 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe human intention. A taxonomy attempt and its applications to robotics
Feb 17, 2026Despite a surge in robotics research dedicated to inferring and understanding human intent, a universally accepted definition remains elusive since existing works often equate human intention with specific task-related goals. This article seeks to address this gap by examining the multifaceted nature of intention. Drawing on insights from psychology, it attempts to consolidate a definition of intention into a comprehensible framework for a broader audience. The article classifies different types of intention based on psychological and communication studies, offering guidance to researchers shifting from pure technical enhancements to a more human-centric perspective in robotics. It then demonstrates how various robotics studies can be aligned with these intention categories. Finally, through in-depth analyses of collaborative search and object transport use cases, the article underscores the significance of considering the diverse facets of human intention.
AI or Human? Understanding Perceptions of Embodied Robots with LLMs
Jul 22, 2025The pursuit of artificial intelligence has long been associated to the the challenge of effectively measuring intelligence. Even if the Turing Test was introduced as a means of assessing a system intelligence, its relevance and application within the field of human-robot interaction remain largely underexplored. This study investigates the perception of intelligence in embodied robots by performing a Turing Test within a robotic platform. A total of 34 participants were tasked with distinguishing between AI- and human-operated robots while engaging in two interactive tasks: an information retrieval and a package handover. These tasks assessed the robot perception and navigation abilities under both static and dynamic conditions. Results indicate that participants were unable to reliably differentiate between AI- and human-controlled robots beyond chance levels. Furthermore, analysis of participant responses reveals key factors influencing the perception of artificial versus human intelligence in embodied robotic systems. These findings provide insights into the design of future interactive robots and contribute to the ongoing discourse on intelligence assessment in AI-driven systems.
Learning Priors of Human Motion With Vision Transformers
Jan 30, 2025



A clear understanding of where humans move in a scenario, their usual paths and speeds, and where they stop, is very important for different applications, such as mobility studies in urban areas or robot navigation tasks within human-populated environments. We propose in this article, a neural architecture based on Vision Transformers (ViTs) to provide this information. This solution can arguably capture spatial correlations more effectively than Convolutional Neural Networks (CNNs). In the paper, we describe the methodology and proposed neural architecture and show the experiments' results with a standard dataset. We show that the proposed ViT architecture improves the metrics compared to a method based on a CNN.
Human-Robot Collaborative Minimum Time Search through Sub-priors in Ant Colony Optimization
Oct 01, 2024Human-Robot Collaboration (HRC) has evolved into a highly promising issue owing to the latest breakthroughs in Artificial Intelligence (AI) and Human-Robot Interaction (HRI), among other reasons. This emerging growth increases the need to design multi-agent algorithms that can manage also human preferences. This paper presents an extension of the Ant Colony Optimization (ACO) meta-heuristic to solve the Minimum Time Search (MTS) task, in the case where humans and robots perform an object searching task together. The proposed model consists of two main blocks. The first one is a convolutional neural network (CNN) that provides the prior probabilities about where an object may be from a segmented image. The second one is the Sub-prior MTS-ACO algorithm (SP-MTS-ACO), which takes as inputs the prior probabilities and the particular search preferences of the agents in different sub-priors to generate search plans for all agents. The model has been tested in real experiments for the joint search of an object through a Vizanti web-based visualization in a tablet computer. The designed interface allows the communication between a human and our humanoid robot named IVO. The obtained results show an improvement in the search perception of the users without loss of efficiency.
A Survey on Socially Aware Robot Navigation: Taxonomy and Future Challenges
Nov 18, 2023Socially aware robot navigation is gaining popularity with the increase in delivery and assistive robots. The research is further fueled by a need for socially aware navigation skills in autonomous vehicles to move safely and appropriately in spaces shared with humans. Although most of these are ground robots, drones are also entering the field. In this paper, we present a literature survey of the works on socially aware robot navigation in the past 10 years. We propose four different faceted taxonomies to navigate the literature and examine the field from four different perspectives. Through the taxonomic review, we discuss the current research directions and the extending scope of applications in various domains. Further, we put forward a list of current research opportunities and present a discussion on possible future challenges that are likely to emerge in the field.
