 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVal: A Cross-dataset Evaluation Study of BEV Segmentation Models for Autononomous Driving
Aug 29, 2024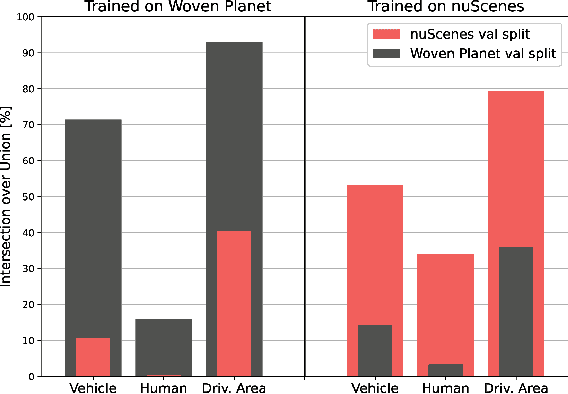
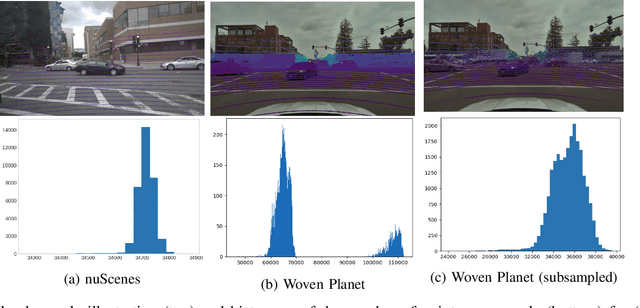
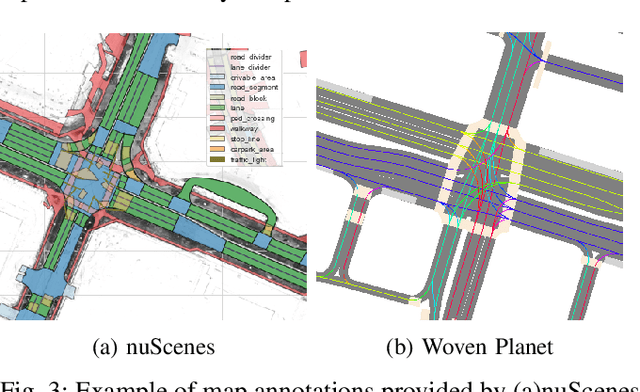
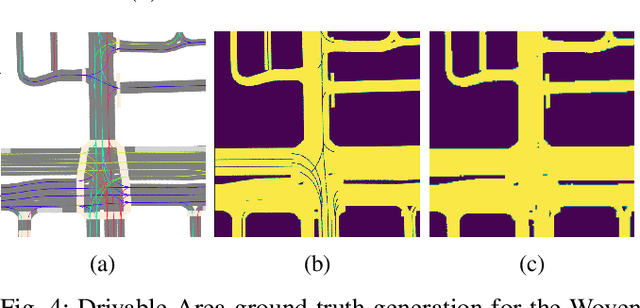
Current research in semantic bird's-eye view segmentation for autonomous driving focuses solely on optimizing neural network models using a single dataset, typically nuScenes. This practice leads to the development of highly specialized models that may fail when faced with different environments or sensor setups, a problem known as domain shift. In this paper, we conduct a comprehensive cross-dataset evaluation of state-of-the-art BEV segmentation models to assess their performance across different training and testing datasets and setups, as well as different semantic categories. We investigate the influence of different sensors, such as cameras and LiDAR, on the models' ability to generalize to diverse conditions and scenarios. Additionally, we conduct multi-dataset training experiments that improve models' BEV segmentation performance compared to single-dataset training. Our work addresses the gap in evaluating BEV segmentation models under cross-dataset validation. And our findings underscore the importance of enhancing model generalizability and adaptability to ensure more robust and reliable BEV segmentation approaches for autonomous driving applications.
Flow-guided Motion Prediction with Semantics and Dynamic Occupancy Grid Maps
Jul 22, 2024
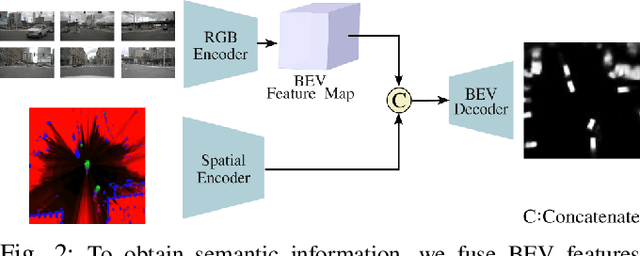


