 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA OmniDreams: Real-Time Generative World Model for Closed-Loop Autonomous Vehicle Simulation
Jun 02, 2026As autonomous vehicle capabilities advance, the safe evaluation of driving policies in long-tail scenarios remains a critical bottleneck. In closed-loop simulation, the driving policy model actively interacts with the environment, where its actions dynamically update the simulator state and directly influence the next set of generated sensor observations. While recent reconstruction-based neural simulators offer photorealism, they are fundamentally constrained by their initial captured data and struggle to generalize to highly dynamic or novel scenes. To overcome these limitations, we introduce OmniDreams, a foundation generative world model mid- and post-trained from the Cosmos diffusion model to autoregressively generate action-conditioned videos in real time. By leveraging the rich visual priors of Cosmos and mid- and post-training on 21k hours of driving scenarios, OmniDreams synthesizes complex, unobserved phenomena that are hard for traditional simulators to capture, such as extreme weather and unpredictable dynamic agent behaviors. Crucially, it autoregressively conditions its photorealistic sensor generation on past frames, the current simulator state, and immediate driving actions. Deployed in a closed-loop system with the Alpamayo 1 policy model and AlpaSim orchestrator, OmniDreams acts as a highly responsive, reactive environment, providing a scalable and comprehensive solution for training and evaluating next-generation autonomous driving policies. We additionally show preliminary results indicating that a world-action model (WAM) post-trained from OmniDreams achieves strong performance on the Physical AI Autonomous Vehicles NuRec dataset, surpassing the VLA-based Alpamayo 1.5 research policy model while using only 1/5 the total parameters. These results highlight the potential for a real-time world model like OmniDreams to also serve as a backbone for policy architectures.
Variance Reduction for Expectations with Diffusion Teachers
May 20, 2026Pretrained diffusion models serve as frozen teachers feeding downstream pipelines such as text-to-3D, single-step distillation, and data attribution. The teacher gradients these pipelines consume are Monte Carlo (MC) expectations over noise levels and Gaussian noise samples; their estimator variance dominates compute cost because each draw requires expensive upstream work (rendering, simulation, encoding). We introduce CARV, a compute-aware variance-accounting framework that motivates a hierarchical MC estimator: amortize the expensive upstream computation over cheap diffusion-noise resamples, sharpened by timestep importance sampling and a stratified-inverse-CDF construction. In our text-to-3D distillation and attribution experiments, CARV delivers 2-3x effective compute multipliers (most from amortized reuse; ~25% additional from IS+stratification) without changing the objective; in single-step distillation, the same techniques cut gradient variance by an order of magnitude but do not improve downstream FID, marking the regime where MC variance is no longer the bottleneck.
Motion Attribution for Video Generation
Jan 13, 2026Despite the rapid progress of video generation models, the role of data in influencing motion is poorly understood. We present Motive (MOTIon attribution for Video gEneration), a motion-centric, gradient-based data attribution framework that scales to modern, large, high-quality video datasets and models. We use this to study which fine-tuning clips improve or degrade temporal dynamics. Motive isolates temporal dynamics from static appearance via motion-weighted loss masks, yielding efficient and scalable motion-specific influence computation. On text-to-video models, Motive identifies clips that strongly affect motion and guides data curation that improves temporal consistency and physical plausibility. With Motive-selected high-influence data, our method improves both motion smoothness and dynamic degree on VBench, achieving a 74.1% human preference win rate compared with the pretrained base model. To our knowledge, this is the first framework to attribute motion rather than visual appearance in video generative models and to use it to curate fine-tuning data.
Score Distillation Sampling for Audio: Source Separation, Synthesis, and Beyond
May 07, 2025We introduce Audio-SDS, a generalization of Score Distillation Sampling (SDS) to text-conditioned audio diffusion models. While SDS was initially designed for text-to-3D generation using image diffusion, its core idea of distilling a powerful generative prior into a separate parametric representation extends to the audio domain. Leveraging a single pretrained model, Audio-SDS enables a broad range of tasks without requiring specialized datasets. In particular, we demonstrate how Audio-SDS can guide physically informed impact sound simulations, calibrate FM-synthesis parameters, and perform prompt-specified source separation. Our findings illustrate the versatility of distillation-based methods across modalities and establish a robust foundation for future work using generative priors in audio tasks.
LLaMA-Mesh: Unifying 3D Mesh Generation with Language Models
Nov 14, 2024



