 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport Cards: Qualitative Evaluation of Language Models Using Natural Language Summaries
Sep 01, 2024
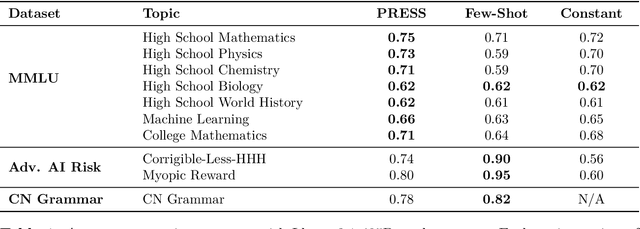
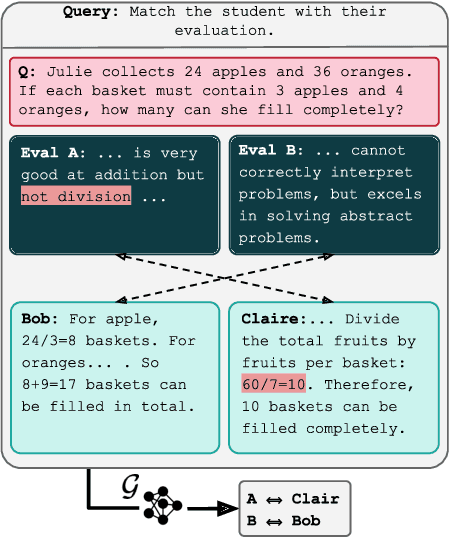
The rapid development and dynamic nature of large language models (LLMs) make it difficult for conventional quantitative benchmarks to accurately assess their capabilities. We propose report cards, which are human-interpretable, natural language summaries of model behavior for specific skills or topics. We develop a framework to evaluate report cards based on three criteria: specificity (ability to distinguish between models), faithfulness (accurate representation of model capabilities), and interpretability (clarity and relevance to humans). We also propose an iterative algorithm for generating report cards without human supervision and explore its efficacy by ablating various design choices. Through experimentation with popular LLMs, we demonstrate that report cards provide insights beyond traditional benchmarks and can help address the need for a more interpretable and holistic evaluation of LLMs.
Decomposed Prompting to Answer Questions on a Course Discussion Board
Jul 30, 2024We propose and evaluate a question-answering system that uses decomposed prompting to classify and answer student questions on a course discussion board. Our system uses a large language model (LLM) to classify questions into one of four types: conceptual, homework, logistics, and not answerable. This enables us to employ a different strategy for answering questions that fall under different types. Using a variant of GPT-3, we achieve $81\%$ classification accuracy. We discuss our system's performance on answering conceptual questions from a machine learning course and various failure modes.
* 6 pages. Published at International Conference on Artificial Intelligence in Education 2023. Code repository: https://github.com/brandonjaipersaud/piazza-qabot-gpt
BEADs: Bias Evaluation Across Domains
Jun 07, 2024



Recent improvements in large language models (LLMs) have significantly enhanced natural language processing (NLP) applications. However, these models can also inherit and perpetuate biases from their training data. Addressing this issue is crucial, yet many existing datasets do not offer evaluation across diverse NLP tasks. To tackle this, we introduce the Bias Evaluations Across Domains (BEADs) dataset, designed to support a wide range of NLP tasks, including text classification, bias entity recognition, bias quantification, and benign language generation. BEADs uses AI-driven annotation combined with experts' verification to provide reliable labels. This method overcomes the limitations of existing datasets that typically depend on crowd-sourcing, expert-only annotations with limited bias evaluations, or unverified AI labeling. Our empirical analysis shows that BEADs is effective in detecting and reducing biases across different language models, with smaller models fine-tuned on BEADs often outperforming LLMs in bias classification tasks. However, these models may still exhibit biases towards certain demographics. Fine-tuning LLMs with our benign language data also reduces biases while preserving the models' knowledge. Our findings highlight the importance of comprehensive bias evaluation and the potential of targeted fine-tuning for reducing the bias of LLMs. We are making BEADs publicly available at https://huggingface.co/datasets/shainar/BEAD Warning: This paper contains examples that may be considered offensive.
Unlearnable Algorithms for In-context Learning
Feb 01, 2024Machine unlearning is a desirable operation as models get increasingly deployed on data with unknown provenance. However, achieving exact unlearning -- obtaining a model that matches the model distribution when the data to be forgotten was never used -- is challenging or inefficient, often requiring significant retraining. In this paper, we focus on efficient unlearning methods for the task adaptation phase of a pretrained large language model (LLM). We observe that an LLM's ability to do in-context learning for task adaptation allows for efficient exact unlearning of task adaptation training data. We provide an algorithm for selecting few-shot training examples to prepend to the prompt given to an LLM (for task adaptation), ERASE, whose unlearning operation cost is independent of model and dataset size, meaning it scales to large models and datasets. We additionally compare our approach to fine-tuning approaches and discuss the trade-offs between the two approaches. This leads us to propose a new holistic measure of unlearning cost which accounts for varying inference costs, and conclude that in-context learning can often be more favourable than fine-tuning for deployments involving unlearning requests.
Using Large Language Models for Hyperparameter Optimization
Dec 07, 2023



