 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Chain of Thought Fails in Clinical Text Understanding
Sep 26, 2025Large language models (LLMs) are increasingly being applied to clinical care, a domain where both accuracy and transparent reasoning are critical for safe and trustworthy deployment. Chain-of-thought (CoT) prompting, which elicits step-by-step reasoning, has demonstrated improvements in performance and interpretability across a wide range of tasks. However, its effectiveness in clinical contexts remains largely unexplored, particularly in the context of electronic health records (EHRs), the primary source of clinical documentation, which are often lengthy, fragmented, and noisy. In this work, we present the first large-scale systematic study of CoT for clinical text understanding. We assess 95 advanced LLMs on 87 real-world clinical text tasks, covering 9 languages and 8 task types. Contrary to prior findings in other domains, we observe that 86.3\% of models suffer consistent performance degradation in the CoT setting. More capable models remain relatively robust, while weaker ones suffer substantial declines. To better characterize these effects, we perform fine-grained analyses of reasoning length, medical concept alignment, and error profiles, leveraging both LLM-as-a-judge evaluation and clinical expert evaluation. Our results uncover systematic patterns in when and why CoT fails in clinical contexts, which highlight a critical paradox: CoT enhances interpretability but may undermine reliability in clinical text tasks. This work provides an empirical basis for clinical reasoning strategies of LLMs, highlighting the need for transparent and trustworthy approaches.
BRIDGE: Benchmarking Large Language Models for Understanding Real-world Clinical Practice Text
May 01, 2025



Large language models (LLMs) hold great promise for medical applications and are evolving rapidly, with new models being released at an accelerated pace. However, current evaluations of LLMs in clinical contexts remain limited. Most existing benchmarks rely on medical exam-style questions or PubMed-derived text, failing to capture the complexity of real-world electronic health record (EHR) data. Others focus narrowly on specific application scenarios, limiting their generalizability across broader clinical use. To address this gap, we present BRIDGE, a comprehensive multilingual benchmark comprising 87 tasks sourced from real-world clinical data sources across nine languages. We systematically evaluated 52 state-of-the-art LLMs (including DeepSeek-R1, GPT-4o, Gemini, and Llama 4) under various inference strategies. With a total of 13,572 experiments, our results reveal substantial performance variation across model sizes, languages, natural language processing tasks, and clinical specialties. Notably, we demonstrate that open-source LLMs can achieve performance comparable to proprietary models, while medically fine-tuned LLMs based on older architectures often underperform versus updated general-purpose models. The BRIDGE and its corresponding leaderboard serve as a foundational resource and a unique reference for the development and evaluation of new LLMs in real-world clinical text understanding. The BRIDGE leaderboard: https://huggingface.co/spaces/YLab-Open/BRIDGE-Medical-Leaderboard
VideoPanda: Video Panoramic Diffusion with Multi-view Attention
Apr 15, 2025High resolution panoramic video content is paramount for immersive experiences in Virtual Reality, but is non-trivial to collect as it requires specialized equipment and intricate camera setups. In this work, we introduce VideoPanda, a novel approach for synthesizing 360$^\circ$ videos conditioned on text or single-view video data. VideoPanda leverages multi-view attention layers to augment a video diffusion model, enabling it to generate consistent multi-view videos that can be combined into immersive panoramic content. VideoPanda is trained jointly using two conditions: text-only and single-view video, and supports autoregressive generation of long-videos. To overcome the computational burden of multi-view video generation, we randomly subsample the duration and camera views used during training and show that the model is able to gracefully generalize to generating more frames during inference. Extensive evaluations on both real-world and synthetic video datasets demonstrate that VideoPanda generates more realistic and coherent 360$^\circ$ panoramas across all input conditions compared to existing methods. Visit the project website at https://research-staging.nvidia.com/labs/toronto-ai/VideoPanda/ for results.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
L4GM: Large 4D Gaussian Reconstruction Model
Jun 14, 2024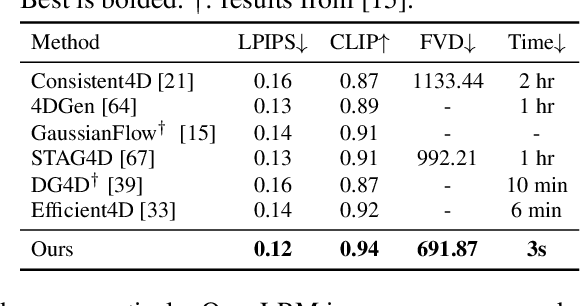
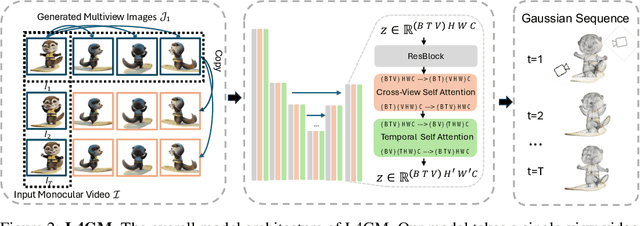
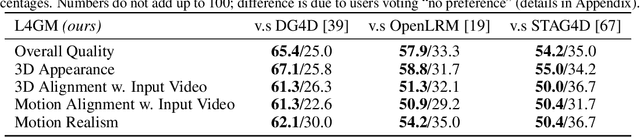
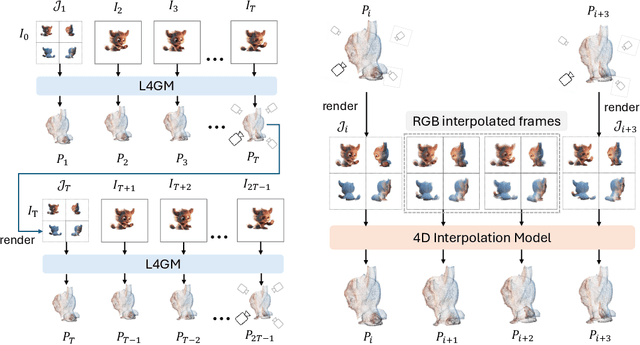
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
LATTE3D: Large-scale Amortized Text-To-Enhanced3D Synthesis
Mar 22, 2024


