 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAM 3D Body: Robust Full-Body Human Mesh Recovery
Feb 17, 2026We introduce SAM 3D Body (3DB), a promptable model for single-image full-body 3D human mesh recovery (HMR) that demonstrates state-of-the-art performance, with strong generalization and consistent accuracy in diverse in-the-wild conditions. 3DB estimates the human pose of the body, feet, and hands. It is the first model to use a new parametric mesh representation, Momentum Human Rig (MHR), which decouples skeletal structure and surface shape. 3DB employs an encoder-decoder architecture and supports auxiliary prompts, including 2D keypoints and masks, enabling user-guided inference similar to the SAM family of models. We derive high-quality annotations from a multi-stage annotation pipeline that uses various combinations of manual keypoint annotation, differentiable optimization, multi-view geometry, and dense keypoint detection. Our data engine efficiently selects and processes data to ensure data diversity, collecting unusual poses and rare imaging conditions. We present a new evaluation dataset organized by pose and appearance categories, enabling nuanced analysis of model behavior. Our experiments demonstrate superior generalization and substantial improvements over prior methods in both qualitative user preference studies and traditional quantitative analysis. Both 3DB and MHR are open-source.
Purposer: Putting Human Motion Generation in Context
Apr 19, 2024We present a novel method to generate human motion to populate 3D indoor scenes. It can be controlled with various combinations of conditioning signals such as a path in a scene, target poses, past motions, and scenes represented as 3D point clouds. State-of-the-art methods are either models specialized to one single setting, require vast amounts of high-quality and diverse training data, or are unconditional models that do not integrate scene or other contextual information. As a consequence, they have limited applicability and rely on costly training data. To address these limitations, we propose a new method ,dubbed Purposer, based on neural discrete representation learning. Our model is capable of exploiting, in a flexible manner, different types of information already present in open access large-scale datasets such as AMASS. First, we encode unconditional human motion into a discrete latent space. Second, an autoregressive generative model, conditioned with key contextual information, either with prompting or additive tokens, and trained for next-step prediction in this space, synthesizes sequences of latent indices. We further design a novel conditioning block to handle future conditioning information in such a causal model by using a network with two branches to compute separate stacks of features. In this manner, Purposer can generate realistic motion sequences in diverse test scenes. Through exhaustive evaluation, we demonstrate that our multi-contextual solution outperforms existing specialized approaches for specific contextual information, both in terms of quality and diversity. Our model is trained with short sequences, but a byproduct of being able to use various conditioning signals is that at test time different combinations can be used to chain short sequences together and generate long motions within a context scene.
MultiPhys: Multi-Person Physics-aware 3D Motion Estimation
Apr 18, 2024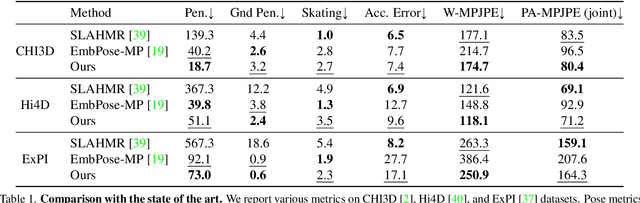

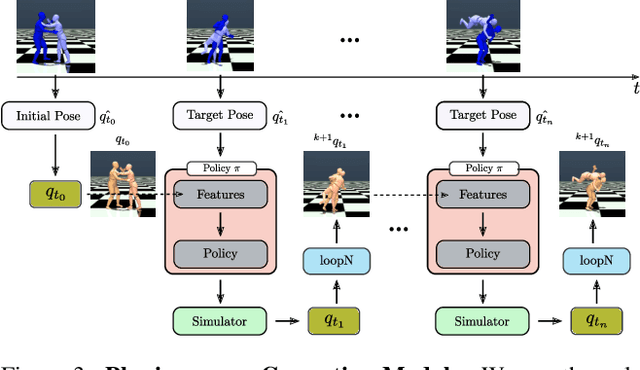
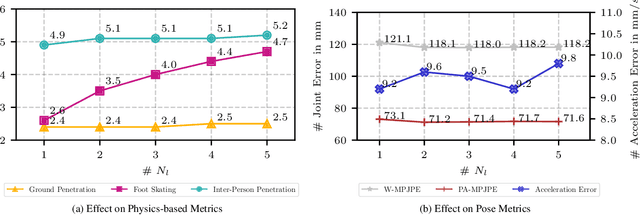
We introduce MultiPhys, a method designed for recovering multi-person motion from monocular videos. Our focus lies in capturing coherent spatial placement between pairs of individuals across varying degrees of engagement. MultiPhys, being physically aware, exhibits robustness to jittering and occlusions, and effectively eliminates penetration issues between the two individuals. We devise a pipeline in which the motion estimated by a kinematic-based method is fed into a physics simulator in an autoregressive manner. We introduce distinct components that enable our model to harness the simulator's properties without compromising the accuracy of the kinematic estimates. This results in final motion estimates that are both kinematically coherent and physically compliant. Extensive evaluations on three challenging datasets characterized by substantial inter-person interaction show that our method significantly reduces errors associated with penetration and foot skating, while performing competitively with the state-of-the-art on motion accuracy and smoothness. Results and code can be found on our project page (http://www.iri.upc.edu/people/nugrinovic/multiphys/).
