 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinted Frames: Question Framing Blinds Vision-Language Models
Mar 19, 2026Vision-Language Models (VLMs) have been shown to be blind, often underutilizing their visual inputs even on tasks that require visual reasoning. In this work, we demonstrate that VLMs are selectively blind. They modulate the amount of attention applied to visual inputs based on linguistic framing even when alternative framings demand identical visual reasoning. Using visual attention as a probe, we quantify how framing alters both the amount and distribution of attention over the image. Constrained framings, such as multiple choice and yes/no, induce substantially lower attention to image context compared to open-ended, reduce focus on task-relevant regions, and shift attention towards uninformative tokens. We further demonstrate that this attention misallocation is the principal cause of degraded accuracy and cross-framing inconsistency. Building on this mechanistic insight, we introduce a lightweight prompt-tuning method using learnable tokens that encourages the robust, visually grounded attention patterns observed in open-ended settings, improving visual grounding and improving performance across framings.
REOrdering Patches Improves Vision Models
May 29, 2025Sequence models such as transformers require inputs to be represented as one-dimensional sequences. In vision, this typically involves flattening images using a fixed row-major (raster-scan) order. While full self-attention is permutation-equivariant, modern long-sequence transformers increasingly rely on architectural approximations that break this invariance and introduce sensitivity to patch ordering. We show that patch order significantly affects model performance in such settings, with simple alternatives like column-major or Hilbert curves yielding notable accuracy shifts. Motivated by this, we propose REOrder, a two-stage framework for discovering task-optimal patch orderings. First, we derive an information-theoretic prior by evaluating the compressibility of various patch sequences. Then, we learn a policy over permutations by optimizing a Plackett-Luce policy using REINFORCE. This approach enables efficient learning in a combinatorial permutation space. REOrder improves top-1 accuracy over row-major ordering on ImageNet-1K by up to 3.01% and Functional Map of the World by 13.35%.
LISAT: Language-Instructed Segmentation Assistant for Satellite Imagery
May 05, 2025Segmentation models can recognize a pre-defined set of objects in images. However, models that can reason over complex user queries that implicitly refer to multiple objects of interest are still in their infancy. Recent advances in reasoning segmentation--generating segmentation masks from complex, implicit query text--demonstrate that vision-language models can operate across an open domain and produce reasonable outputs. However, our experiments show that such models struggle with complex remote-sensing imagery. In this work, we introduce LISAt, a vision-language model designed to describe complex remote-sensing scenes, answer questions about them, and segment objects of interest. We trained LISAt on a new curated geospatial reasoning-segmentation dataset, GRES, with 27,615 annotations over 9,205 images, and a multimodal pretraining dataset, PreGRES, containing over 1 million question-answer pairs. LISAt outperforms existing geospatial foundation models such as RS-GPT4V by over 10.04 % (BLEU-4) on remote-sensing description tasks, and surpasses state-of-the-art open-domain models on reasoning segmentation tasks by 143.36 % (gIoU). Our model, datasets, and code are available at https://lisat-bair.github.io/LISAt/
Enough Coin Flips Can Make LLMs Act Bayesian
Mar 06, 2025Large language models (LLMs) exhibit the ability to generalize given few-shot examples in their input prompt, an emergent capability known as in-context learning (ICL). We investigate whether LLMs utilize ICL to perform structured reasoning in ways that are consistent with a Bayesian framework or rely on pattern matching. Using a controlled setting of biased coin flips, we find that: (1) LLMs often possess biased priors, causing initial divergence in zero-shot settings, (2) in-context evidence outweighs explicit bias instructions, (3) LLMs broadly follow Bayesian posterior updates, with deviations primarily due to miscalibrated priors rather than flawed updates, and (4) attention magnitude has negligible effect on Bayesian inference. With sufficient demonstrations of biased coin flips via ICL, LLMs update their priors in a Bayesian manner.
