 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTAR: Stability-Inducing Weight Perturbation for Continual Learning
Mar 03, 2025



Humans can naturally learn new and varying tasks in a sequential manner. Continual learning is a class of learning algorithms that updates its learned model as it sees new data (on potentially new tasks) in a sequence. A key challenge in continual learning is that as the model is updated to learn new tasks, it becomes susceptible to catastrophic forgetting, where knowledge of previously learned tasks is lost. A popular approach to mitigate forgetting during continual learning is to maintain a small buffer of previously-seen samples and to replay them during training. However, this approach is limited by the small buffer size, and while forgetting is reduced, it is still present. In this paper, we propose a novel loss function, STAR, that exploits the worst-case parameter perturbation that reduces the KL-divergence of model predictions with that of its local parameter neighborhood to promote stability and alleviate forgetting. STAR can be combined with almost any existing rehearsal-based method as a plug-and-play component. We empirically show that STAR consistently improves the performance of existing methods by up to 15% across varying baselines and achieves superior or competitive accuracy to that of state-of-the-art methods aimed at improving rehearsal-based continual learning.
ADAPT to Robustify Prompt Tuning Vision Transformers
Mar 19, 2024



The performance of deep models, including Vision Transformers, is known to be vulnerable to adversarial attacks. Many existing defenses against these attacks, such as adversarial training, rely on full-model fine-tuning to induce robustness in the models. These defenses require storing a copy of the entire model, that can have billions of parameters, for each task. At the same time, parameter-efficient prompt tuning is used to adapt large transformer-based models to downstream tasks without the need to save large copies. In this paper, we examine parameter-efficient prompt tuning of Vision Transformers for downstream tasks under the lens of robustness. We show that previous adversarial defense methods, when applied to the prompt tuning paradigm, suffer from gradient obfuscation and are vulnerable to adaptive attacks. We introduce ADAPT, a novel framework for performing adaptive adversarial training in the prompt tuning paradigm. Our method achieves competitive robust accuracy of ~40% w.r.t. SOTA robustness methods using full-model fine-tuning, by tuning only ~1% of the number of parameters.
SAIF: Sparse Adversarial and Interpretable Attack Framework
Dec 14, 2022