Single-view 3D Body and Cloth Reconstruction under Complex Poses
May 09, 2022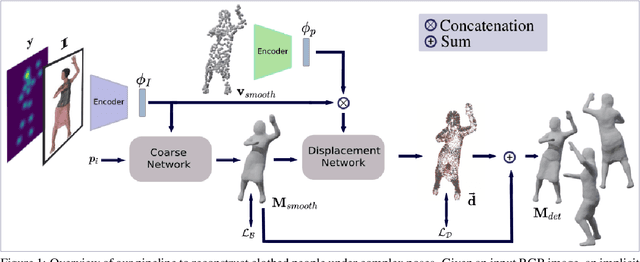
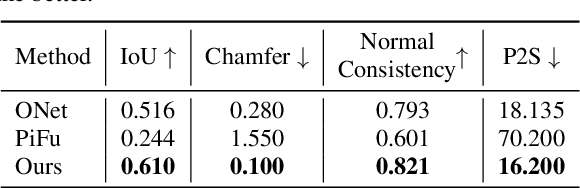
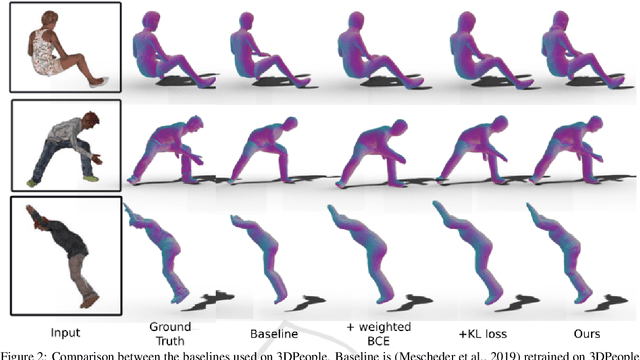

Recent advances in 3D human shape reconstruction from single images have shown impressive results, leveraging on deep networks that model the so-called implicit function to learn the occupancy status of arbitrarily dense 3D points in space. However, while current algorithms based on this paradigm, like PiFuHD, are able to estimate accurate geometry of the human shape and clothes, they require high-resolution input images and are not able to capture complex body poses. Most training and evaluation is performed on 1k-resolution images of humans standing in front of the camera under neutral body poses. In this paper, we leverage publicly available data to extend existing implicit function-based models to deal with images of humans that can have arbitrary poses and self-occluded limbs. We argue that the representation power of the implicit function is not sufficient to simultaneously model details of the geometry and of the body pose. We, therefore, propose a coarse-to-fine approach in which we first learn an implicit function that maps the input image to a 3D body shape with a low level of detail, but which correctly fits the underlying human pose, despite its complexity. We then learn a displacement map, conditioned on the smoothed surface and on the input image, which encodes the high-frequency details of the clothes and body. In the experimental section, we show that this coarse-to-fine strategy represents a very good trade-off between shape detail and pose correctness, comparing favorably to the most recent state-of-the-art approaches. Our code will be made publicly available.
Permutation-Invariant Relational Network for Multi-person 3D Pose Estimation
Apr 11, 2022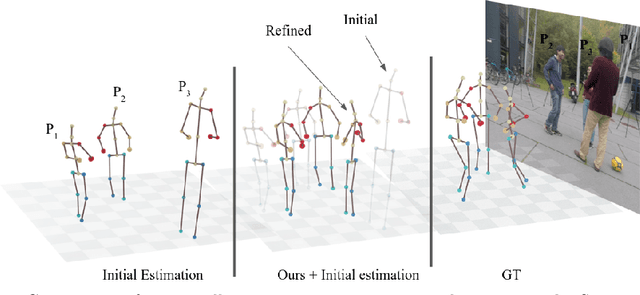
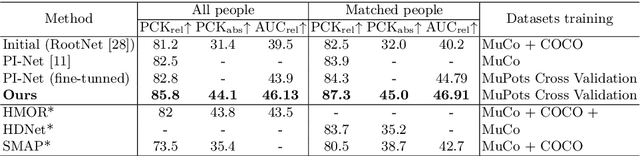
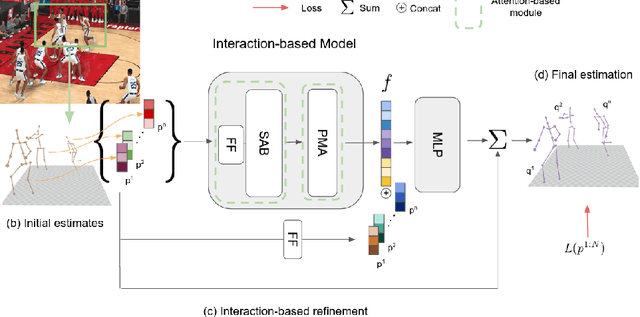
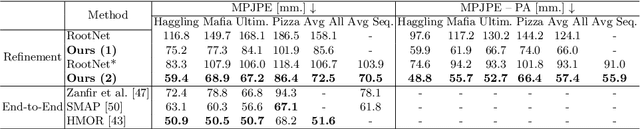