Whack-a-Chip: The Futility of Hardware-Centric Export Controls
Nov 21, 2024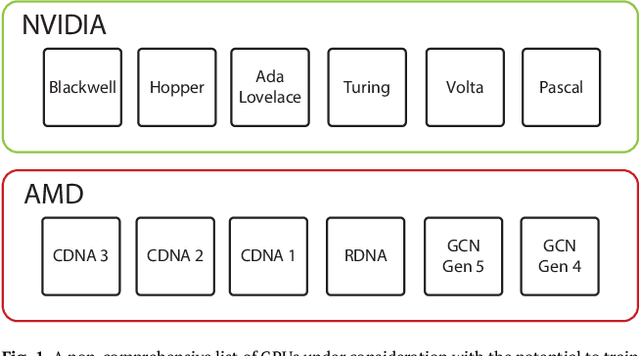
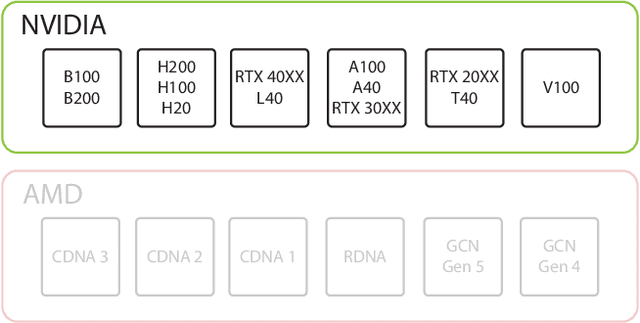
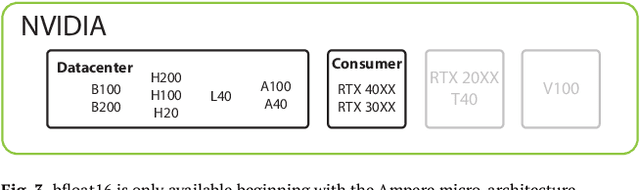

U.S. export controls on semiconductors are widely known to be permeable, with the People's Republic of China (PRC) steadily creating state-of-the-art artificial intelligence (AI) models with exfiltrated chips. This paper presents the first concrete, public evidence of how leading PRC AI labs evade and circumvent U.S. export controls. We examine how Chinese companies, notably Tencent, are not only using chips that are restricted under U.S. export controls but are also finding ways to circumvent these regulations by using software and modeling techniques that maximize less capable hardware. Specifically, we argue that Tencent's ability to power its Hunyuan-Large model with non-export controlled NVIDIA H20s exemplifies broader gains in efficiency in machine learning that have eroded the moat that the United States initially built via its existing export controls. Finally, we examine the implications of this finding for the future of the United States' export control strategy.
Data-Centric AI Governance: Addressing the Limitations of Model-Focused Policies
Sep 25, 2024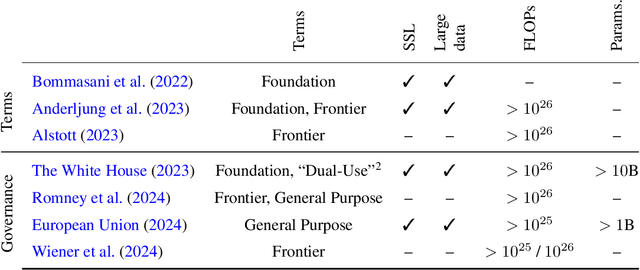
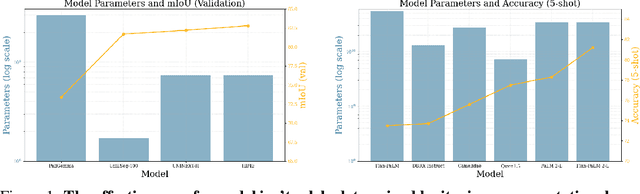
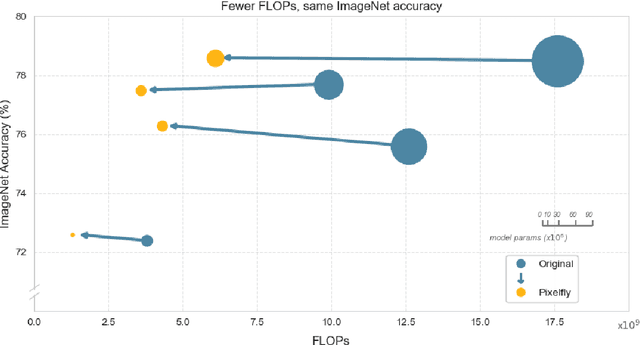
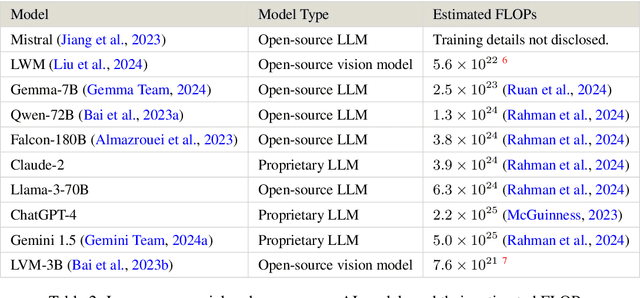
Current regulations on powerful AI capabilities are narrowly focused on "foundation" or "frontier" models. However, these terms are vague and inconsistently defined, leading to an unstable foundation for governance efforts. Critically, policy debates often fail to consider the data used with these models, despite the clear link between data and model performance. Even (relatively) "small" models that fall outside the typical definitions of foundation and frontier models can achieve equivalent outcomes when exposed to sufficiently specific datasets. In this work, we illustrate the importance of considering dataset size and content as essential factors in assessing the risks posed by models both today and in the future. More broadly, we emphasize the risk posed by over-regulating reactively and provide a path towards careful, quantitative evaluation of capabilities that can lead to a simplified regulatory environment.