This paper studies using foundational large language models (LLMs) to make decisions during hyperparameter optimization (HPO). Empirical evaluations demonstrate that in settings with constrained search budgets, LLMs can perform comparably or better than traditional HPO methods like random search and Bayesian optimization on standard benchmarks. Furthermore, we propose to treat the code specifying our model as a hyperparameter, which the LLM outputs, going beyond the capabilities of existing HPO approaches. Our findings suggest that LLMs are a promising tool for improving efficiency in the traditional decision-making problem of hyperparameter optimization.
Boosted Prompt Ensembles for Large Language Models
Apr 12, 2023



Methods such as chain-of-thought prompting and self-consistency have pushed the frontier of language model reasoning performance with no additional training. To further improve performance, we propose a prompt ensembling method for large language models, which uses a small dataset to construct a set of few shot prompts that together comprise a ``boosted prompt ensemble''. The few shot examples for each prompt are chosen in a stepwise fashion to be ``hard'' examples on which the previous step's ensemble is uncertain. We show that this outperforms single-prompt output-space ensembles and bagged prompt-space ensembles on the GSM8k and AQuA datasets, among others. We propose both train-time and test-time versions of boosted prompting that use different levels of available annotation and conduct a detailed empirical study of our algorithm.
Multi-Rate VAE: Train Once, Get the Full Rate-Distortion Curve
Dec 07, 2022
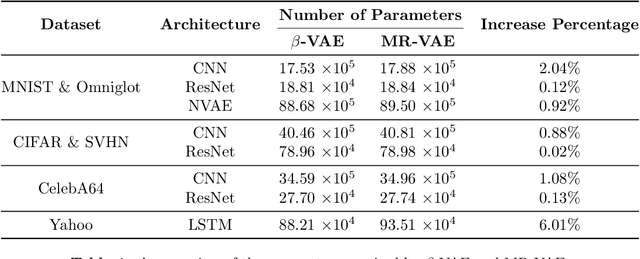


Variational autoencoders (VAEs) are powerful tools for learning latent representations of data used in a wide range of applications. In practice, VAEs usually require multiple training rounds to choose the amount of information the latent variable should retain. This trade-off between the reconstruction error (distortion) and the KL divergence (rate) is typically parameterized by a hyperparameter $\beta$. In this paper, we introduce Multi-Rate VAE (MR-VAE), a computationally efficient framework for learning optimal parameters corresponding to various $\beta$ in a single training run. The key idea is to explicitly formulate a response function that maps $\beta$ to the optimal parameters using hypernetworks. MR-VAEs construct a compact response hypernetwork where the pre-activations are conditionally gated based on $\beta$. We justify the proposed architecture by analyzing linear VAEs and showing that it can represent response functions exactly for linear VAEs. With the learned hypernetwork, MR-VAEs can construct the rate-distortion curve without additional training and can be deployed with significantly less hyperparameter tuning. Empirically, our approach is competitive and often exceeds the performance of multiple $\beta$-VAEs training with minimal computation and memory overheads.
Learning Domain Invariant Representations in Goal-conditioned Block MDPs
Oct 28, 2021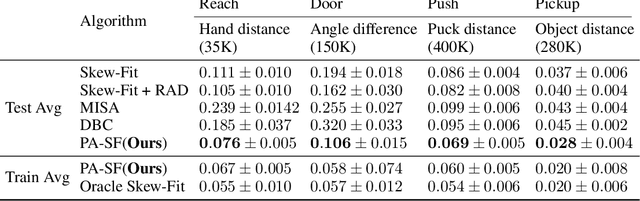
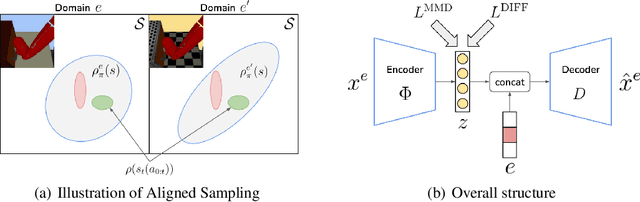

