 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSplain: Sparse and Smooth Explainer for Retinopathy of Prematurity Classification
Dec 08, 2025Neural networks are frequently used in medical diagnosis. However, due to their black-box nature, model explainers are used to help clinicians understand better and trust model outputs. This paper introduces an explainer method for classifying Retinopathy of Prematurity (ROP) from fundus images. Previous methods fail to generate explanations that preserve input image structures such as smoothness and sparsity. We introduce Sparse and Smooth Explainer (SSplain), a method that generates pixel-wise explanations while preserving image structures by enforcing smoothness and sparsity. This results in realistic explanations to enhance the understanding of the given black-box model. To achieve this goal, we define an optimization problem with combinatorial constraints and solve it using the Alternating Direction Method of Multipliers (ADMM). Experimental results show that SSplain outperforms commonly used explainers in terms of both post-hoc accuracy and smoothness analyses. Additionally, SSplain identifies features that are consistent with domain-understandable features that clinicians consider as discriminative factors for ROP. We also show SSplain's generalization by applying it to additional publicly available datasets. Code is available at https://github.com/neu-spiral/SSplain.
On the Role of Calibration in Benchmarking Algorithmic Fairness for Skin Cancer Detection
Nov 10, 2025Artificial Intelligence (AI) models have demonstrated expert-level performance in melanoma detection, yet their clinical adoption is hindered by performance disparities across demographic subgroups such as gender, race, and age. Previous efforts to benchmark the performance of AI models have primarily focused on assessing model performance using group fairness metrics that rely on the Area Under the Receiver Operating Characteristic curve (AUROC), which does not provide insights into a model's ability to provide accurate estimates. In line with clinical assessments, this paper addresses this gap by incorporating calibration as a complementary benchmarking metric to AUROC-based fairness metrics. Calibration evaluates the alignment between predicted probabilities and observed event rates, offering deeper insights into subgroup biases. We assess the performance of the leading skin cancer detection algorithm of the ISIC 2020 Challenge on the ISIC 2020 Challenge dataset and the PROVE-AI dataset, and compare it with the second and third place models, focusing on subgroups defined by sex, race (Fitzpatrick Skin Tone), and age. Our findings reveal that while existing models enhance discriminative accuracy, they often over-diagnose risk and exhibit calibration issues when applied to new datasets. This study underscores the necessity for comprehensive model auditing strategies and extensive metadata collection to achieve equitable AI-driven healthcare solutions. All code is publicly available at https://github.com/bdominique/testing_strong_calibration.
* 19 pages, 4 figures. Accepted for publication at the Journal of Machine Learning for Biomedical Imaging (MELBA) https://melba-journal.org/2025:027
H-SPLID: HSIC-based Saliency Preserving Latent Information Decomposition
Oct 23, 2025We introduce H-SPLID, a novel algorithm for learning salient feature representations through the explicit decomposition of salient and non-salient features into separate spaces. We show that H-SPLID promotes learning low-dimensional, task-relevant features. We prove that the expected prediction deviation under input perturbations is upper-bounded by the dimension of the salient subspace and the Hilbert-Schmidt Independence Criterion (HSIC) between inputs and representations. This establishes a link between robustness and latent representation compression in terms of the dimensionality and information preserved. Empirical evaluations on image classification tasks show that models trained with H-SPLID primarily rely on salient input components, as indicated by reduced sensitivity to perturbations affecting non-salient features, such as image backgrounds. Our code is available at https://github.com/neu-spiral/H-SPLID.
Linear-Time Demonstration Selection for In-Context Learning via Gradient Estimation
Aug 27, 2025

