are executed on-device on the stringent compute budget of a mobile phone, and because we expect the users can use a wide range of smartphones, our design needs to be general and cannot be dependent on a particular hardware or ML accelerator such as a smartphone GPU. Although each of these steps is well-studied, a description of a practical system is still lacking. For such a system, each of these steps need to work in tandem with one another and fallback gracefully on failures within the system or less than ideal input data. We show how we handle unforeseen changes to calibration, e.g. due to heat, robustly support depth estimation in the wild, and still abide by the memory and latency constraints required for a smooth user experience. We show that our trained models are fast, that run in less than 1s on a six-year-old Samsung Galaxy S8 phone's CPU. Our models generalize well to unseen data and achieve good results on Middlebury and in-the-wild images captured from the smart glasses.
ChamNet: Towards Efficient Network Design through Platform-Aware Model Adaptation
Dec 21, 2018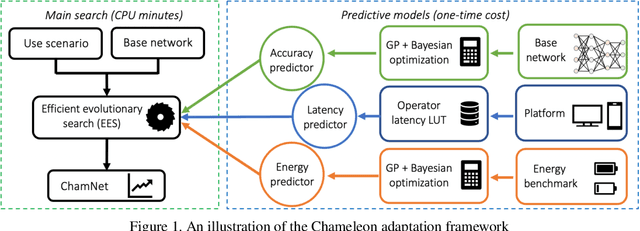
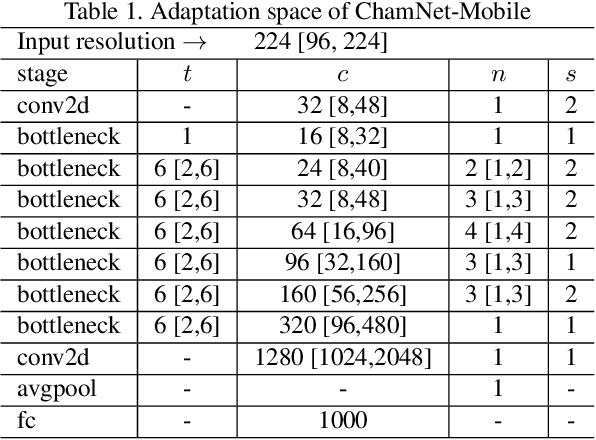
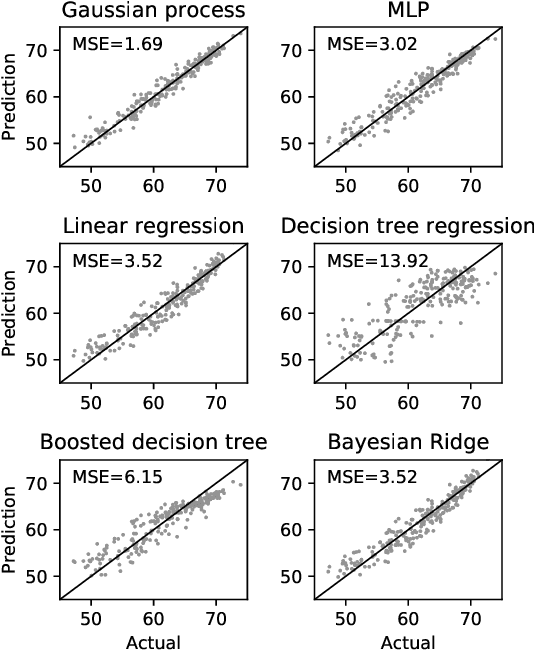
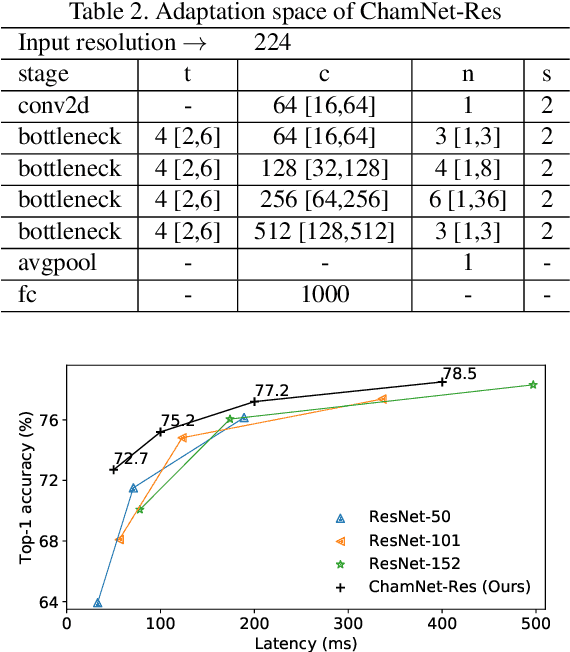
This paper proposes an efficient neural network (NN) architecture design methodology called Chameleon that honors given resource constraints. Instead of developing new building blocks or using computationally-intensive reinforcement learning algorithms, our approach leverages existing efficient network building blocks and focuses on exploiting hardware traits and adapting computation resources to fit target latency and/or energy constraints. We formulate platform-aware NN architecture search in an optimization framework and propose a novel algorithm to search for optimal architectures aided by efficient accuracy and resource (latency and/or energy) predictors. At the core of our algorithm lies an accuracy predictor built atop Gaussian Process with Bayesian optimization for iterative sampling. With a one-time building cost for the predictors, our algorithm produces state-of-the-art model architectures on different platforms under given constraints