Recovering multi-person 3D poses from a single RGB image is a severely ill-conditioned problem due not only to the inherent 2D-3D depth ambiguity but also because of inter-person occlusions and body truncations. Recent works have shown promising results by simultaneously reasoning for different people but in all cases within a local neighborhood. An interesting exception is PI-Net, which introduces a self-attention block to reason for all people in the image at the same time and refine potentially noisy initial 3D poses. However, the proposed methodology requires defining one of the individuals as a reference, and the outcome of the algorithm is sensitive to this choice. In this paper, we model people interactions at a whole, independently of their number, and in a permutation-invariant manner building upon the Set Transformer. We leverage on this representation to refine the initial 3D poses estimated by off-the-shelf detectors. A thorough evaluation demonstrates that our approach is able to boost the performance of the initially estimated 3D poses by large margins, achieving state-of-the-art results on MuPoTS-3D, CMU Panoptic and NBA2K datasets. Additionally, the proposed module is computationally efficient and can be used as a drop-in complement for any 3D pose detector in multi-people scenes.
Body Size and Depth Disambiguation in Multi-Person Reconstruction from Single Images
Nov 02, 2021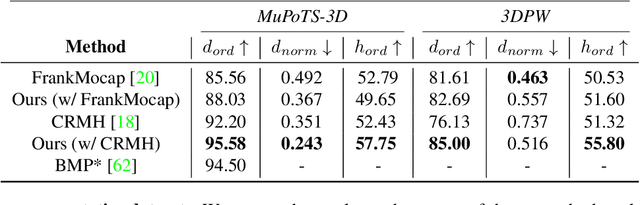
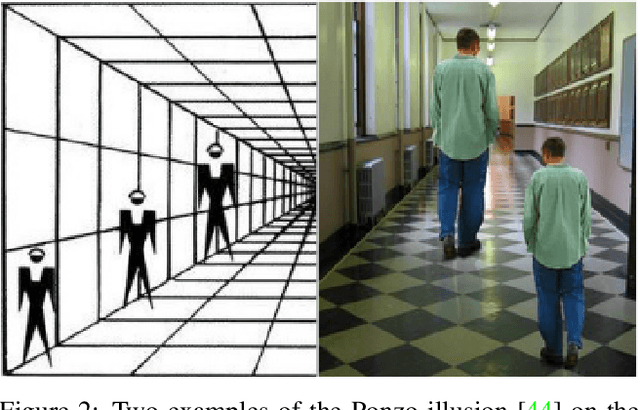
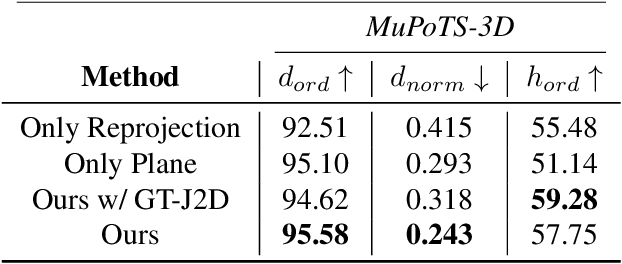
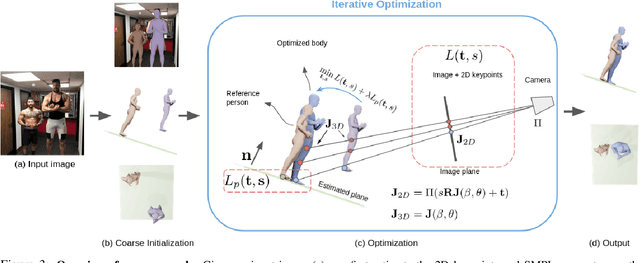
We address the problem of multi-person 3D body pose and shape estimation from a single image. While this problem can be addressed by applying single-person approaches multiple times for the same scene, recent works have shown the advantages of building upon deep architectures that simultaneously reason about all people in the scene in a holistic manner by enforcing, e.g., depth order constraints or minimizing interpenetration among reconstructed bodies. However, existing approaches are still unable to capture the size variability of people caused by the inherent body scale and depth ambiguity. In this work, we tackle this challenge by devising a novel optimization scheme that learns the appropriate body scale and relative camera pose, by enforcing the feet of all people to remain on the ground floor. A thorough evaluation on MuPoTS-3D and 3DPW datasets demonstrates that our approach is able to robustly estimate the body translation and shape of multiple people while retrieving their spatial arrangement, consistently improving current state-of-the-art, especially in scenes with people of very different heights