Accurate prediction of driving scenes is essential for road safety and autonomous driving. Occupancy Grid Maps (OGMs) are commonly employed for scene prediction due to their structured spatial representation, flexibility across sensor modalities and integration of uncertainty. Recent studies have successfully combined OGMs with deep learning methods to predict the evolution of scene and learn complex behaviours. These methods, however, do not consider prediction of flow or velocity vectors in the scene. In this work, we propose a novel multi-task framework that leverages dynamic OGMs and semantic information to predict both future vehicle semantic grids and the future flow of the scene. This incorporation of semantic flow not only offers intermediate scene features but also enables the generation of warped semantic grids. Evaluation on the real-world NuScenes dataset demonstrates improved prediction capabilities and enhanced ability of the model to retain dynamic vehicles within the scene.
TLCFuse: Temporal Multi-Modality Fusion Towards Occlusion-Aware Semantic Segmentation-Aided Motion Planning
Nov 09, 2023



In autonomous driving, addressing occlusion scenarios is crucial yet challenging. Robust surrounding perception is essential for handling occlusions and aiding motion planning. State-of-the-art models fuse Lidar and Camera data to produce impressive perception results, but detecting occluded objects remains challenging. In this paper, we emphasize the crucial role of temporal cues by integrating them alongside these modalities to address this challenge. We propose a novel approach for bird's eye view semantic grid segmentation, that leverages sequential sensor data to achieve robustness against occlusions. Our model extracts information from the sensor readings using attention operations and aggregates this information into a lower-dimensional latent representation, enabling thus the processing of multi-step inputs at each prediction step. Moreover, we show how it can also be directly applied to forecast the development of traffic scenes and be seamlessly integrated into a motion planner for trajectory planning. On the semantic segmentation tasks, we evaluate our model on the nuScenes dataset and show that it outperforms other baselines, with particularly large differences when evaluating on occluded and partially-occluded vehicles. Additionally, on motion planning task we are among the early teams to train and evaluate on nuPlan, a cutting-edge large-scale dataset for motion planning.
Unsupervised Approaches for Out-Of-Distribution Dermoscopic Lesion Detection
Nov 08, 2021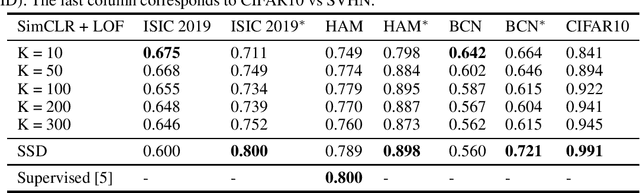

There are limited works showing the efficacy of unsupervised Out-of-Distribution (OOD) methods on complex medical data. Here, we present preliminary findings of our unsupervised OOD detection algorithm, SimCLR-LOF, as well as a recent state of the art approach (SSD), applied on medical images. SimCLR-LOF learns semantically meaningful features using SimCLR and uses LOF for scoring if a test sample is OOD. We evaluated on the multi-source International Skin Imaging Collaboration (ISIC) 2019 dataset, and show results that are competitive with SSD as well as with recent supervised approaches applied on the same data.
Towards Visually Explaining Variational Autoencoders
Nov 18, 2019