Human motion trajectory prediction using the Social Force Model for real-time and low computational cost applications
Nov 17, 2023Human motion trajectory prediction is a very important functionality for human-robot collaboration, specifically in accompanying, guiding, or approaching tasks, but also in social robotics, self-driving vehicles, or security systems. In this paper, a novel trajectory prediction model, Social Force Generative Adversarial Network (SoFGAN), is proposed. SoFGAN uses a Generative Adversarial Network (GAN) and Social Force Model (SFM) to generate different plausible people trajectories reducing collisions in a scene. Furthermore, a Conditional Variational Autoencoder (CVAE) module is added to emphasize the destination learning. We show that our method is more accurate in making predictions in UCY or BIWI datasets than most of the current state-of-the-art models and also reduces collisions in comparison to other approaches. Through real-life experiments, we demonstrate that the model can be used in real-time without GPU's to perform good quality predictions with a low computational cost.
A Hierarchical Framework for Collaborative Artificial Intelligence
Dec 14, 2022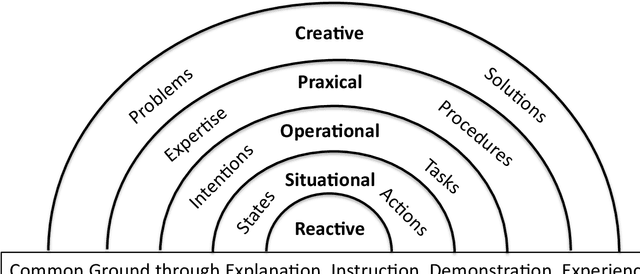
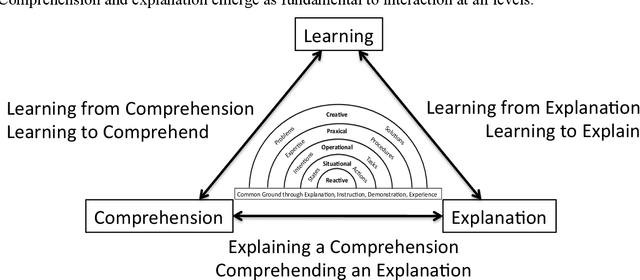
We propose a hierarchical framework for collaborative intelligent systems. This framework organizes research challenges based on the nature of the collaborative activity and the information that must be shared, with each level building on capabilities provided by lower levels. We review research paradigms at each level, with a description of classical engineering-based approaches and modern alternatives based on machine learning, illustrated with a running example using a hypothetical personal service robot. We discuss cross-cutting issues that occur at all levels, focusing on the problem of communicating and sharing comprehension, the role of explanation and the social nature of collaboration. We conclude with a summary of research challenges and a discussion of the potential for economic and societal impact provided by technologies that enhance human abilities and empower people and society through collaboration with Intelligent Systems.
Robot Navigation Anticipative Strategies in Deep Reinforcement Motion Planning
Oct 15, 2022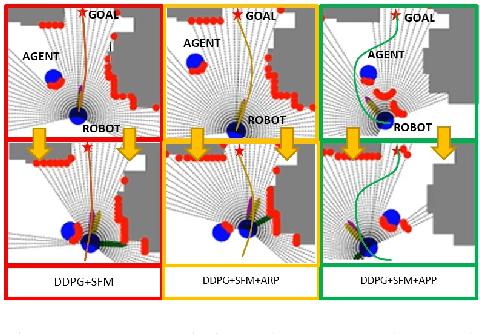
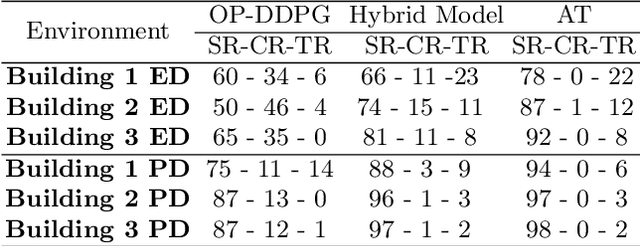
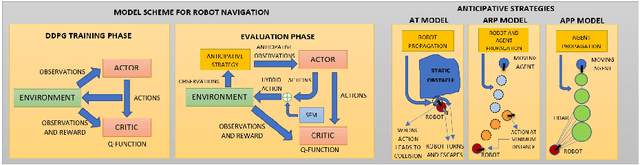
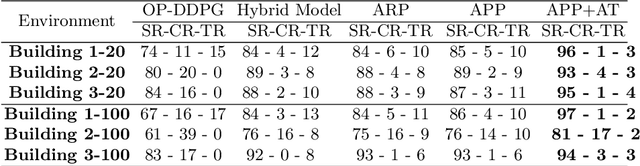
The navigation of robots in dynamic urban environments, requires elaborated anticipative strategies for the robot to avoid collisions with dynamic objects, like bicycles or pedestrians, and to be human aware. We have developed and analyzed three anticipative strategies in motion planning taking into account the future motion of the mobile objects that can move up to 18 km/h. First, we have used our hybrid policy resulting from a Deep Deterministic Policy Gradient (DDPG) training and the Social Force Model (SFM), and we have tested it in simulation in four complex map scenarios with many pedestrians. Second, we have used these anticipative strategies in real-life experiments using the hybrid motion planning method and the ROS Navigation Stack with Dynamic Windows Approach (NS-DWA). The results in simulations and real-life experiments show very good results in open environments and also in mixed scenarios with narrow spaces.
