 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBidirectional Domain Mixup for Domain Adaptive Semantic Segmentation
Mar 17, 2023



Mixup provides interpolated training samples and allows the model to obtain smoother decision boundaries for better generalization. The idea can be naturally applied to the domain adaptation task, where we can mix the source and target samples to obtain domain-mixed samples for better adaptation. However, the extension of the idea from classification to segmentation (i.e., structured output) is nontrivial. This paper systematically studies the impact of mixup under the domain adaptaive semantic segmentation task and presents a simple yet effective mixup strategy called Bidirectional Domain Mixup (BDM). In specific, we achieve domain mixup in two-step: cut and paste. Given the warm-up model trained from any adaptation techniques, we forward the source and target samples and perform a simple threshold-based cut out of the unconfident regions (cut). After then, we fill-in the dropped regions with the other domain region patches (paste). In doing so, we jointly consider class distribution, spatial structure, and pseudo label confidence. Based on our analysis, we found that BDM leaves domain transferable regions by cutting, balances the dataset-level class distribution while preserving natural scene context by pasting. We coupled our proposal with various state-of-the-art adaptation models and observe significant improvement consistently. We also provide extensive ablation experiments to empirically verify our main components of the framework. Visit our project page with the code at https://sites.google.com/view/bidirectional-domain-mixup
Data from Model: Extracting Data from Non-robust and Robust Models
Jul 13, 2020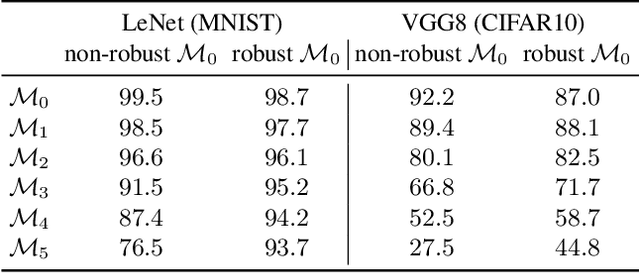

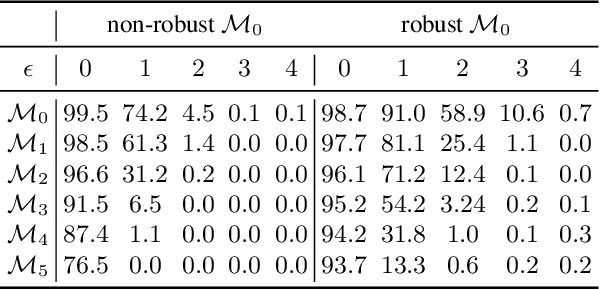
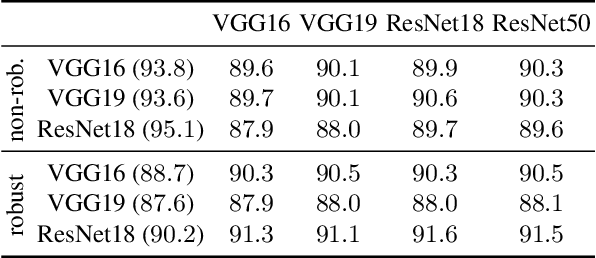
The essence of deep learning is to exploit data to train a deep neural network (DNN) model. This work explores the reverse process of generating data from a model, attempting to reveal the relationship between the data and the model. We repeat the process of Data to Model (DtM) and Data from Model (DfM) in sequence and explore the loss of feature mapping information by measuring the accuracy drop on the original validation dataset. We perform this experiment for both a non-robust and robust origin model. Our results show that the accuracy drop is limited even after multiple sequences of DtM and DfM, especially for robust models. The success of this cycling transformation can be attributed to the shared feature mapping existing in data and model. Using the same data, we observe that different DtM processes result in models having different features, especially for different network architecture families, even though they achieve comparable performance.
Understanding Adversarial Examples from the Mutual Influence of Images and Perturbations
Jul 13, 2020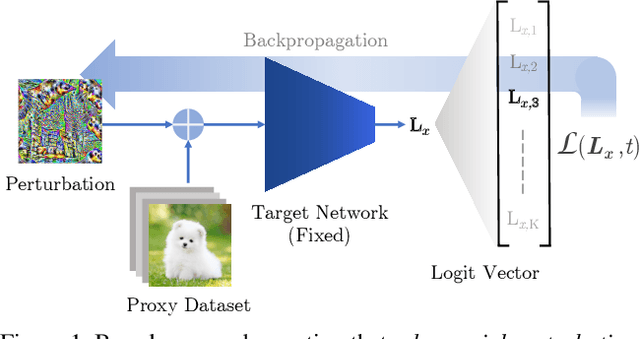

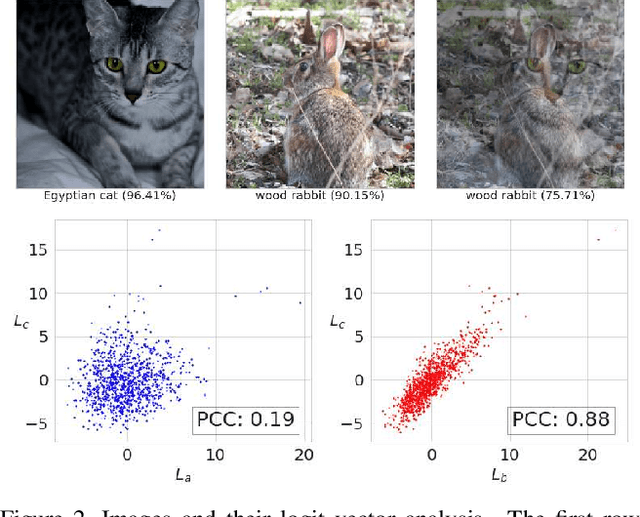

A wide variety of works have explored the reason for the existence of adversarial examples, but there is no consensus on the explanation. We propose to treat the DNN logits as a vector for feature representation, and exploit them to analyze the mutual influence of two independent inputs based on the Pearson correlation coefficient (PCC). We utilize this vector representation to understand adversarial examples by disentangling the clean images and adversarial perturbations, and analyze their influence on each other. Our results suggest a new perspective towards the relationship between images and universal perturbations: Universal perturbations contain dominant features, and images behave like noise to them. This feature perspective leads to a new method for generating targeted universal adversarial perturbations using random source images. We are the first to achieve the challenging task of a targeted universal attack without utilizing original training data. Our approach using a proxy dataset achieves comparable performance to the state-of-the-art baselines which utilize the original training dataset.