 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Stability-Inducing Weight Perturbation for Continual Learning
Mar 03, 2025



Humans can naturally learn new and varying tasks in a sequential manner. Continual learning is a class of learning algorithms that updates its learned model as it sees new data (on potentially new tasks) in a sequence. A key challenge in continual learning is that as the model is updated to learn new tasks, it becomes susceptible to catastrophic forgetting, where knowledge of previously learned tasks is lost. A popular approach to mitigate forgetting during continual learning is to maintain a small buffer of previously-seen samples and to replay them during training. However, this approach is limited by the small buffer size, and while forgetting is reduced, it is still present. In this paper, we propose a novel loss function, STAR, that exploits the worst-case parameter perturbation that reduces the KL-divergence of model predictions with that of its local parameter neighborhood to promote stability and alleviate forgetting. STAR can be combined with almost any existing rehearsal-based method as a plug-and-play component. We empirically show that STAR consistently improves the performance of existing methods by up to 15% across varying baselines and achieves superior or competitive accuracy to that of state-of-the-art methods aimed at improving rehearsal-based continual learning.
ADAPT to Robustify Prompt Tuning Vision Transformers
Mar 19, 2024



The performance of deep models, including Vision Transformers, is known to be vulnerable to adversarial attacks. Many existing defenses against these attacks, such as adversarial training, rely on full-model fine-tuning to induce robustness in the models. These defenses require storing a copy of the entire model, that can have billions of parameters, for each task. At the same time, parameter-efficient