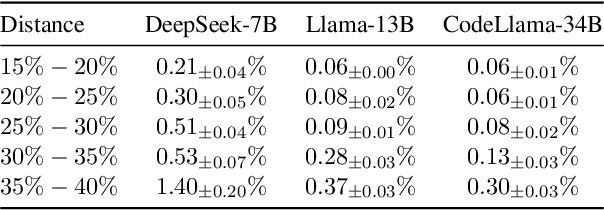

This paper introduces an algorithm to select demonstration examples for in-context learning of a query set. Given a set of $n$ examples, how can we quickly select $k$ out of $n$ to best serve as the conditioning for downstream inference? This problem has broad applications in prompt tuning and chain-of-thought reasoning. Since model weights remain fixed during in-context learning, previous work has sought to design methods based on the similarity of token embeddings. This work proposes a new approach based on gradients of the output taken in the input embedding space. Our approach estimates model outputs through a first-order approximation using the gradients. Then, we apply this estimation to multiple randomly sampled subsets. Finally, we aggregate the sampled subset outcomes to form an influence score for each demonstration, and select $k$ most relevant examples. This procedure only requires pre-computing model outputs and gradients once, resulting in a linear-time algorithm relative to model and training set sizes. Extensive experiments across various models and datasets validate the efficiency of our approach. We show that the gradient estimation procedure yields approximations of full inference with less than $\mathbf{1}\%$ error across six datasets. This allows us to scale up subset selection that would otherwise run full inference by up to $\mathbf{37.7}\times$ on models with up to $34$ billion parameters, and outperform existing selection methods based on input embeddings by $\mathbf{11}\%$ on average.
OrdShap: Feature Position Importance for Sequential Black-Box Models
Jul 16, 2025Sequential deep learning models excel in domains with temporal or sequential dependencies, but their complexity necessitates post-hoc feature attribution methods for understanding their predictions. While existing techniques quantify feature importance, they inherently assume fixed feature ordering - conflating the effects of (1) feature values and (2) their positions within input sequences. To address this gap, we introduce OrdShap, a novel attribution method that disentangles these effects by quantifying how a model's predictions change in response to permuting feature position. We establish a game-theoretic connection between OrdShap and Sanchez-Berganti\~nos values, providing a theoretically grounded approach to position-sensitive attribution. Empirical results from health, natural language, and synthetic datasets highlight OrdShap's effectiveness in capturing feature value and feature position attributions, and provide deeper insight into model behavior.
Dependency-aware Maximum Likelihood Estimation for Active Learning
Mar 07, 2025Active learning aims to efficiently build a labeled training set by strategically selecting samples to query labels from annotators. In this sequential process, each sample acquisition influences subsequent selections, causing dependencies among samples in the labeled set. However, these dependencies are overlooked during the model parameter estimation stage when updating the model using Maximum Likelihood Estimation (MLE), a conventional method that assumes independent and identically distributed (i.i.d.) data. We propose Dependency-aware MLE (DMLE), which corrects MLE within the active learning framework by addressing sample dependencies typically neglected due to the i.i.d. assumption, ensuring consistency with active learning principles in the model parameter estimation process. This improved method achieves superior performance across multiple benchmark datasets, reaching higher performance in earlier cycles compared to conventional MLE. Specifically, we observe average accuracy improvements of 6\%, 8.6\%, and 10.5\% for $k=1$, $k=5$, and $k=10$ respectively, after collecting the first 100 samples, where entropy is the acquisition function and $k$ is the query batch size acquired at every active learning cycle.
STAR: Stability-Inducing Weight Perturbation for Continual Learning
Mar 03, 2025



