 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideoPanda: Video Panoramic Diffusion with Multi-view Attention
Apr 15, 2025High resolution panoramic video content is paramount for immersive experiences in Virtual Reality, but is non-trivial to collect as it requires specialized equipment and intricate camera setups. In this work, we introduce VideoPanda, a novel approach for synthesizing 360$^\circ$ videos conditioned on text or single-view video data. VideoPanda leverages multi-view attention layers to augment a video diffusion model, enabling it to generate consistent multi-view videos that can be combined into immersive panoramic content. VideoPanda is trained jointly using two conditions: text-only and single-view video, and supports autoregressive generation of long-videos. To overcome the computational burden of multi-view video generation, we randomly subsample the duration and camera views used during training and show that the model is able to gracefully generalize to generating more frames during inference. Extensive evaluations on both real-world and synthetic video datasets demonstrate that VideoPanda generates more realistic and coherent 360$^\circ$ panoramas across all input conditions compared to existing methods. Visit the project website at https://research-staging.nvidia.com/labs/toronto-ai/VideoPanda/ for results.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
ReMatching Dynamic Reconstruction Flow
Nov 01, 2024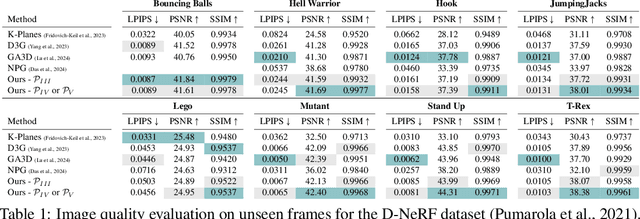
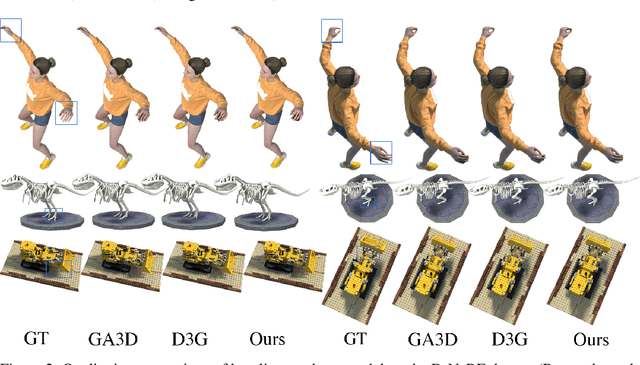
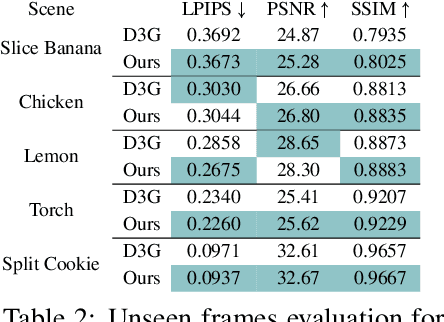

Reconstructing dynamic scenes from image inputs is a fundamental computer vision task with many downstream applications. Despite recent advancements, existing approaches still struggle to achieve high-quality reconstructions from unseen viewpoints and timestamps. This work introduces the ReMatching framework, designed to improve generalization quality by incorporating deformation priors into dynamic reconstruction models. Our approach advocates for velocity-field-based priors, for which we suggest a matching procedure that can seamlessly supplement existing dynamic reconstruction pipelines. The framework is highly adaptable and can be applied to various dynamic representations. Moreover, it supports integrating multiple types of model priors and enables combining simpler ones to create more complex classes. Our evaluations on popular benchmarks involving both synthetic and real-world dynamic scenes demonstrate a clear improvement in reconstruction accuracy of current state-of-the-art models.
PASTA: Controllable Part-Aware Shape Generation with Autoregressive Transformers
Jul 18, 2024
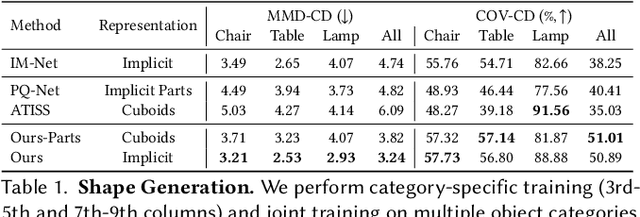