Visual Haystacks: Answering Harder Questions About Sets of Images
Jul 18, 2024



Recent advancements in Large Multimodal Models (LMMs) have made significant progress in the field of single-image visual question answering. However, these models face substantial challenges when tasked with queries that span extensive collections of images, similar to real-world scenarios like searching through large photo albums, finding specific information across the internet, or monitoring environmental changes through satellite imagery. This paper explores the task of Multi-Image Visual Question Answering (MIQA): given a large set of images and a natural language query, the task is to generate a relevant and grounded response. We propose a new public benchmark, dubbed "Visual Haystacks (VHs)," specifically designed to evaluate LMMs' capabilities in visual retrieval and reasoning over sets of unrelated images, where we perform comprehensive evaluations demonstrating that even robust closed-source models struggle significantly. Towards addressing these shortcomings, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), a novel retrieval/QA framework tailored for LMMs that confronts the challenges of MIQA with marked efficiency and accuracy improvements over baseline methods. Our evaluation shows that MIRAGE surpasses closed-source GPT-4o models by up to 11% on the VHs benchmark and offers up to 3.4x improvements in efficiency over text-focused multi-stage approaches.
xT: Nested Tokenization for Larger Context in Large Images
Mar 04, 2024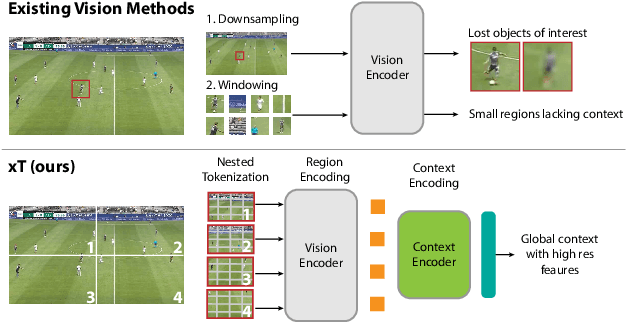
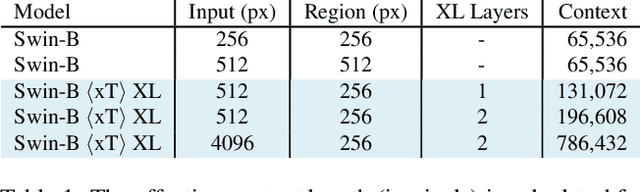
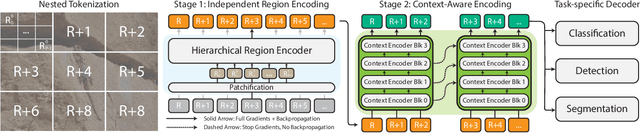
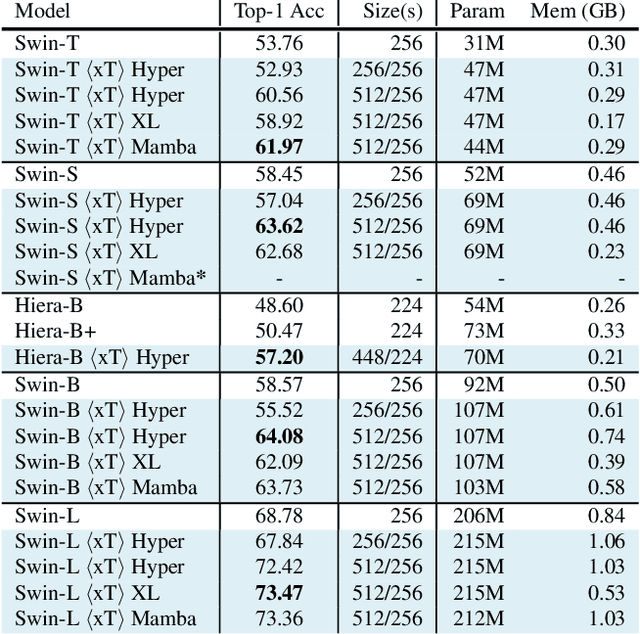
Modern computer vision pipelines handle large images in one of two sub-optimal ways: down-sampling or cropping. These two methods incur significant losses in the amount of information and context present in an image. There are many downstream applications in which global context matters as much as high frequency details, such as in real-world satellite imagery; in such cases researchers have to make the uncomfortable choice of which information to discard. We introduce xT, a simple framework for vision transformers which effectively aggregates global context with local details and can model large images end-to-end on contemporary GPUs. We select a set of benchmark datasets across classic vision tasks which accurately reflect a vision model's ability to understand truly large images and incorporate fine details over large scales and assess our method's improvement on them. By introducing a nested tokenization scheme for large images in conjunction with long-sequence length models normally used for natural language processing, we are able to increase accuracy by up to 8.6% on challenging classification tasks and $F_1$ score by 11.6 on context-dependent segmentation in large images.
See, Say, and Segment: Teaching LMMs to Overcome False Premises
Dec 13, 2023



