 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-guided Motion Prediction with Semantics and Dynamic Occupancy Grid Maps
Jul 22, 2024


Accurate prediction of driving scenes is essential for road safety and autonomous driving. Occupancy Grid Maps (OGMs) are commonly employed for scene prediction due to their structured spatial representation, flexibility across sensor modalities and integration of uncertainty. Recent studies have successfully combined OGMs with deep learning methods to predict the evolution of scene and learn complex behaviours. These methods, however, do not consider prediction of flow or velocity vectors in the scene. In this work, we propose a novel multi-task framework that leverages dynamic OGMs and semantic information to predict both future vehicle semantic grids and the future flow of the scene. This incorporation of semantic flow not only offers intermediate scene features but also enables the generation of warped semantic grids. Evaluation on the real-world NuScenes dataset demonstrates improved prediction capabilities and enhanced ability of the model to retain dynamic vehicles within the scene.
A Survey on Socially Aware Robot Navigation: Taxonomy and Future Challenges
Nov 18, 2023Socially aware robot navigation is gaining popularity with the increase in delivery and assistive robots. The research is further fueled by a need for socially aware navigation skills in autonomous vehicles to move safely and appropriately in spaces shared with humans. Although most of these are ground robots, drones are also entering the field. In this paper, we present a literature survey of the works on socially aware robot navigation in the past 10 years. We propose four different faceted taxonomies to navigate the literature and examine the field from four different perspectives. Through the taxonomic review, we discuss the current research directions and the extending scope of applications in various domains. Further, we put forward a list of current research opportunities and present a discussion on possible future challenges that are likely to emerge in the field.
Vehicle Motion Forecasting using Prior Information and Semantic-assisted Occupancy Grid Maps
Aug 08, 2023



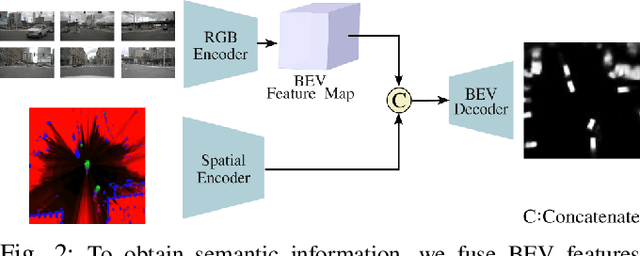
Motion prediction is a challenging task for autonomous vehicles due to uncertainty in the sensor data, the non-deterministic nature of future, and complex behavior of agents. In this paper, we tackle this problem by representing the scene as dynamic occupancy grid maps (DOGMs), associating semantic labels to the occupied cells and incorporating map information. We propose a novel framework that combines deep-learning-based spatio-temporal and probabilistic approaches to predict vehicle behaviors.Contrary to the conventional OGM prediction methods, evaluation of our work is conducted against the ground truth annotations. We experiment and validate our results on real-world NuScenes dataset and show that our model shows superior ability to predict both static and dynamic vehicles compared to OGM predictions. Furthermore, we perform an ablation study and assess the role of semantic labels and map in the architecture.
Allo-centric Occupancy Grid Prediction for Urban Traffic Scene Using Video Prediction Networks
Jan 11, 2023
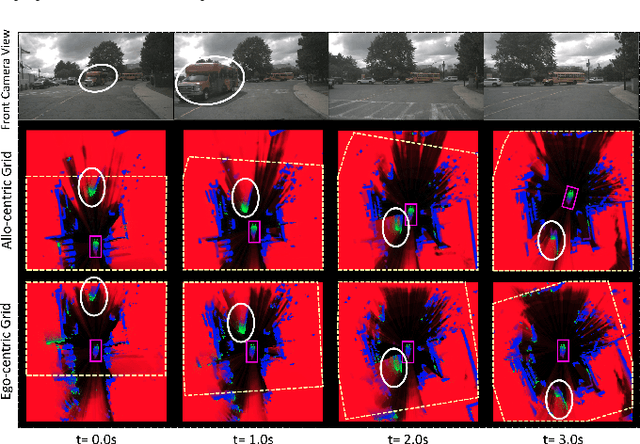