The increased demand for tools that automate the 3D content creation process led to tremendous progress in deep generative models that can generate diverse 3D objects of high fidelity. In this paper, we present PASTA, an autoregressive transformer architecture for generating high quality 3D shapes. PASTA comprises two main components: An autoregressive transformer that generates objects as a sequence of cuboidal primitives and a blending network, implemented with a transformer decoder that composes the sequences of cuboids and synthesizes high quality meshes for each object. Our model is trained in two stages: First we train our autoregressive generative model using only annotated cuboidal parts as supervision and next, we train our blending network using explicit 3D supervision, in the form of watertight meshes. Evaluations on various ShapeNet objects showcase the ability of our model to perform shape generation from diverse inputs \eg from scratch, from a partial object, from text and images, as well size-guided generation, by explicitly conditioning on a bounding box that defines the object's boundaries. Moreover, as our model considers the underlying part-based structure of a 3D object, we are able to select a specific part and produce shapes with meaningful variations of this part. As evidenced by our experiments, our model generates 3D shapes that are both more realistic and diverse than existing part-based and non part-based methods, while at the same time is simpler to implement and train.
MultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Apr 18, 2024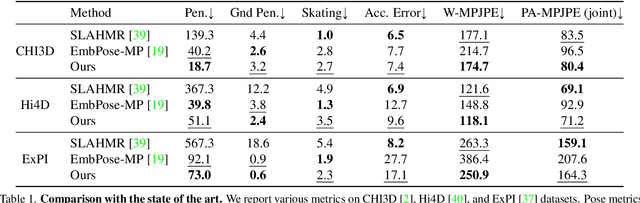

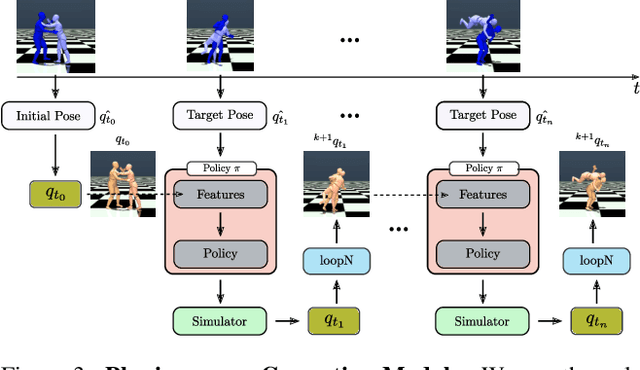
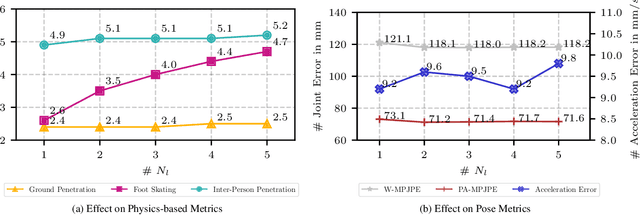
We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
CAD: Photorealistic 3D Generation via Adversarial Distillation
Dec 11, 2023



The increased demand for 3D data in AR/VR, robotics and gaming applications, gave rise to powerful generative pipelines capable of synthesizing high-quality 3D objects. Most of these models rely on the Score Distillation Sampling (SDS) algorithm to optimize a 3D representation such that the rendered image maintains a high likelihood as evaluated by a pre-trained diffusion model. However, finding a correct mode in the high-dimensional distribution produced by the diffusion model is challenging and often leads to issues such as over-saturation, over-smoothing, and Janus-like artifacts. In this paper, we propose a novel learning paradigm for 3D synthesis that utilizes pre-trained diffusion models. Instead of focusing on mode-seeking, our method directly models the distribution discrepancy between multi-view renderings and diffusion priors in an adversarial manner, which unlocks the generation of high-fidelity and photorealistic 3D content, conditioned on a single image and prompt. Moreover, by harnessing the latent space of GANs and expressive diffusion model priors, our method facilitates a wide variety of 3D applications including single-view reconstruction, high diversity generation and continuous 3D interpolation in the open domain. The experiments demonstrate the superiority of our pipeline compared to previous works in terms of generation quality and diversity.
CurveCloudNet: Processing Point Clouds with 1D Structure
Mar 21, 2023


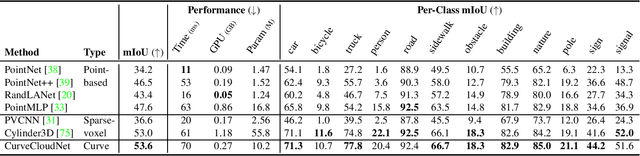
Modern depth sensors such as LiDAR operate by sweeping laser-beams across the scene, resulting in a point cloud with notable 1D curve-like structures. In this work, we introduce a new point cloud processing scheme and backbone, called CurveCloudNet, which takes advantage of the curve-like structure inherent to these sensors. While existing backbones discard the rich 1D traversal patterns and rely on Euclidean operations, CurveCloudNet parameterizes the point cloud as a collection of polylines (dubbed a "curve cloud"), establishing a local surface-aware ordering on the points. Our method applies curve-specific operations to process the curve cloud, including a symmetric 1D convolution, a ball grouping for merging points along curves, and an efficient 1D farthest point sampling algorithm on curves. By combining these curve operations with existing point-based operations, CurveCloudNet is an efficient, scalable, and accurate backbone with low GPU memory requirements. Evaluations on the ShapeNet, Kortx, Audi Driving, and nuScenes datasets demonstrate that CurveCloudNet outperforms both point-based and sparse-voxel backbones in various segmentation settings, notably scaling better to large scenes than point-based alternatives while exhibiting better single object performance than sparse-voxel alternatives.
CC3D: Layout-Conditioned Generation of Compositional 3D Scenes
Mar 21, 2023