This work explores expanding the capabilities of large language models (LLMs) pretrained on text to generate 3D meshes within a unified model. This offers key advantages of (1) leveraging spatial knowledge already embedded in LLMs, derived from textual sources like 3D tutorials, and (2) enabling conversational 3D generation and mesh understanding. A primary challenge is effectively tokenizing 3D mesh data into discrete tokens that LLMs can process seamlessly. To address this, we introduce LLaMA-Mesh, a novel approach that represents the vertex coordinates and face definitions of 3D meshes as plain text, allowing direct integration with LLMs without expanding the vocabulary. We construct a supervised fine-tuning (SFT) dataset enabling pretrained LLMs to (1) generate 3D meshes from text prompts, (2) produce interleaved text and 3D mesh outputs as required, and (3) understand and interpret 3D meshes. Our work is the first to demonstrate that LLMs can be fine-tuned to acquire complex spatial knowledge for 3D mesh generation in a text-based format, effectively unifying the 3D and text modalities. LLaMA-Mesh achieves mesh generation quality on par with models trained from scratch while maintaining strong text generation performance.
Multi-student Diffusion Distillation for Better One-step Generators
Oct 30, 2024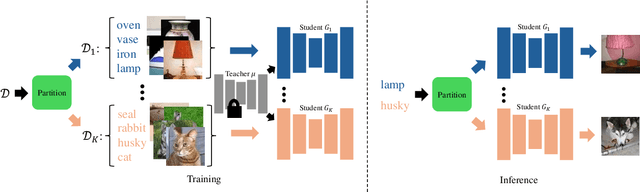


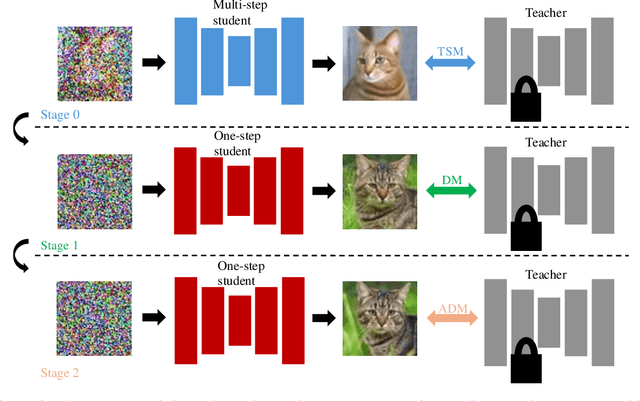
Diffusion models achieve high-quality sample generation at the cost of a lengthy multistep inference procedure. To overcome this, diffusion distillation techniques produce student generators capable of matching or surpassing the teacher in a single step. However, the student model's inference speed is limited by the size of the teacher architecture, preventing real-time generation for computationally heavy applications. In this work, we introduce Multi-Student Distillation (MSD), a framework to distill a conditional teacher diffusion model into multiple single-step generators. Each student generator is responsible for a subset of the conditioning data, thereby obtaining higher generation quality for the same capacity. MSD trains multiple distilled students, allowing smaller sizes and, therefore, faster inference. Also, MSD offers a lightweight quality boost over single-student distillation with the same architecture. We demonstrate MSD is effective by training multiple same-sized or smaller students on single-step distillation using distribution matching and adversarial distillation techniques. With smaller students, MSD gets competitive results with faster inference for single-step generation. Using 4 same-sized students, MSD sets a new state-of-the-art for one-step image generation: FID 1.20 on ImageNet-64x64 and 8.20 on zero-shot COCO2014.
JacNet: Learning Functions with Structured Jacobians
Aug 23, 2024


Neural networks are trained to learn an approximate mapping from an input domain to a target domain. Incorporating prior knowledge about true mappings is critical to learning a useful approximation. With current architectures, it is challenging to enforce structure on the derivatives of the input-output mapping. We propose to use a neural network to directly learn the Jacobian of the input-output function, which allows easy control of the derivative. We focus on structuring the derivative to allow invertibility and also demonstrate that other useful priors, such as $k$-Lipschitz, can be enforced. Using this approach, we can learn approximations to simple functions that are guaranteed to be invertible and easily compute the inverse. We also show similar results for 1-Lipschitz functions.
Scalable Nested Optimization for Deep Learning
Jul 01, 2024