prompt tuning is used to adapt large transformer-based models to downstream tasks without the need to save large copies. In this paper, we examine parameter-efficient prompt tuning of Vision Transformers for downstream tasks under the lens of robustness. We show that previous adversarial defense methods, when applied to the prompt tuning paradigm, suffer from gradient obfuscation and are vulnerable to adaptive attacks. We introduce ADAPT, a novel framework for performing adaptive adversarial training in the prompt tuning paradigm. Our method achieves competitive robust accuracy of ~40% w.r.t. SOTA robustness methods using full-model fine-tuning, by tuning only ~1% of the number of parameters.
ZeroGrad : Mitigating and Explaining Catastrophic Overfitting in FGSM Adversarial Training
Mar 29, 2021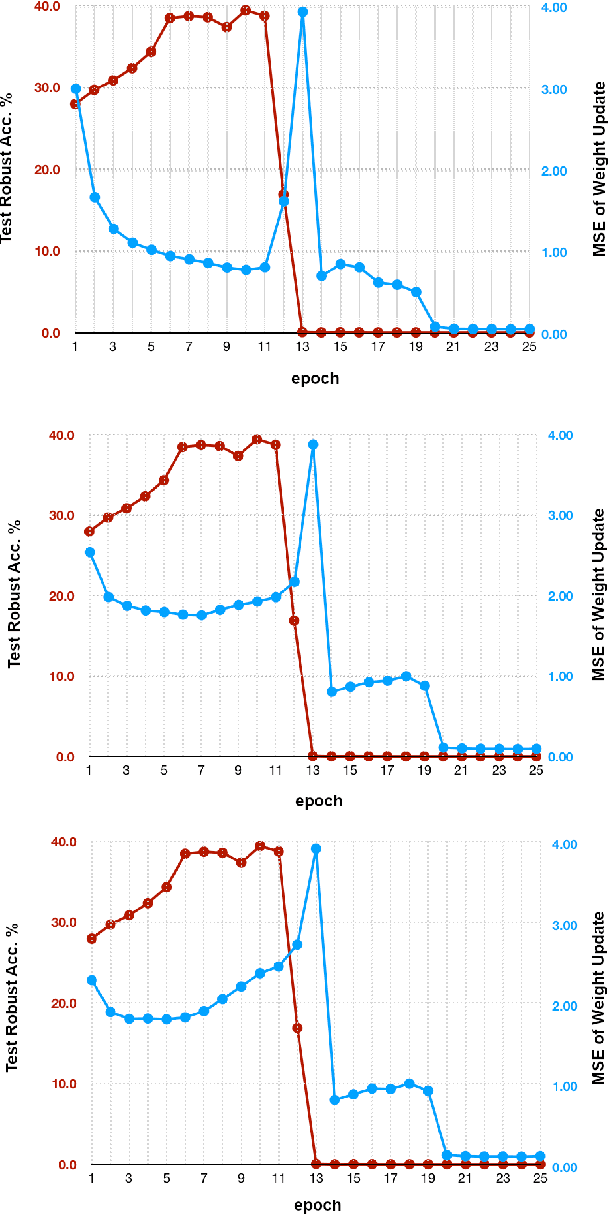
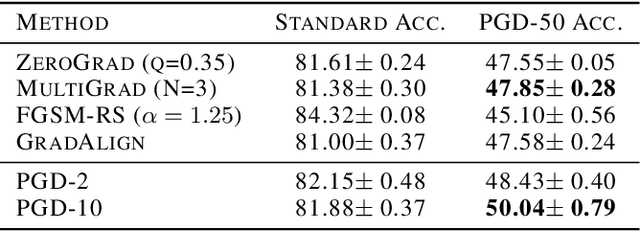
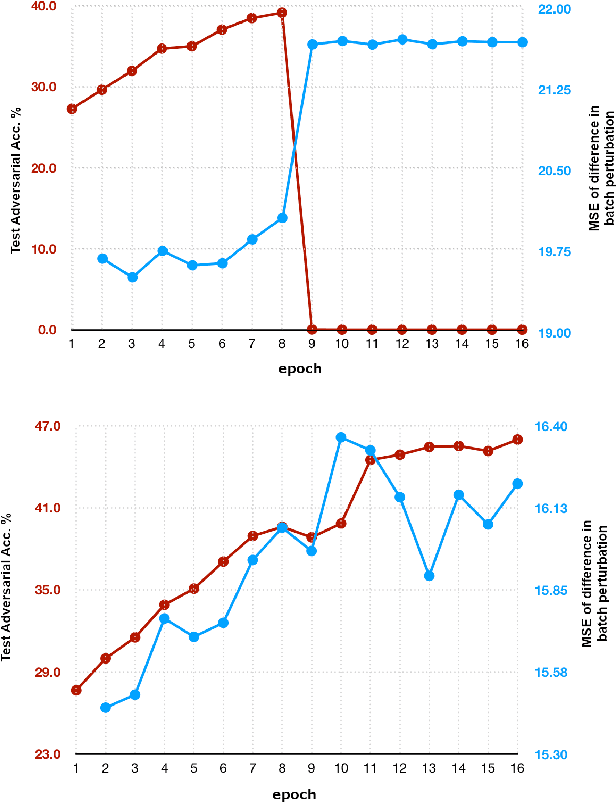
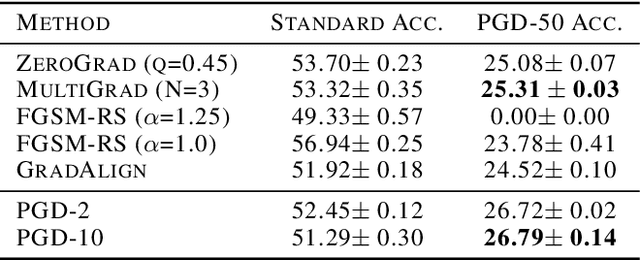
Making deep neural networks robust to small adversarial noises has recently been sought in many applications. Adversarial training through iterative projected gradient descent (PGD) has been established as one of the mainstream ideas to achieve this goal. However, PGD is computationally demanding and often prohibitive in case of large datasets and models. For this reason, single-step PGD, also known as FGSM, has recently gained interest in the field. Unfortunately, FGSM-training leads to a phenomenon called ``catastrophic overfitting," which is a sudden drop in the adversarial accuracy under the PGD attack. In this paper, we support the idea that small input gradients play a key role in this phenomenon, and hence propose to zero the input gradient elements that are small for crafting FGSM attacks. Our proposed idea, while being simple and efficient, achieves competitive adversarial accuracy on various datasets.