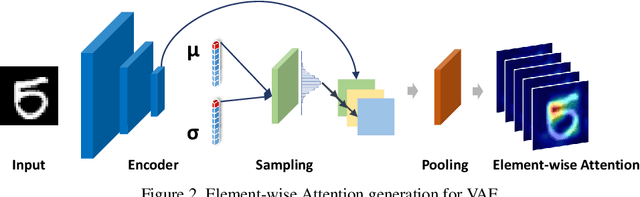

Recent advances in Convolutional Neural Network (CNN) model interpretability have led to impressive progress in visualizing and understanding model predictions. In particular, gradient-based visual attention methods have driven much recent effort in using visual attention maps as a means for visual explanations. A key problem, however, is these methods are designed for classification and categorization tasks, and their extension to explaining generative models, \eg, variational autoencoders (VAE) is not trivial. In this work, we take a step towards bridging this crucial gap, proposing the first technique to visually explain VAEs by means of gradient-based attention. We present methods to generate visual attention from the learned latent space, and also demonstrate such attention explanations serve more than just explaining VAE predictions. We show how these attention maps can be used to localize anomalies in images, demonstrating state-of-the-art performance on the MVTec-AD dataset. We also show how they can be infused into model training, helping bootstrap the VAE into learning improved latent space disentanglement, demonstrated on the Dsprites dataset.
DYAN: A Dynamical Atoms-Based Network for Video Prediction
Sep 14, 2018

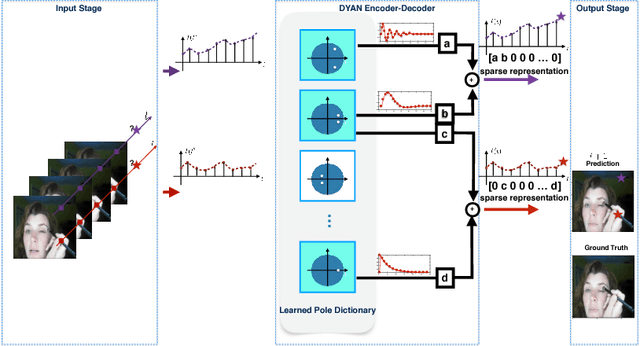

The ability to anticipate the future is essential when making real time critical decisions, provides valuable information to understand dynamic natural scenes, and can help unsupervised video representation learning. State-of-art video prediction is based on LSTM recursive networks and/or generative adversarial network learning. These are complex architectures that need to learn large numbers of parameters, are potentially hard to train, slow to run, and may produce blurry predictions. In this paper, we introduce DYAN, a novel network with very few parameters and easy to train, which produces accurate, high quality frame predictions, significantly faster than previous approaches. DYAN owes its good qualities to its encoder and decoder, which are designed following concepts from systems identification theory and exploit the dynamics-based invariants of the data. Extensive experiments using several standard video datasets show that DYAN is superior generating frames and that it generalizes well across domains.
Multi-camera Multi-Object Tracking
Sep 20, 2017



In this paper, we propose a pipeline for multi-target visual tracking under multi-camera system. For multi-camera system tracking problem, efficient data association across cameras, and at the same time, across frames becomes more important than single-camera system tracking. However, most of the multi-camera tracking algorithms emphasis on single camera across frame data association. Thus in our work, we model our tracking problem as a global graph, and adopt Generalized Maximum Multi Clique optimization problem as our core algorithm to take both across frame and across camera data correlation into account all together. Furthermore, in order to compute good similarity scores as the input of our graph model, we extract both appearance and dynamic motion similarities. For appearance feature, Local Maximal Occurrence Representation(LOMO) feature extraction algorithm for ReID is conducted. When it comes to capturing the dynamic information, we build Hankel matrix for each tracklet of target and apply rank estimation with Iterative Hankel Total Least Squares(IHTLS) algorithm to it. We evaluate our tracker on the challenging Terrace Sequences from EPFL CVLAB as well as recently published Duke MTMC dataset.