 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAVE: Premise-Aware Validation and Editing for Retrieval-Augmented LLMs
Mar 21, 2026Retrieval-augmented language models can retrieve relevant evidence yet still commit to answers before explicitly checking whether the retrieved context supports the conclusion. We present PAVE (Premise-Grounded Answer Validation and Editing), an inference-time validation layer for evidence-grounded question answering. PAVE decomposes retrieved context into question-conditioned atomic facts, drafts an answer, scores how well that draft is supported by the extracted premises, and revises low-support outputs before finalization. The resulting trace makes answer commitment auditable at the level of explicit premises, support scores, and revision decisions. In controlled ablations with a fixed retriever and backbone, PAVE outperforms simpler post-retrieval baselines in two evidence-grounded QA settings, with the largest gain reaching 32.7 accuracy points on a span-grounded benchmark. We view these findings as proof-of-concept evidence that explicit premise extraction plus support-gated revision can strengthen evidence-grounded consistency in retrieval-augmented LLM systems.
TensorCommitments: A Lightweight Verifiable Inference for Language Models
Feb 13, 2026Most large language models (LLMs) run on external clouds: users send a prompt, pay for inference, and must trust that the remote GPU executes the LLM without any adversarial tampering. We critically ask how to achieve verifiable LLM inference, where a prover (the service) must convince a verifier (the client) that an inference was run correctly without rerunning the LLM. Existing cryptographic works are too slow at the LLM scale, while non-cryptographic ones require a strong verifier GPU. We propose TensorCommitments (TCs), a tensor-native proof-of-inference scheme. TC binds the LLM inference to a commitment, an irreversible tag that breaks under tampering, organized in our multivariate Terkle Trees. For LLaMA2, TC adds only 0.97% prover and 0.12% verifier time over inference while improving robustness to tailored LLM attacks by up to 48% over the best prior work requiring a verifier GPU.
Multi-Agent Path Finding Among Dynamic Uncontrollable Agents with Statistical Safety Guarantees
Jul 29, 2025



Existing multi-agent path finding (MAPF) solvers do not account for uncertain behavior of uncontrollable agents. We present a novel variant of Enhanced Conflict-Based Search (ECBS), for both one-shot and lifelong MAPF in dynamic environments with uncontrollable agents. Our method consists of (1) training a learned predictor for the movement of uncontrollable agents, (2) quantifying the prediction error using conformal prediction (CP), a tool for statistical uncertainty quantification, and (3) integrating these uncertainty intervals into our modified ECBS solver. Our method can account for uncertain agent behavior, comes with statistical guarantees on collision-free paths for one-shot missions, and scales to lifelong missions with a receding horizon sequence of one-shot instances. We run our algorithm, CP-Solver, across warehouse and game maps, with competitive throughput and reduced collisions.