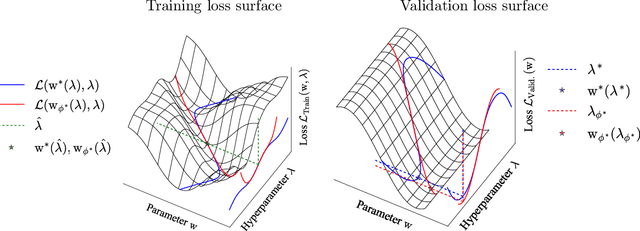
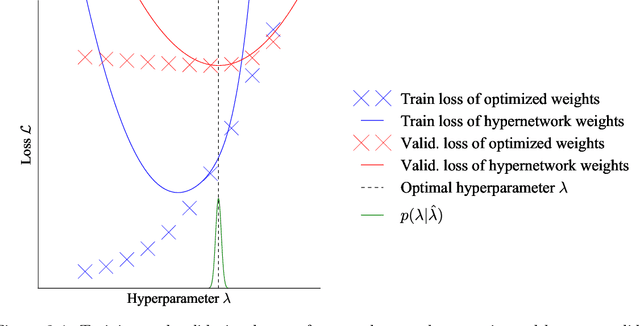
Gradient-based optimization has been critical to the success of machine learning, updating a single set of parameters to minimize a single loss. A growing number of applications rely on a generalization of this, where we have a bilevel or nested optimization of which subsets of parameters update on different objectives nested inside each other. We focus on motivating examples of hyperparameter optimization and generative adversarial networks. However, naively applying classical methods often fails when we look at solving these nested problems on a large scale. In this thesis, we build tools for nested optimization that scale to deep learning setups.
Improving Hyperparameter Optimization with Checkpointed Model Weights
Jun 26, 2024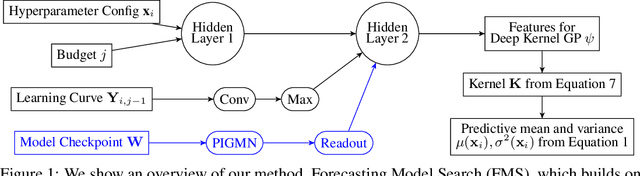
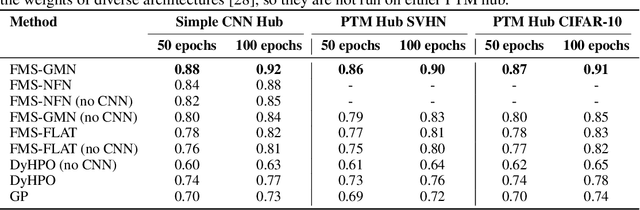
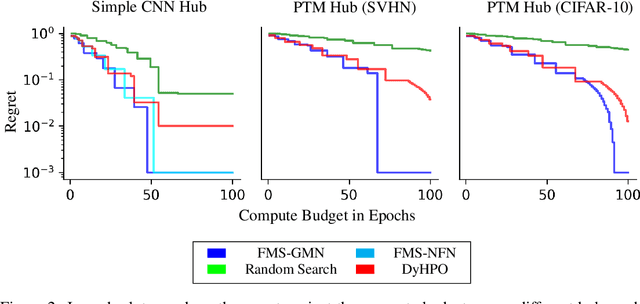

When training deep learning models, the performance depends largely on the selected hyperparameters. However, hyperparameter optimization (HPO) is often one of the most expensive parts of model design. Classical HPO methods treat this as a black-box optimization problem. However, gray-box HPO methods, which incorporate more information about the setup, have emerged as a promising direction for more efficient optimization. For example, using intermediate loss evaluations to terminate bad selections. In this work, we propose an HPO method for neural networks using logged checkpoints of the trained weights to guide future hyperparameter selections. Our method, Forecasting Model Search (FMS), embeds weights into a Gaussian process deep kernel surrogate model, using a permutation-invariant graph metanetwork to be data-efficient with the logged network weights. To facilitate reproducibility and further research, we open-source our code at https://github.com/NVlabs/forecasting-model-search.
Training Data Attribution via Approximate Unrolled Differentiation
May 21, 2024



Many training data attribution (TDA) methods aim to estimate how a model's behavior would change if one or more data points were removed from the training set. Methods based on implicit differentiation, such as influence functions, can be made computationally efficient, but fail to account for underspecification, the implicit bias of the optimization algorithm, or multi-stage training pipelines. By contrast, methods based on unrolling address these issues but face scalability challenges. In this work, we connect the implicit-differentiation-based and unrolling-based approaches and combine their benefits by introducing Source, an approximate unrolling-based TDA method that is computed using an influence-function-like formula. While being computationally efficient compared to unrolling-based approaches, Source is suitable in cases where implicit-differentiation-based approaches struggle, such as in non-converged models and multi-stage training pipelines. Empirically, Source outperforms existing TDA techniques in counterfactual prediction, especially in settings where implicit-differentiation-based approaches fall short.