in just minutes. Our results show that adapting computation resources to building blocks is critical to model performance. Without the addition of any bells and whistles, our models achieve significant accuracy improvements against state-of-the-art hand-crafted and automatically designed architectures. We achieve 73.8% and 75.3% top-1 accuracy on ImageNet at 20ms latency on a mobile CPU and DSP. At reduced latency, our models achieve up to 8.5% (4.8%) and 6.6% (9.3%) absolute top-1 accuracy improvements compared to MobileNetV2 and MnasNet, respectively, on a mobile CPU (DSP), and 2.7% (4.6%) and 5.6% (2.6%) accuracy gains over ResNet-101 and ResNet-152, respectively, on an Nvidia GPU (Intel CPU).
Deep Burst Denoising
Dec 15, 2017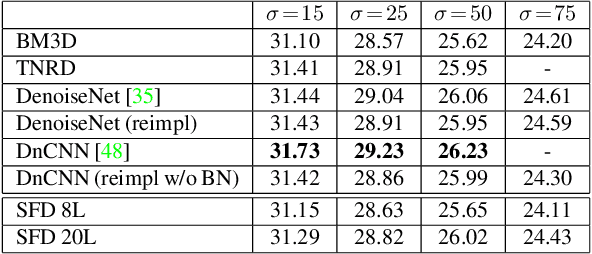
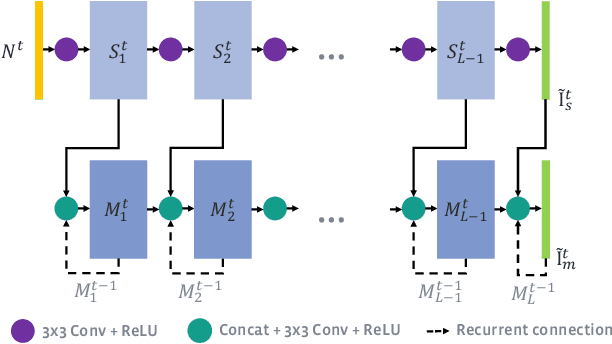

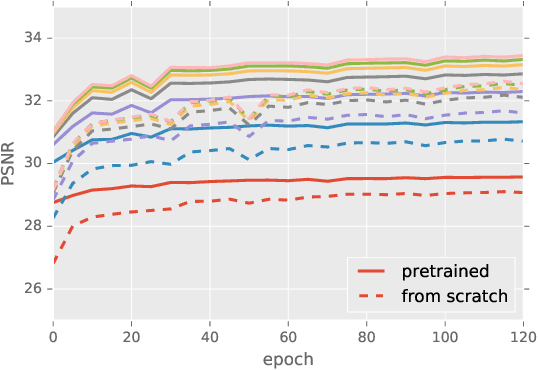
Noise is an inherent issue of low-light image capture, one which is exacerbated on mobile devices due to their narrow apertures and small sensors. One strategy for mitigating noise in a low-light situation is to increase the shutter time of the camera, thus allowing each photosite to integrate more light and decrease noise variance. However, there are two downsides of long exposures: (a) bright regions can exceed the sensor range, and (b) camera and scene motion will result in blurred images. Another way of gathering more light is to capture multiple short (thus noisy) frames in a "burst" and intelligently integrate the content, thus avoiding the above downsides. In this paper, we use the burst-capture strategy and implement the intelligent integration via a recurrent fully convolutional deep neural net (CNN). We build our novel, multiframe architecture to be a simple addition to any single frame denoising model, and design to handle an arbitrary number of noisy input frames. We show that it achieves state of the art denoising results on our burst dataset, improving on the best published multi-frame techniques, such as VBM4D and FlexISP. Finally, we explore other applications of image enhancement by integrating content from multiple frames and demonstrate that our DNN architecture generalizes well to image super-resolution.
