 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlow-guided Motion Prediction with Semantics and Dynamic Occupancy Grid Maps
Jul 22, 2024
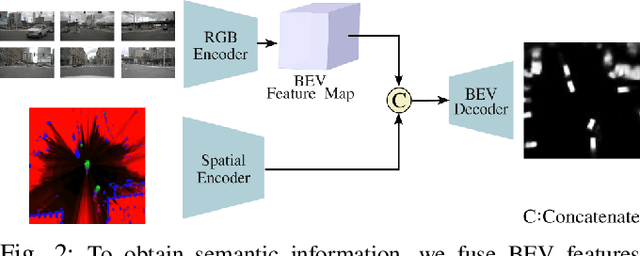


Accurate prediction of driving scenes is essential for road safety and autonomous driving. Occupancy Grid Maps (OGMs) are commonly employed for scene prediction due to their structured spatial representation, flexibility across sensor modalities and integration of uncertainty. Recent studies have successfully combined OGMs with deep learning methods to predict the evolution of scene and learn complex behaviours. These methods, however, do not consider prediction of flow or velocity vectors in the scene. In this work, we propose a novel multi-task framework that leverages dynamic OGMs and semantic information to predict both future vehicle semantic grids and the future flow of the scene. This incorporation of semantic flow not only offers intermediate scene features but also enables the generation of warped semantic grids. Evaluation on the real-world NuScenes dataset demonstrates improved prediction capabilities and enhanced ability of the model to retain dynamic vehicles within the scene.
Vehicle Motion Forecasting using Prior Information and Semantic-assisted Occupancy Grid Maps
Aug 08, 2023



Motion prediction is a challenging task for autonomous vehicles due to uncertainty in the sensor data, the non-deterministic nature of future, and complex behavior of agents. In this paper, we tackle this problem by representing the scene as dynamic occupancy grid maps (DOGMs), associating semantic labels to the occupied cells and incorporating map information. We propose a novel framework that combines deep-learning-based spatio-temporal and probabilistic approaches to predict vehicle behaviors.Contrary to the conventional OGM prediction methods, evaluation of our work is conducted against the ground truth annotations. We experiment and validate our results on real-world NuScenes dataset and show that our model shows superior ability to predict both static and dynamic vehicles compared to OGM predictions. Furthermore, we perform an ablation study and assess the role of semantic labels and map in the architecture.
Allo-centric Occupancy Grid Prediction for Urban Traffic Scene Using Video Prediction Networks
Jan 11, 2023
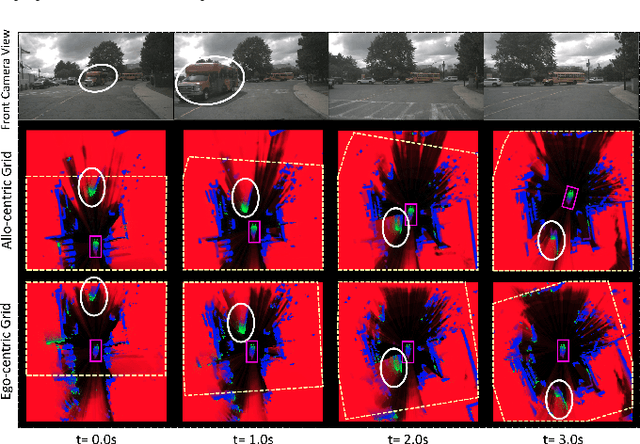


Prediction of dynamic environment is crucial to safe navigation of an autonomous vehicle. Urban traffic scenes are particularly challenging to forecast due to complex interactions between various dynamic agents, such as vehicles and vulnerable road users. Previous approaches have used egocentric occupancy grid maps to represent and predict dynamic environments. However, these predictions suffer from blurriness, loss of scene structure at turns, and vanishing of agents over longer prediction horizon. In this work, we propose a novel framework to make long-term predictions by representing the traffic scene in a fixed frame, referred as allo-centric occupancy grid. This allows for the static scene to remain fixed and to represent motion of the ego-vehicle on the grid like other agents'. We study the allo-centric grid prediction with different video prediction networks and validate the approach on the real-world Nuscenes dataset. The results demonstrate that the allo-centric grid representation significantly improves scene prediction, in comparison to the conventional ego-centric grid approach.