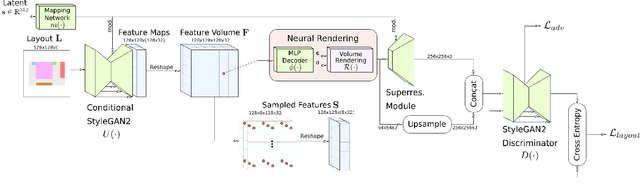
In this work, we introduce CC3D, a conditional generative model that synthesizes complex 3D scenes conditioned on 2D semantic scene layouts, trained using single-view images. Different from most existing 3D GANs that limit their applicability to aligned single objects, we focus on generating complex scenes with multiple objects, by modeling the compositional nature of 3D scenes. By devising a 2D layout-based approach for 3D synthesis and implementing a new 3D field representation with a stronger geometric inductive bias, we have created a 3D GAN that is both efficient and of high quality, while allowing for a more controllable generation process. Our evaluations on synthetic 3D-FRONT and real-world KITTI-360 datasets demonstrate that our model generates scenes of improved visual and geometric quality in comparison to previous works.
PartNeRF: Generating Part-Aware Editable 3D Shapes without 3D Supervision
Mar 21, 2023Impressive progress in generative models and implicit representations gave rise to methods that can generate 3D shapes of high quality. However, being able to locally control and edit shapes is another essential property that can unlock several content creation applications. Local control can be achieved with part-aware models, but existing methods require 3D supervision and cannot produce textures. In this work, we devise PartNeRF, a novel part-aware generative model for editable 3D shape synthesis that does not require any explicit 3D supervision. Our model generates objects as a set of locally defined NeRFs, augmented with an affine transformation. This enables several editing operations such as applying transformations on parts, mixing parts from different objects etc. To ensure distinct, manipulable parts we enforce a hard assignment of rays to parts that makes sure that the color of each ray is only determined by a single NeRF. As a result, altering one part does not affect the appearance of the others. Evaluations on various ShapeNet categories demonstrate the ability of our model to generate editable 3D objects of improved fidelity, compared to previous part-based generative approaches that require 3D supervision or models relying on NeRFs.
ALTO: Alternating Latent Topologies for Implicit 3D Reconstruction
Dec 08, 2022

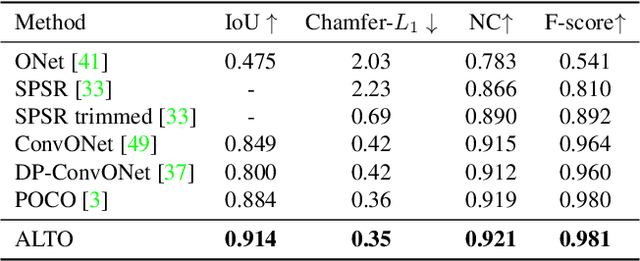
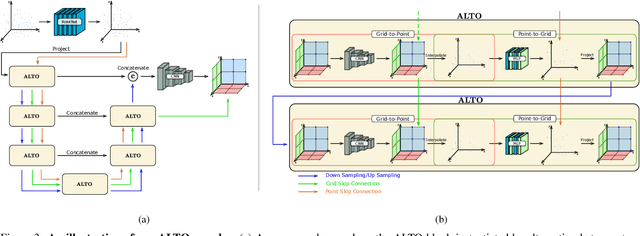
This work introduces alternating latent topologies (ALTO) for high-fidelity reconstruction of implicit 3D surfaces from noisy point clouds. Previous work identifies that the spatial arrangement of latent encodings is important to recover detail. One school of thought is to encode a latent vector for each point (point latents). Another school of thought is to project point latents into a grid (grid latents) which could be a voxel grid or triplane grid. Each school of thought has tradeoffs. Grid latents are coarse and lose high-frequency detail. In contrast, point latents preserve detail. However, point latents are more difficult to decode into a surface, and quality and runtime suffer. In this paper, we propose ALTO to sequentially alternate between geometric representations, before converging to an easy-to-decode latent. We find that this preserves spatial expressiveness and makes decoding lightweight. We validate ALTO on implicit 3D recovery and observe not only a performance improvement over the state-of-the-art, but a runtime improvement of 3-10$\times$. Project website at https://visual.ee.ucla.edu/alto.htm/.