Adversarial attacks hamper the decision-making ability of neural networks by perturbing the input signal. The addition of calculated small distortion to images, for instance, can deceive a well-trained image classification network. In this work, we propose a novel attack technique called Sparse Adversarial and Interpretable Attack Framework (SAIF). Specifically, we design imperceptible attacks that contain low-magnitude perturbations at a small number of pixels and leverage these sparse attacks to reveal the vulnerability of classifiers. We use the Frank-Wolfe (conditional gradient) algorithm to simultaneously optimize the attack perturbations for bounded magnitude and sparsity with $O(1/\sqrt{T})$ convergence. Empirical results show that SAIF computes highly imperceptible and interpretable adversarial examples, and outperforms state-of-the-art sparse attack methods on the ImageNet dataset.
Volumetric Propagation Network: Stereo-LiDAR Fusion for Long-Range Depth Estimation
Mar 24, 2021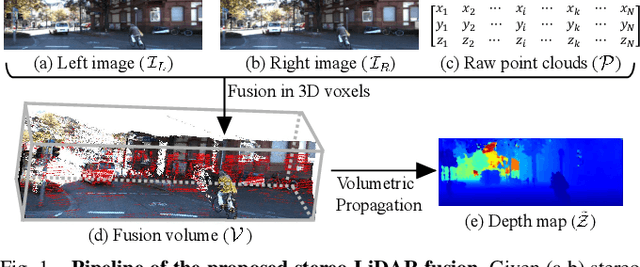
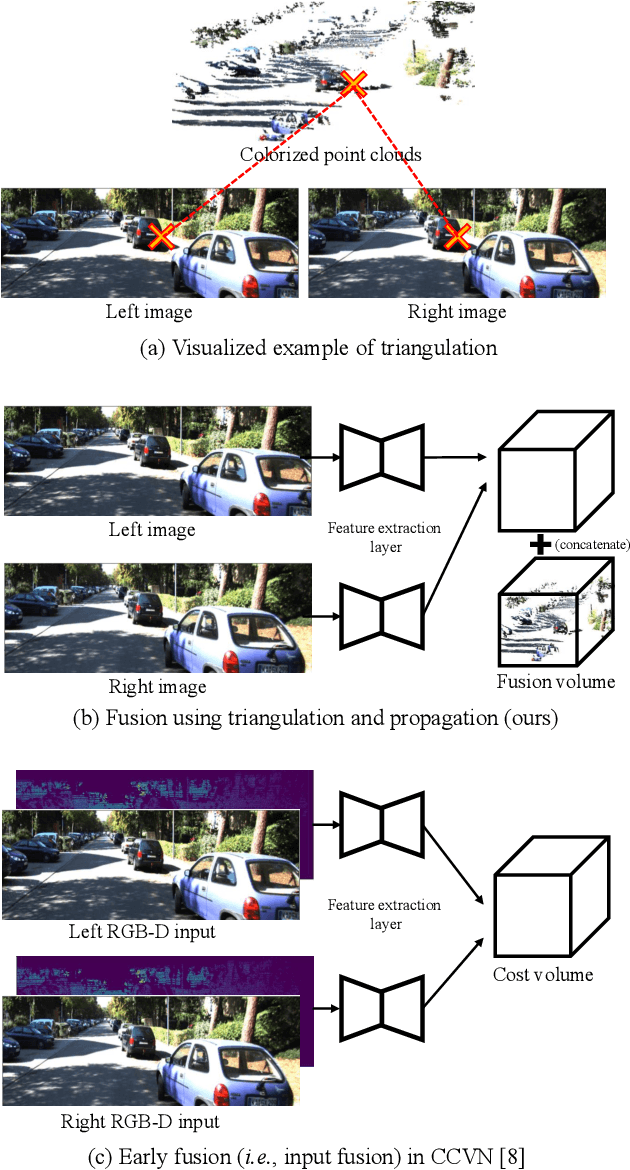
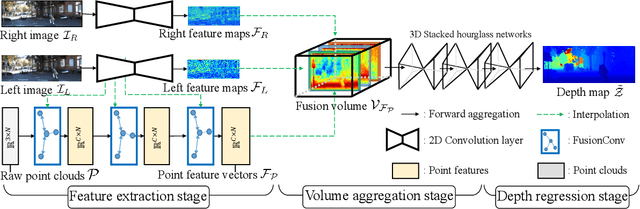
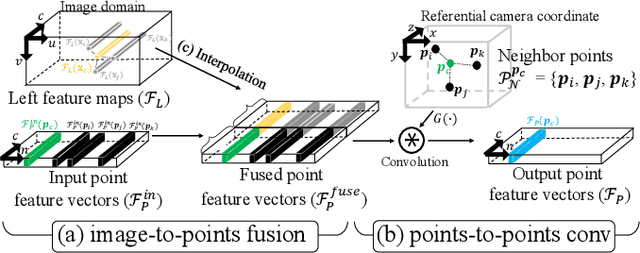
Stereo-LiDAR fusion is a promising task in that we can utilize two different types of 3D perceptions for practical usage -- dense 3D information (stereo cameras) and highly-accurate sparse point clouds (LiDAR). However, due to their different modalities and structures, the method of aligning sensor data is the key for successful sensor fusion. To this end, we propose a geometry-aware stereo-LiDAR fusion network for long-range depth estimation, called volumetric propagation network. The key idea of our network is to exploit sparse and accurate point clouds as a cue for guiding correspondences of stereo images in a unified 3D volume space. Unlike existing fusion strategies, we directly embed point clouds into the volume, which enables us to propagate valid information into nearby voxels in the volume, and to reduce the uncertainty of correspondences. Thus, it allows us to fuse two different input modalities seamlessly and regress a long-range depth map. Our fusion is further enhanced by a newly proposed feature extraction layer for point clouds guided by images: FusionConv. FusionConv extracts point cloud features that consider both semantic (2D image domain) and geometric (3D domain) relations and aid fusion at the volume. Our network achieves state-of-the-art performance on the KITTI and the Virtual-KITTI datasets among recent stereo-LiDAR fusion methods.
CD-UAP: Class Discriminative Universal Adversarial Perturbation
Oct 07, 2020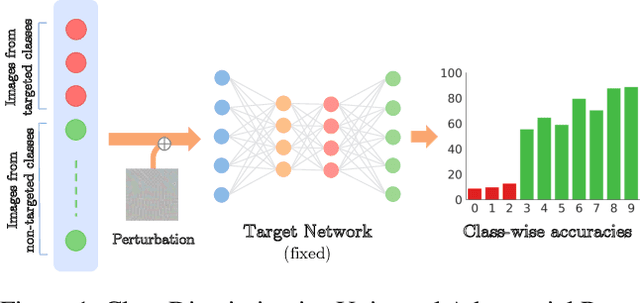