CAST: Time-Varying Treatment Effects with Application to Chemotherapy and Radiotherapy on Head and Neck Squamous Cell Carcinoma
May 09, 2025Causal machine learning (CML) enables individualized estimation of treatment effects, offering critical advantages over traditional correlation-based methods. However, existing approaches for medical survival data with censoring such as causal survival forests estimate effects at fixed time points, limiting their ability to capture dynamic changes over time. We introduce Causal Analysis for Survival Trajectories (CAST), a novel framework that models treatment effects as continuous functions of time following treatment. By combining parametric and non-parametric methods, CAST overcomes the limitations of discrete time-point analysis to estimate continuous effect trajectories. Using the RADCURE dataset [1] of 2,651 patients with head and neck squamous cell carcinoma (HNSCC) as a clinically relevant example, CAST models how chemotherapy and radiotherapy effects evolve over time at the population and individual levels. By capturing the temporal dynamics of treatment response, CAST reveals how treatment effects rise, peak, and decline over the follow-up period, helping clinicians determine when and for whom treatment benefits are maximized. This framework advances the application of CML to personalized care in HNSCC and other life-threatening medical conditions. Source code/data available at: https://github.com/CAST-FW/HNSCC
TxGemma: Efficient and Agentic LLMs for Therapeutics
Apr 08, 2025Therapeutic development is a costly and high-risk endeavor that is often plagued by high failure rates. To address this, we introduce TxGemma, a suite of efficient, generalist large language models (LLMs) capable of therapeutic property prediction as well as interactive reasoning and explainability. Unlike task-specific models, TxGemma synthesizes information from diverse sources, enabling broad application across the therapeutic development pipeline. The suite includes 2B, 9B, and 27B parameter models, fine-tuned from Gemma-2 on a comprehensive dataset of small molecules, proteins, nucleic acids, diseases, and cell lines. Across 66 therapeutic development tasks, TxGemma achieved superior or comparable performance to the state-of-the-art generalist model on 64 (superior on 45), and against state-of-the-art specialist models on 50 (superior on 26). Fine-tuning TxGemma models on therapeutic downstream tasks, such as clinical trial adverse event prediction, requires less training data than fine-tuning base LLMs, making TxGemma suitable for data-limited applications. Beyond these predictive capabilities, TxGemma features conversational models that bridge the gap between general LLMs and specialized property predictors. These allow scientists to interact in natural language, provide mechanistic reasoning for predictions based on molecular structure, and engage in scientific discussions. Building on this, we further introduce Agentic-Tx, a generalist therapeutic agentic system powered by Gemini 2.5 that reasons, acts, manages diverse workflows, and acquires external domain knowledge. Agentic-Tx surpasses prior leading models on the Humanity's Last Exam benchmark (Chemistry & Biology) with 52.3% relative improvement over o3-mini (high) and 26.7% over o3-mini (high) on GPQA (Chemistry) and excels with improvements of 6.3% (ChemBench-Preference) and 2.4% (ChemBench-Mini) over o3-mini (high).
Enough Coin Flips Can Make LLMs Act Bayesian
Mar 06, 2025Large language models (LLMs) exhibit the ability to generalize given few-shot examples in their input prompt, an emergent capability known as in-context learning (ICL). We investigate whether LLMs utilize ICL to perform structured reasoning in ways that are consistent with a Bayesian framework or rely on pattern matching. Using a controlled setting of biased coin flips, we find that: (1) LLMs often possess biased priors, causing initial divergence in zero-shot settings, (2) in-context evidence outweighs explicit bias instructions, (3) LLMs broadly follow Bayesian posterior updates, with deviations primarily due to miscalibrated priors rather than flawed updates, and (4) attention magnitude has negligible effect on Bayesian inference. With sufficient demonstrations of biased coin flips via ICL, LLMs update their priors in a Bayesian manner.
Tx-LLM: A Large Language Model for Therapeutics
Jun 10, 2024



Developing therapeutics is a lengthy and expensive process that requires the satisfaction of many different criteria, and AI models capable of expediting the process would be invaluable. However, the majority of current AI approaches address only a narrowly defined set of tasks, often circumscribed within a particular domain. To bridge this gap, we introduce Tx-LLM, a generalist large language model (LLM) fine-tuned from PaLM-2 which encodes knowledge about diverse therapeutic modalities. Tx-LLM is trained using a collection of 709 datasets that target 66 tasks spanning various stages of the drug discovery pipeline. Using a single set of weights, Tx-LLM simultaneously processes a wide variety of chemical or biological entities(small molecules, proteins, nucleic acids, cell lines, diseases) interleaved with free-text, allowing it to predict a broad range of associated properties, achieving competitive with state-of-the-art (SOTA) performance on 43 out of 66 tasks and exceeding SOTA on 22. Among these, Tx-LLM is particularly powerful and exceeds best-in-class performance on average for tasks combining molecular SMILES representations with text such as cell line names or disease names, likely due to context learned during pretraining. We observe evidence of positive transfer between tasks with diverse drug types (e.g.,tasks involving small molecules and tasks involving proteins), and we study the impact of model size, domain finetuning, and prompting strategies on performance. We believe Tx-LLM represents an important step towards LLMs encoding biochemical knowledge and could have a future role as an end-to-end tool across the drug discovery development pipeline.