Humans can naturally learn new and varying tasks in a sequential manner. Continual learning is a class of learning algorithms that updates its learned model as it sees new data (on potentially new tasks) in a sequence. A key challenge in continual learning is that as the model is updated to learn new tasks, it becomes susceptible to catastrophic forgetting, where knowledge of previously learned tasks is lost. A popular approach to mitigate forgetting during continual learning is to maintain a small buffer of previously-seen samples and to replay them during training. However, this approach is limited by the small buffer size, and while forgetting is reduced, it is still present. In this paper, we propose a novel loss function, STAR, that exploits the worst-case parameter perturbation that reduces the KL-divergence of model predictions with that of its local parameter neighborhood to promote stability and alleviate forgetting. STAR can be combined with almost any existing rehearsal-based method as a plug-and-play component. We empirically show that STAR consistently improves the performance of existing methods by up to 15% across varying baselines and achieves superior or competitive accuracy to that of state-of-the-art methods aimed at improving rehearsal-based continual learning.
Axiomatic Explainer Globalness via Optimal Transport
Nov 02, 2024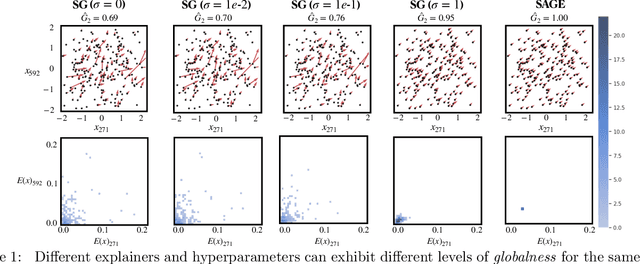


Explainability methods are often challenging to evaluate and compare. With a multitude of explainers available, practitioners must often compare and select explainers based on quantitative evaluation metrics. One particular differentiator between explainers is the diversity of explanations for a given dataset; i.e. whether all explanations are identical, unique and uniformly distributed, or somewhere between these two extremes. In this work, we define a complexity measure for explainers, globalness, which enables deeper understanding of the distribution of explanations produced by feature attribution and feature selection methods for a given dataset. We establish the axiomatic properties that any such measure should possess and prove that our proposed measure, Wasserstein Globalness, meets these criteria. We validate the utility of Wasserstein Globalness using image, tabular, and synthetic datasets, empirically showing that it both facilitates meaningful comparison between explainers and improves the selection process for explainability methods.
ADAPT to Robustify Prompt Tuning Vision Transformers
Mar 19, 2024



The performance of deep models, including Vision Transformers, is known to be vulnerable to adversarial attacks. Many existing defenses against these attacks, such as adversarial training, rely on full-model fine-tuning to induce robustness in the models. These defenses require storing a copy of the entire model, that can have billions of parameters, for each task. At the same time, parameter-efficient prompt tuning is used to adapt large transformer-based models to downstream tasks without the need to save large copies. In this paper, we examine parameter-efficient prompt tuning of Vision Transformers for downstream tasks under the lens of robustness. We show that previous adversarial defense methods, when applied to the prompt tuning paradigm, suffer from gradient obfuscation and are vulnerable to adaptive attacks. We introduce ADAPT, a novel framework for performing adaptive adversarial training in the prompt tuning paradigm. Our method achieves competitive robust accuracy of ~40% w.r.t. SOTA robustness methods using full-model fine-tuning, by tuning only ~1% of the number of parameters.
SmoothHess: ReLU Network Feature Interactions via Stein's Lemma
Nov 01, 2023


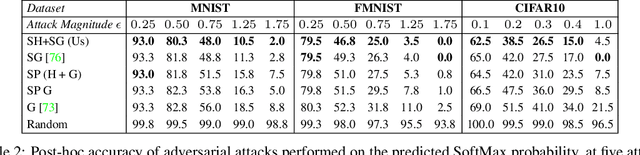
Several recent methods for interpretability model feature interactions by looking at the Hessian of a neural network. This poses a challenge for ReLU networks, which are piecewise-linear and thus have a zero Hessian almost everywhere. We propose SmoothHess, a method of estimating second-order interactions through Stein's Lemma. In particular, we estimate the Hessian of the network convolved with a Gaussian through an efficient sampling algorithm, requiring only network gradient calls. SmoothHess is applied post-hoc, requires no modifications to the ReLU network architecture, and the extent of smoothing can be controlled explicitly. We provide a non-asymptotic bound on the sample complexity of our estimation procedure. We validate the superior ability of SmoothHess to capture interactions on benchmark datasets and a real-world medical spirometry dataset.