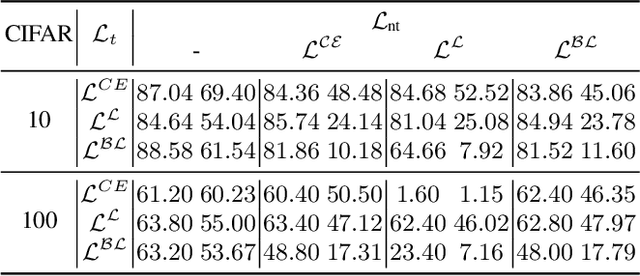
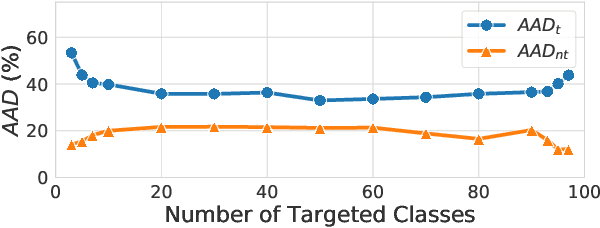
A single universal adversarial perturbation (UAP) can be added to all natural images to change most of their predicted class labels. It is of high practical relevance for an attacker to have flexible control over the targeted classes to be attacked, however, the existing UAP method attacks samples from all classes. In this work, we propose a new universal attack method to generate a single perturbation that fools a target network to misclassify only a chosen group of classes, while having limited influence on the remaining classes. Since the proposed attack generates a universal adversarial perturbation that is discriminative to targeted and non-targeted classes, we term it class discriminative universal adversarial perturbation (CD-UAP). We propose one simple yet effective algorithm framework, under which we design and compare various loss function configurations tailored for the class discriminative universal attack. The proposed approach has been evaluated with extensive experiments on various benchmark datasets. Additionally, our proposed approach achieves state-of-the-art performance for the original task of UAP attacking all classes, which demonstrates the effectiveness of our approach.
Double Targeted Universal Adversarial Perturbations
Oct 07, 2020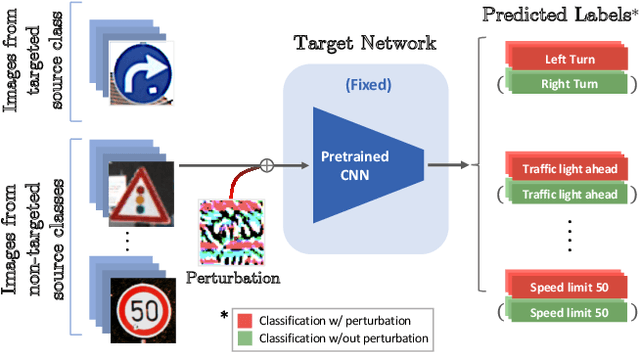



Despite their impressive performance, deep neural networks (DNNs) are widely known to be vulnerable to adversarial attacks, which makes it challenging for them to be deployed in security-sensitive applications, such as autonomous driving. Image-dependent perturbations can fool a network for one specific image, while universal adversarial perturbations are capable of fooling a network for samples from all classes without selection. We introduce a double targeted universal adversarial perturbations (DT-UAPs) to bridge the gap between the instance-discriminative image-dependent perturbations and the generic universal perturbations. This universal perturbation attacks one targeted source class to sink class, while having a limited adversarial effect on other non-targeted source classes, for avoiding raising suspicions. Targeting the source and sink class simultaneously, we term it double targeted attack (DTA). This provides an attacker with the freedom to perform precise attacks on a DNN model while raising little suspicion. We show the effectiveness of the proposed DTA algorithm on a wide range of datasets and also demonstrate its potential as a physical attack.
Data from Model: Extracting Data from Non-robust and Robust Models
Jul 13, 2020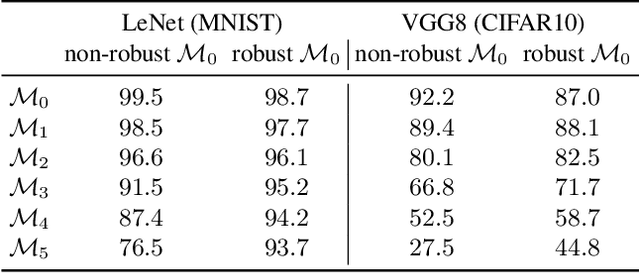