Semantic Loss Functions for Neuro-Symbolic Structured Prediction
May 12, 2024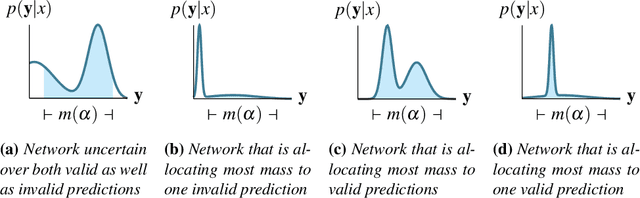
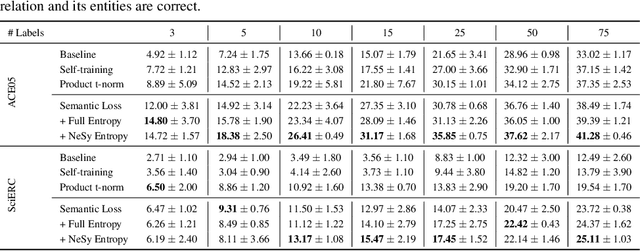
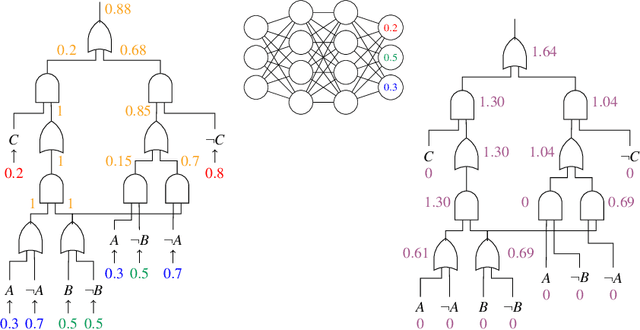
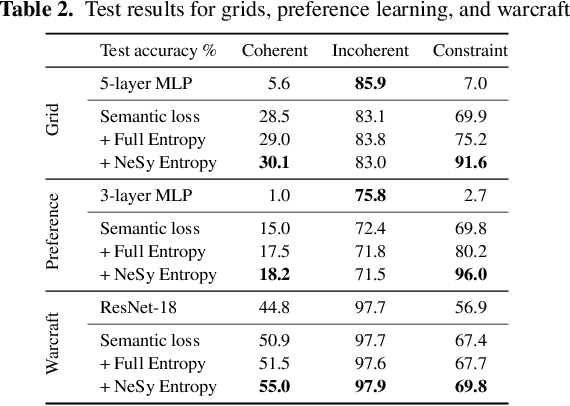
Structured output prediction problems are ubiquitous in machine learning. The prominent approach leverages neural networks as powerful feature extractors, otherwise assuming the independence of the outputs. These outputs, however, jointly encode an object, e.g. a path in a graph, and are therefore related through the structure underlying the output space. We discuss the semantic loss, which injects knowledge about such structure, defined symbolically, into training by minimizing the network's violation of such dependencies, steering the network towards predicting distributions satisfying the underlying structure. At the same time, it is agnostic to the arrangement of the symbols, and depends only on the semantics expressed thereby, while also enabling efficient end-to-end training and inference. We also discuss key improvements and applications of the semantic loss. One limitations of the semantic loss is that it does not exploit the association of every data point with certain features certifying its membership in a target class. We should therefore prefer minimum-entropy distributions over valid structures, which we obtain by additionally minimizing the neuro-symbolic entropy. We empirically demonstrate the benefits of this more refined formulation. Moreover, the semantic loss is designed to be modular and can be combined with both discriminative and generative neural models. This is illustrated by integrating it into generative adversarial networks, yielding constrained adversarial networks, a novel class of deep generative models able to efficiently synthesize complex objects obeying the structure of the underlying domain.