Real-time Image-based 6-DOF Localization in Large-Scale Environments
Mar 27, 2012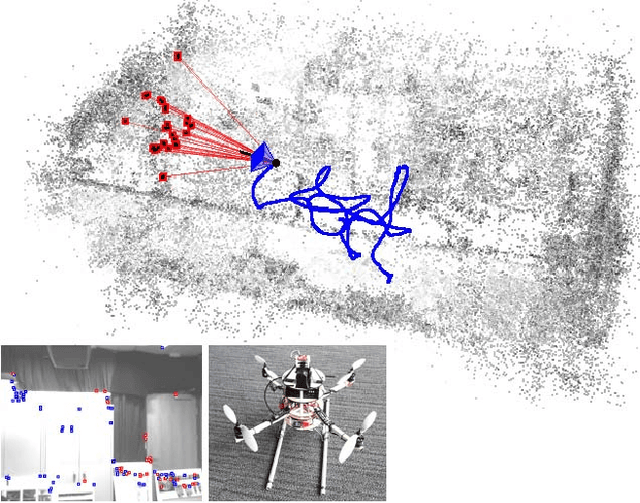
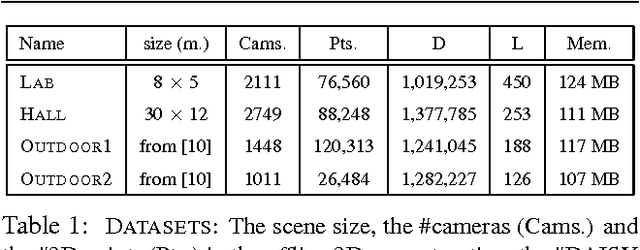
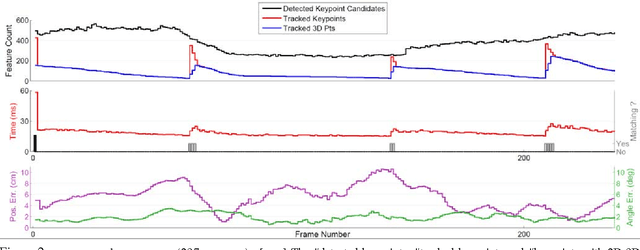
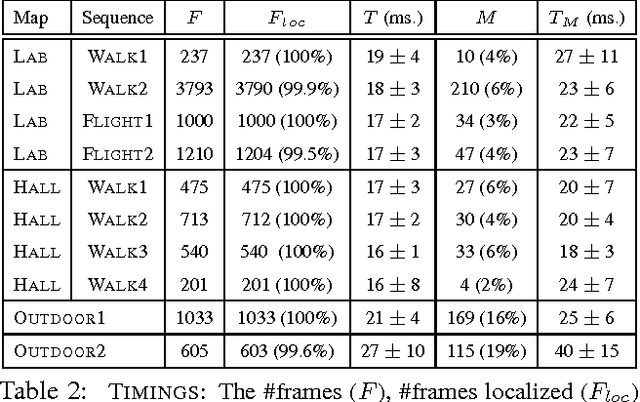
We present a real-time approach for image-based localization within large scenes that have been reconstructed offline using structure from motion (Sfm). From monocular video, our method continuously computes a precise 6-DOF camera pose, by efficiently tracking natural features and matching them to 3D points in the Sfm point cloud. Our main contribution lies in efficiently interleaving a fast keypoint tracker that uses inexpensive binary feature descriptors with a new approach for direct 2D-to-3D matching. The 2D-to-3D matching avoids the need for online extraction of scale-invariant features. Instead, offline we construct an indexed database containing multiple DAISY descriptors per 3D point extracted at multiple scales. The key to the efficiency of our method lies in invoking DAISY descriptor extraction and matching sparingly during localization, and in distributing this computation over a window of successive frames. This enables the algorithm to run in real-time, without fluctuations in the latency over long durations. We evaluate the method in large indoor and outdoor scenes. Our algorithm runs at over 30 Hz on a laptop and at 12 Hz on a low-power, mobile computer suitable for onboard computation on a quadrotor micro aerial vehicle.