Prediction of dynamic environment is crucial to safe navigation of an autonomous vehicle. Urban traffic scenes are particularly challenging to forecast due to complex interactions between various dynamic agents, such as vehicles and vulnerable road users. Previous approaches have used egocentric occupancy grid maps to represent and predict dynamic environments. However, these predictions suffer from blurriness, loss of scene structure at turns, and vanishing of agents over longer prediction horizon. In this work, we propose a novel framework to make long-term predictions by representing the traffic scene in a fixed frame, referred as allo-centric occupancy grid. This allows for the static scene to remain fixed and to represent motion of the ego-vehicle on the grid like other agents'. We study the allo-centric grid prediction with different video prediction networks and validate the approach on the real-world Nuscenes dataset. The results demonstrate that the allo-centric grid representation significantly improves scene prediction, in comparison to the conventional ego-centric grid approach.
Navigation In Urban Environments Amongst Pedestrians Using Multi-Objective Deep Reinforcement Learning
Oct 11, 2021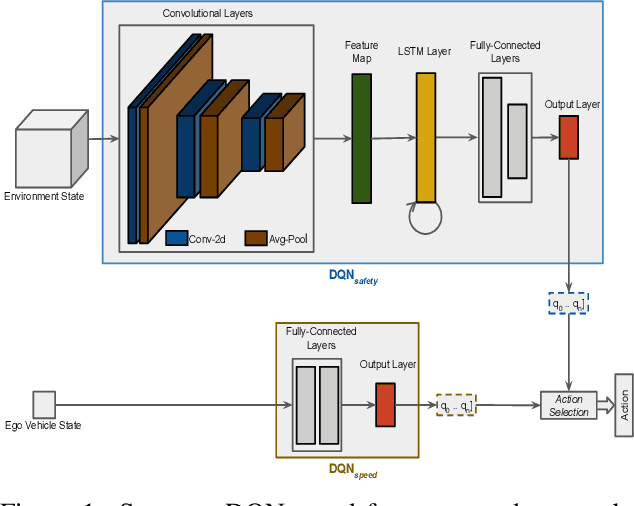
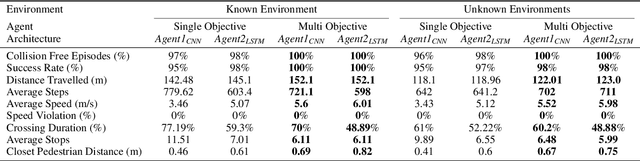
Urban autonomous driving in the presence of pedestrians as vulnerable road users is still a challenging and less examined research problem. This work formulates navigation in urban environments as a multi objective reinforcement learning problem. A deep learning variant of thresholded lexicographic Q-learning is presented for autonomous navigation amongst pedestrians. The multi objective DQN agent is trained on a custom urban environment developed in CARLA simulator. The proposed method is evaluated by comparing it with a single objective DQN variant on known and unknown environments. Evaluation results show that the proposed method outperforms the single objective DQN variant with respect to all aspects.
Behavioral decision-making for urban autonomous driving in the presence of pedestrians using Deep Recurrent Q-Network
Oct 26, 2020


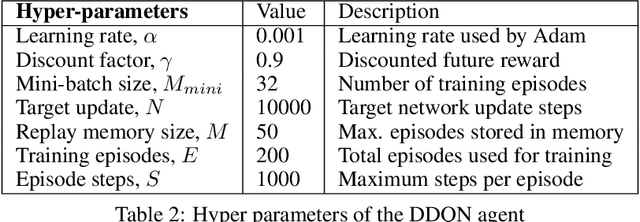
Decision making for autonomous driving in urban environments is challenging due to the complexity of the road structure and the uncertainty in the behavior of diverse road users. Traditional methods consist of manually designed rules as the driving policy, which require expert domain knowledge, are difficult to generalize and might give sub-optimal results as the environment gets complex. Whereas, using reinforcement learning, optimal driving policy could be learned and improved automatically through several interactions with the environment. However, current research in the field of reinforcement learning for autonomous driving is mainly focused on highway setup with little to no emphasis on urban environments. In this work, a deep reinforcement learning based decision-making approach for high-level driving behavior is proposed for urban environments in the presence of pedestrians. For this, the use of Deep Recurrent Q-Network (DRQN) is explored, a method combining state-of-the art Deep Q-Network (DQN) with a long term short term memory (LSTM) layer helping the agent gain a memory of the environment. A 3-D state representation is designed as the input combined with a well defined reward function to train the agent for learning an appropriate behavior policy in a real-world like urban simulator. The proposed method is evaluated for dense urban scenarios and compared with a rule-based approach and results show that the proposed DRQN based driving behavior decision maker outperforms the rule-based approach.
Building Prior Knowledge: A Markov Based Pedestrian Prediction Model Using Urban Environmental Data
Sep 17, 2018
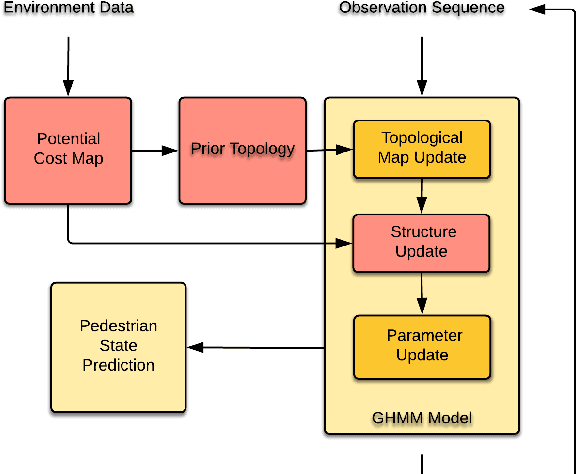