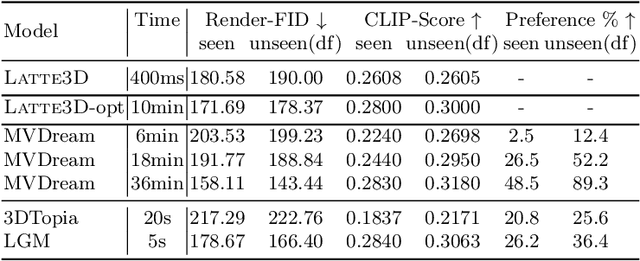
Recent text-to-3D generation approaches produce impressive 3D results but require time-consuming optimization that can take up to an hour per prompt. Amortized methods like ATT3D optimize multiple prompts simultaneously to improve efficiency, enabling fast text-to-3D synthesis. However, they cannot capture high-frequency geometry and texture details and struggle to scale to large prompt sets, so they generalize poorly. We introduce LATTE3D, addressing these limitations to achieve fast, high-quality generation on a significantly larger prompt set. Key to our method is 1) building a scalable architecture and 2) leveraging 3D data during optimization through 3D-aware diffusion priors, shape regularization, and model initialization to achieve robustness to diverse and complex training prompts. LATTE3D amortizes both neural field and textured surface generation to produce highly detailed textured meshes in a single forward pass. LATTE3D generates 3D objects in 400ms, and can be further enhanced with fast test-time optimization.
Generating Transferable Adversarial Simulation Scenarios for Self-Driving via Neural Rendering
Sep 27, 2023
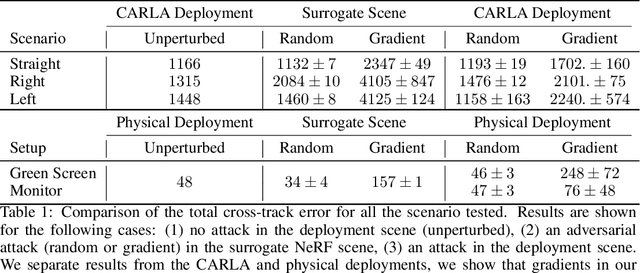
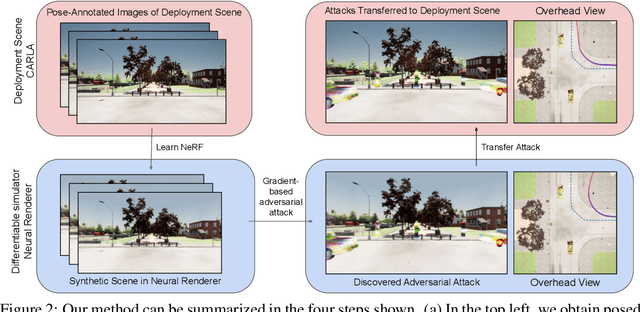