Advancing Multimodal Medical Capabilities of Gemini
May 06, 2024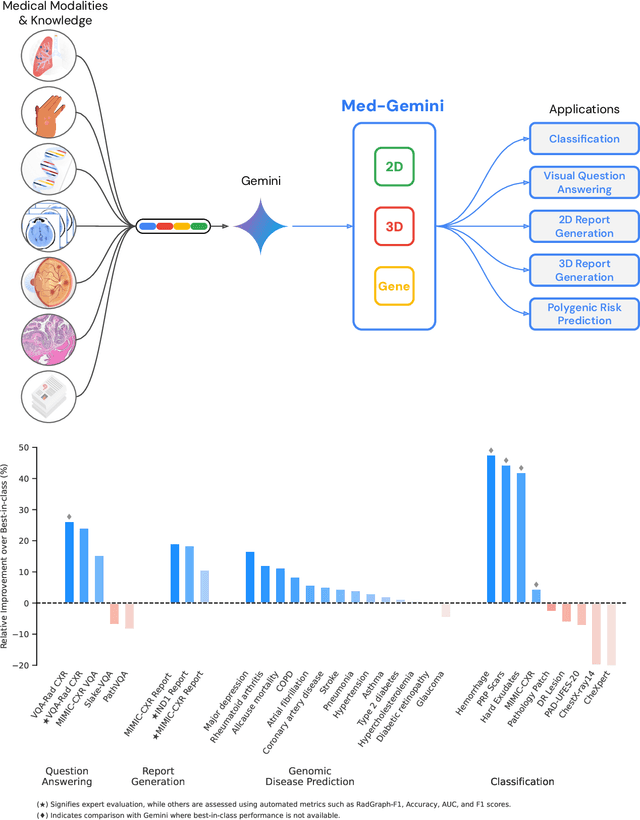
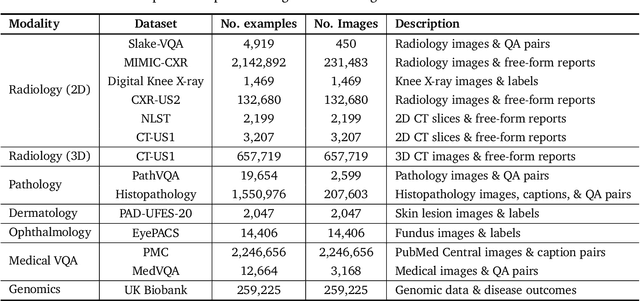

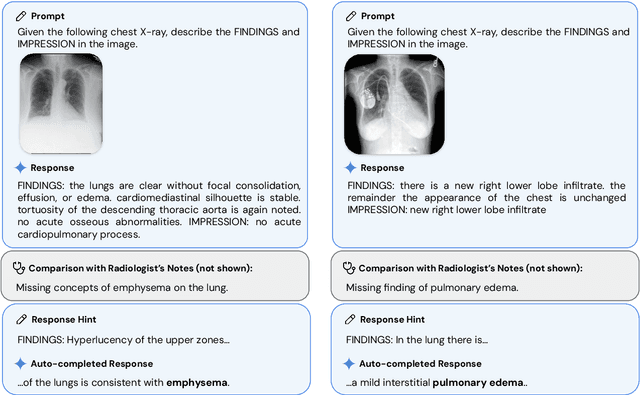
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as "equivalent or better" than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
Security and Privacy Product Inclusion
Apr 23, 2024In this paper, we explore the challenges of ensuring security and privacy for users from diverse demographic backgrounds. We propose a threat modeling approach to identify potential risks and countermeasures for product inclusion in security and privacy. We discuss various factors that can affect a user's ability to achieve a high level of security and privacy, including low-income demographics, poor connectivity, shared device usage, ML fairness, etc. We present results from a global security and privacy user experience survey and discuss the implications for product developers. Our work highlights the need for a more inclusive approach to security and privacy and provides a framework for researchers and practitioners to consider when designing products and services for a diverse range of users.