Weakly and Semi-Supervised Detection, Segmentation and Tracking of Table Grapes with Limited and Noisy Data
Aug 27, 2022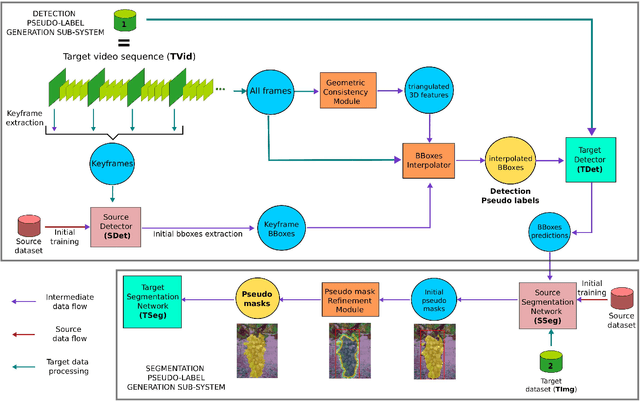
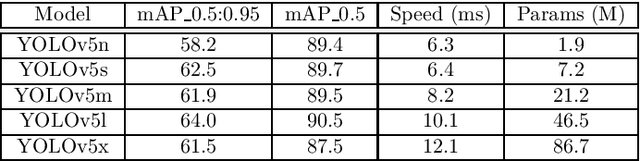

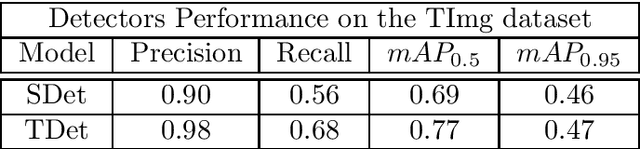
Detection, segmentation and tracking of fruits and vegetables are three fundamental tasks for precision agriculture, enabling robotic harvesting and yield estimation applications. However, modern algorithms are data hungry and it is not always possible to gather enough data to apply the best performing supervised approaches. Since data collection is an expensive and cumbersome task, the enabling technologies for using computer vision in agriculture are often out of reach for small businesses. Following previous work in this context, where we proposed an initial weakly supervised solution to reduce the data needed to get state-of-the-art detection and segmentation in precision agriculture applications, here we improve that system and explore the problem of tracking fruits in orchards. We present the case of vineyards of table grapes in southern Lazio (Italy) since grapes are a difficult fruit to segment due to occlusion, color and general illumination conditions. We consider the case when there is some initial labelled data that could work as source data (e.g. wine grape data), but it is considerably different from the target data (e.g. table grape data). To improve detection and segmentation on the target data, we propose to train the segmentation algorithm with a weak bounding box label, while for tracking we leverage 3D Structure from Motion algorithms to generate new labels from already labelled samples. Finally, the two systems are combined in a full semi-supervised approach. Comparisons with SotA supervised solutions show how our methods are able to train new models that achieve high performances with few labelled images and with very simple labelling.
Humans Social Relationship Classification during Accompaniment
Jul 06, 2022
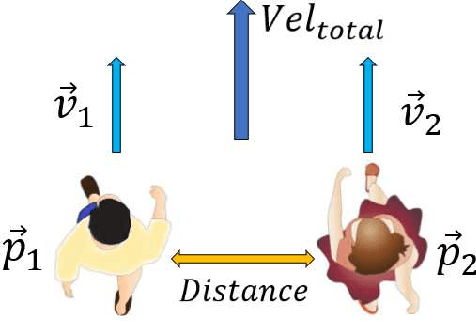


This paper presents the design of deep learning architectures which allow to classify the social relationship existing between two people who are walking in a side-by-side formation into four possible categories --colleagues, couple, family or friendship. The models are developed using Neural Networks or Recurrent Neural Networks to achieve the classification and are trained and evaluated using a database of readings obtained from humans performing an accompaniment process in an urban environment. The best achieved model accomplishes a relatively good accuracy in the classification problem and its results enhance partially the outcomes from a previous study [1]. Furthermore, the model proposed shows its future potential to improve its efficiency and to be implemented in a real robot.