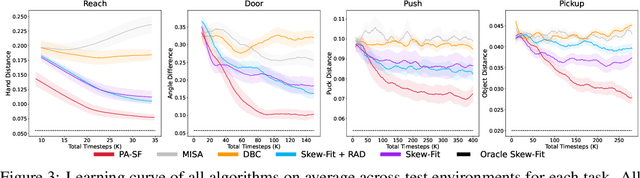
Deep Reinforcement Learning (RL) is successful in solving many complex Markov Decision Processes (MDPs) problems. However, agents often face unanticipated environmental changes after deployment in the real world. These changes are often spurious and unrelated to the underlying problem, such as background shifts for visual input agents. Unfortunately, deep RL policies are usually sensitive to these changes and fail to act robustly against them. This resembles the problem of domain generalization in supervised learning. In this work, we study this problem for goal-conditioned RL agents. We propose a theoretical framework in the Block MDP setting that characterizes the generalizability of goal-conditioned policies to new environments. Under this framework, we develop a practical method PA-SkewFit that enhances domain generalization. The empirical evaluation shows that our goal-conditioned RL agent can perform well in various unseen test environments, improving by 50% over baselines.
* 33 pages
Autoregressive Dynamics Models for Offline Policy Evaluation and Optimization
Apr 28, 2021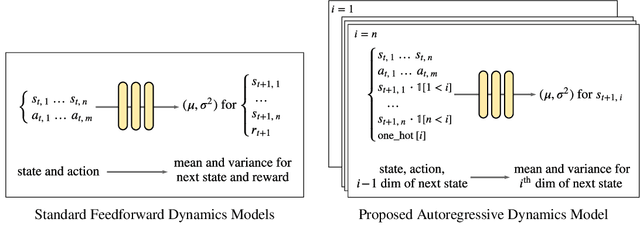

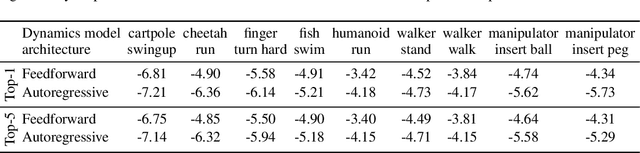
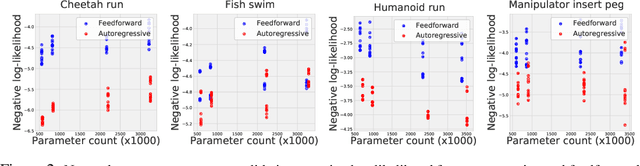
Standard dynamics models for continuous control make use of feedforward computation to predict the conditional distribution of next state and reward given current state and action using a multivariate Gaussian with a diagonal covariance structure. This modeling choice assumes that different dimensions of the next state and reward are conditionally independent given the current state and action and may be driven by the fact that fully observable physics-based simulation environments entail deterministic transition dynamics. In this paper, we challenge this conditional independence assumption and propose a family of expressive autoregressive dynamics models that generate different dimensions of the next state and reward sequentially conditioned on previous dimensions. We demonstrate that autoregressive dynamics models indeed outperform standard feedforward models in log-likelihood on heldout transitions. Furthermore, we compare different model-based and model-free off-policy evaluation (OPE) methods on RL Unplugged, a suite of offline MuJoCo datasets, and find that autoregressive dynamics models consistently outperform all baselines, achieving a new state-of-the-art. Finally, we show that autoregressive dynamics models are useful for offline policy optimization by serving as a way to enrich the replay buffer through data augmentation and improving performance using model-based planning.
Analyzing Monotonic Linear Interpolation in Neural Network Loss Landscapes
Apr 23, 2021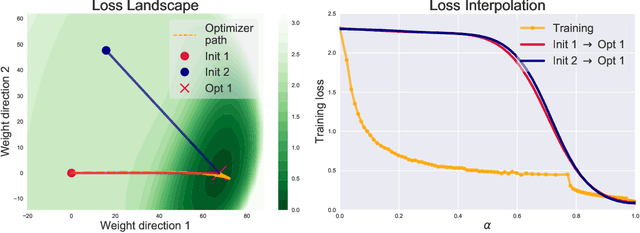



Linear interpolation between initial neural network parameters and converged parameters after training with stochastic gradient descent (SGD) typically leads to a monotonic decrease in the training objective. This Monotonic Linear Interpolation (MLI) property, first observed by Goodfellow et al. (2014) persists in spite of the non-convex objectives and highly non-linear training dynamics of neural networks. Extending this work, we evaluate several hypotheses for this property that, to our knowledge, have not yet been explored. Using tools from differential geometry, we draw connections between the interpolated paths in function space and the monotonicity of the network - providing sufficient conditions for the MLI property under mean squared error. While the MLI property holds under various settings (e.g. network architectures and learning problems), we show in practice that networks violating the MLI property can be produced systematically, by encouraging the weights to move far from initialization. The MLI property raises important questions about the loss landscape geometry of neural networks and highlights the need to further study their global properties.