Current open-source Large Multimodal Models (LMMs) excel at tasks such as open-vocabulary language grounding and segmentation but can suffer under false premises when queries imply the existence of something that is not actually present in the image. We observe that existing methods that fine-tune an LMM to segment images significantly degrade their ability to reliably determine ("see") if an object is present and to interact naturally with humans ("say"), a form of catastrophic forgetting. In this work, we propose a cascading and joint training approach for LMMs to solve this task, avoiding catastrophic forgetting of previous skills. Our resulting model can "see" by detecting whether objects are present in an image, "say" by telling the user if they are not, proposing alternative queries or correcting semantic errors in the query, and finally "segment" by outputting the mask of the desired objects if they exist. Additionally, we introduce a novel False Premise Correction benchmark dataset, an extension of existing RefCOCO(+/g) referring segmentation datasets (which we call FP-RefCOCO(+/g)). The results show that our method not only detects false premises up to 55% better than existing approaches, but under false premise conditions produces relative cIOU improvements of more than 31% over baselines, and produces natural language feedback judged helpful up to 67% of the time.
ClimSim: An open large-scale dataset for training high-resolution physics emulators in hybrid multi-scale climate simulators
Jun 16, 2023Modern climate projections lack adequate spatial and temporal resolution due to computational constraints. A consequence is inaccurate and imprecise prediction of critical processes such as storms. Hybrid methods that combine physics with machine learning (ML) have introduced a new generation of higher fidelity climate simulators that can sidestep Moore's Law by outsourcing compute-hungry, short, high-resolution simulations to ML emulators. However, this hybrid ML-physics simulation approach requires domain-specific treatment and has been inaccessible to ML experts because of lack of training data and relevant, easy-to-use workflows. We present ClimSim, the largest-ever dataset designed for hybrid ML-physics research. It comprises multi-scale climate simulations, developed by a consortium of climate scientists and ML researchers. It consists of 5.7 billion pairs of multivariate input and output vectors that isolate the influence of locally-nested, high-resolution, high-fidelity physics on a host climate simulator's macro-scale physical state. The dataset is global in coverage, spans multiple years at high sampling frequency, and is designed such that resulting emulators are compatible with downstream coupling into operational climate simulators. We implement a range of deterministic and stochastic regression baselines to highlight the ML challenges and their scoring. The data (https://huggingface.co/datasets/LEAP/ClimSim_high-res) and code (https://leap-stc.github.io/ClimSim) are released openly to support the development of hybrid ML-physics and high-fidelity climate simulations for the benefit of science and society.