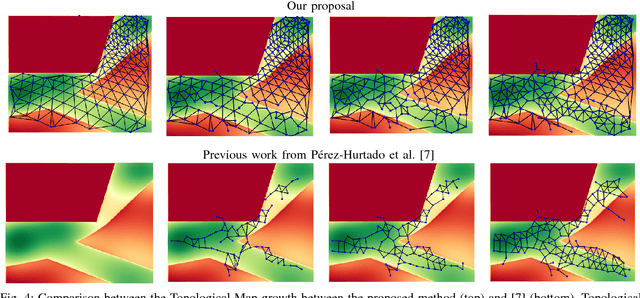
Autonomous Vehicles navigating in urban areas have a need to understand and predict future pedestrian behavior for safer navigation. This high level of situational awareness requires observing pedestrian behavior and extrapolating their positions to know future positions. While some work has been done in this field using Hidden Markov Models (HMMs), one of the few observed drawbacks of the method is the need for informed priors for learning behavior. In this work, an extension to the Growing Hidden Markov Model (GHMM) method is proposed to solve some of these drawbacks. This is achieved by building on existing work using potential cost maps and the principle of Natural Vision. As a consequence, the proposed model is able to predict pedestrian positions more precisely over a longer horizon compared to the state of the art. The method is tested over "legal" and "illegal" behavior of pedestrians, having trained the model with sparse observations and partial trajectories. The method, with no training data, is compared against a trained state of the art model. It is observed that the proposed method is robust even in new, previously unseen areas.
Personal space of autonomous car's passengers sitting in the driver's seat
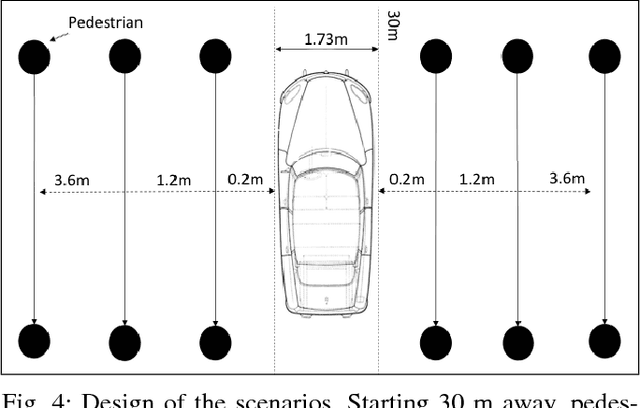
May 09, 2018


This article deals with the specific context of an autonomous car navigating in an urban center within a shared space between pedestrians and cars. The driver delegates the control to the autonomous system while remaining seated in the driver's seat. The proposed study aims at giving a first insight into the definition of human perception of space applied to vehicles by testing the existence of a personal space around the car.It aims at measuring proxemic information about the driver's comfort zone in such conditions.Proxemics, or human perception of space, has been largely explored when applied to humans or to robots, leading to the concept of personal space, but poorly when applied to vehicles. In this article, we highlight the existence and the characteristics of a zone of comfort around the car which is not correlated to the risk of a collision between the car and other road users. Our experiment includes 19 volunteers using a virtual reality headset to look at 30 scenarios filmed in 360{\textdegree} from the point of view of a passenger sitting in the driver's seat of an autonomous car.They were asked to say "stop" when they felt discomfort visualizing the scenarios.As said, the scenarios voluntarily avoid collision effect as we do not want to measure fear but discomfort.The scenarios involve one or three pedestrians walking past the car at different distances from the wings of the car, relative to the direction of motion of the car, on both sides. The car is either static or moving straight forward at different speeds.The results indicate the existence of a comfort zone around the car in which intrusion causes discomfort.The size of the comfort zone is sensitive neither to the side of the car where the pedestrian passes nor to the number of pedestrians. In contrast, the feeling of discomfort is relative to the car's motion (static or moving).Another outcome from this study is an illustration of the usage of first person 360{\textdegree} video and a virtual reality headset to evaluate feelings of a passenger within an autonomous car.