Self-driving software pipelines include components that are learned from a significant number of training examples, yet it remains challenging to evaluate the overall system's safety and generalization performance. Together with scaling up the real-world deployment of autonomous vehicles, it is of critical importance to automatically find simulation scenarios where the driving policies will fail. We propose a method that efficiently generates adversarial simulation scenarios for autonomous driving by solving an optimal control problem that aims to maximally perturb the policy from its nominal trajectory. Given an image-based driving policy, we show that we can inject new objects in a neural rendering representation of the deployment scene, and optimize their texture in order to generate adversarial sensor inputs to the policy. We demonstrate that adversarial scenarios discovered purely in the neural renderer (surrogate scene) can often be successfully transferred to the deployment scene, without further optimization. We demonstrate this transfer occurs both in simulated and real environments, provided the learned surrogate scene is sufficiently close to the deployment scene.
ATT3D: Amortized Text-to-3D Object Synthesis
Jun 06, 2023



Text-to-3D modelling has seen exciting progress by combining generative text-to-image models with image-to-3D methods like Neural Radiance Fields. DreamFusion recently achieved high-quality results but requires a lengthy, per-prompt optimization to create 3D objects. To address this, we amortize optimization over text prompts by training on many prompts simultaneously with a unified model, instead of separately. With this, we share computation across a prompt set, training in less time than per-prompt optimization. Our framework - Amortized text-to-3D (ATT3D) - enables knowledge-sharing between prompts to generalize to unseen setups and smooth interpolations between text for novel assets and simple animations.
Physics-based Human Motion Estimation and Synthesis from Videos
Sep 21, 2021
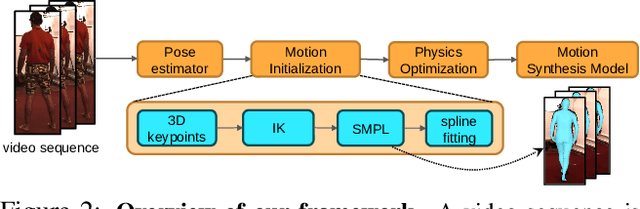


Human motion synthesis is an important problem with applications in graphics, gaming and simulation environments for robotics. Existing methods require accurate motion capture data for training, which is costly to obtain. Instead, we propose a framework for training generative models of physically plausible human motion directly from monocular RGB videos, which are much more widely available. At the core of our method is a novel optimization formulation that corrects imperfect image-based pose estimations by enforcing physics constraints and reasons about contacts in a differentiable way. This optimization yields corrected 3D poses and motions, as well as their corresponding contact forces. Results show that our physically-corrected motions significantly outperform prior work on pose estimation. We can then use these to train a generative model to synthesize future motion. We demonstrate both qualitatively and quantitatively significantly improved motion estimation, synthesis quality and physical plausibility achieved by our method on the large scale Human3.6m dataset \cite{h36m_pami} as compared to prior kinematic and physics-based methods. By enabling learning of motion synthesis from video, our method paves the way for large-scale, realistic and diverse motion synthesis.
KAMA: 3D Keypoint Aware Body Mesh Articulation
Apr 27, 2021

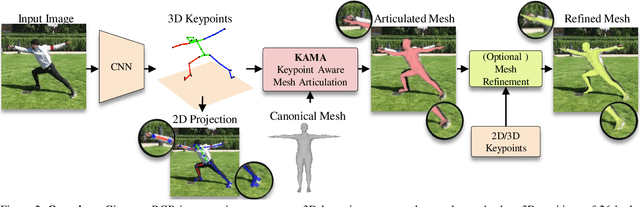

We present KAMA, a 3D Keypoint Aware Mesh Articulation approach that allows us to estimate a human body mesh from the positions of 3D body keypoints. To this end, we learn to estimate 3D positions of 26 body keypoints and propose an analytical solution to articulate a parametric body model, SMPL, via a set of straightforward geometric transformations. Since keypoint estimation directly relies on image clues, our approach offers significantly better alignment to image content when compared to state-of-the-art approaches. Our proposed approach does not require any paired mesh annotations and is able to achieve state-of-the-art mesh fittings through 3D keypoint regression only. Results on the challenging 3DPW and Human3.6M demonstrate that our approach yields state-of-the-art body mesh fittings.