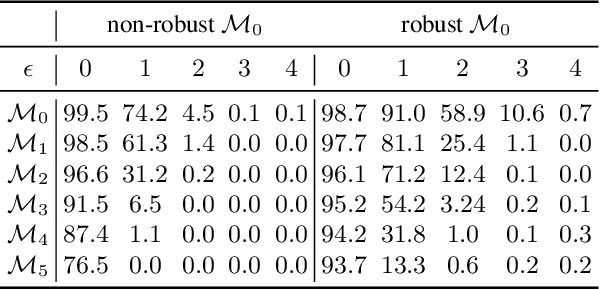
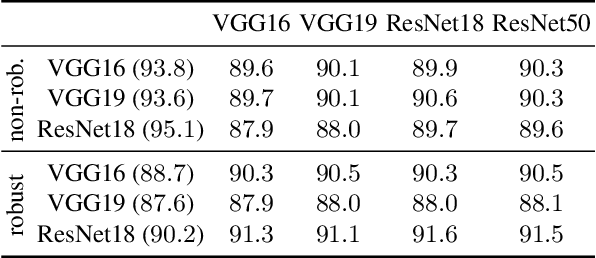
The essence of deep learning is to exploit data to train a deep neural network (DNN) model. This work explores the reverse process of generating data from a model, attempting to reveal the relationship between the data and the model. We repeat the process of Data to Model (DtM) and Data from Model (DfM) in sequence and explore the loss of feature mapping information by measuring the accuracy drop on the original validation dataset. We perform this experiment for both a non-robust and robust origin model. Our results show that the accuracy drop is limited even after multiple sequences of DtM and DfM, especially for robust models. The success of this cycling transformation can be attributed to the shared feature mapping existing in data and model. Using the same data, we observe that different DtM processes result in models having different features, especially for different network architecture families, even though they achieve comparable performance.
Understanding Adversarial Examples from the Mutual Influence of Images and Perturbations
Jul 13, 2020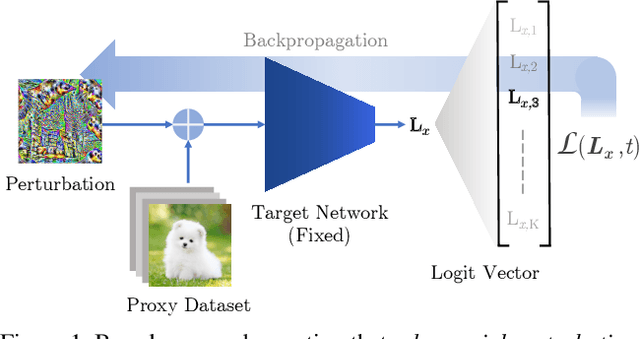

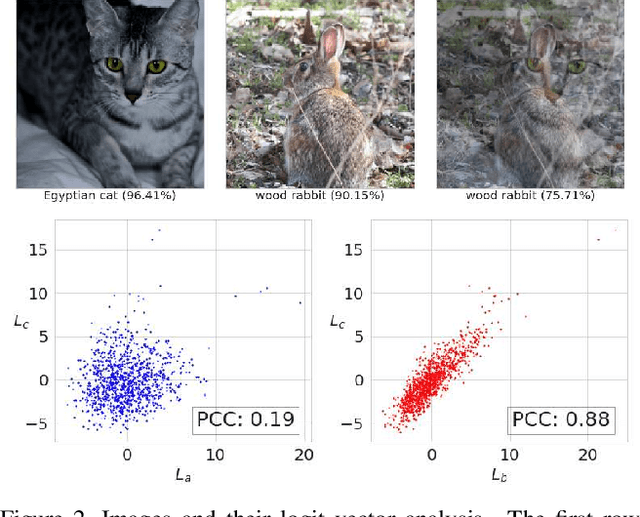

A wide variety of works have explored the reason for the existence of adversarial examples, but there is no consensus on the explanation. We propose to treat the DNN logits as a vector for feature representation, and exploit them to analyze the mutual influence of two independent inputs based on the Pearson correlation coefficient (PCC). We utilize this vector representation to understand adversarial examples by disentangling the clean images and adversarial perturbations, and analyze their influence on each other. Our results suggest a new perspective towards the relationship between images and universal perturbations: Universal perturbations contain dominant features, and images behave like noise to them. This feature perspective leads to a new method for generating targeted universal adversarial perturbations using random source images. We are the first to achieve the challenging task of a targeted universal attack without utilizing original training data. Our approach using a proxy dataset achieves comparable performance to the state-of-the-art baselines which utilize the original training dataset.