 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-Conditioned Test-Time Self-Training for Large Language Models
May 14, 2026Large language models (LLMs) are typically deployed with fixed parameters, and their performance is often improved by allocating more computation at inference time. While such test-time scaling can be effective, it cannot correct model misconceptions or adapt the model to the specific structure of an individual query. Test-time optimization addresses this limitation by enabling parameter updates during inference, but existing approaches either rely on external data or optimize generic self-supervised objectives that lack query-specific alignment. In this work, we propose Query-Conditioned Test-Time Self-Training (QueST), a framework that adapts model parameters during inference using supervision derived directly from the input query. Our key insight is that the input query itself encodes latent signals sufficient for constructing structurally related problem--solution pairs. Based on this, QueST generates such query-conditioned pairs and uses them as supervision for parameter-efficient fine-tuning at test time. The adapted model is then used to produce the final answer, enabling query-specific adaptation without any external data. Across seven mathematical reasoning benchmarks and the GPQA-Diamond scientific reasoning benchmark, QueST consistently outperforms strong test-time optimization baselines. These results demonstrate that query-conditioned self-training is an effective and practical paradigm for test-time adaptation in LLMs. Code is available at https://chssong.github.io/Query-Conditioned-TTST/.
Rethinking Electro-Optical Vision Foundation Models for Remote Sensing Retrieval: A Controlled Comparison with Generalist VFM
May 04, 2026Vision foundation models have attracted significant attention for their ability to leverage large-scale unlabeled visual data. This advantage is particularly important in remote sensing, where data acquisition is costly and annotation often requires expert knowledge. Recent electro-optical vision foundation models aim to learn domain-specific representations from remote sensing imagery, but it remains unclear whether they are more effective than strong generalist vision foundation models under retrieval-based evaluation. In this study, we conduct a controlled comparison between representative EO-specific and generalist vision foundation models for remote sensing image retrieval. Using the same datasets, retrieval protocol, and evaluation metric, we evaluate both in-domain performance and cross-scene generalization. Our results show that strong generalist vision foundation models are competitive with, and in some cases outperform, existing EO-specific models. Moreover, EO-specific models often suffer from substantial degradation under cross-scene evaluation, while generalist models show more stable transfer. These findings suggest that EO pretraining alone does not guarantee stronger retrieval-oriented remote sensing representations. We discuss the limitations of current EO-specific pretraining strategies and highlight the need for future EO vision foundation models to better exploit the physical, spatial, spectral, and geographic characteristics of remote sensing imagery.
Efficient Test-Time Optimization for Depth Completion via Low-Rank Decoder Adaptation
Mar 03, 2026Zero-shot depth completion has gained attention for its ability to generalize across environments without sensor-specific datasets or retraining. However, most existing approaches rely on diffusion-based test-time optimization, which is computationally expensive due to iterative denoising. Recent visual-prompt-based methods reduce training cost but still require repeated forward--backward passes through the full frozen network to optimize input-level prompts, resulting in slow inference. In this work, we show that adapting only the decoder is sufficient for effective test-time optimization, as depth foundation models concentrate depth-relevant information within a low-dimensional decoder subspace. Based on this insight, we propose a lightweight test-time adaptation method that updates only this low-dimensional subspace using sparse depth supervision. Our approach achieves state-of-the-art performance, establishing a new Pareto frontier between accuracy and efficiency for test-time adaptation. Extensive experiments on five indoor and outdoor datasets demonstrate consistent improvements over prior methods, highlighting the practicality of fast zero-shot depth completion.
Station2Radar: query conditioned gaussian splatting for precipitation field
Feb 28, 2026Precipitation forecasting relies on heterogeneous data. Weather radar is accurate, but coverage is geographically limited and costly to maintain. Weather stations provide accurate but sparse point measurements, while satellites offer dense, high-resolution coverage without direct rainfall retrieval. To overcome these limitations, we propose Query-Conditioned Gaussian Splatting (QCGS), the first framework to fuse automatic weather station (AWS) observations with satellite imagery for generating precipitation fields. Unlike conventional 2D Gaussian splatting, which renders the entire image plane, QCGS selectively renders only queried precipitation regions, avoiding unnecessary computation in non-precipitating areas while preserving sharp precipitation structures. The framework combines a radar point proposal network that identifies rainfall-support locations with an implicit neural representation (INR) network that predicts Gaussian parameters for each point. QCGS enables efficient, resolution-flexible precipitation field generation in real time. Through extensive evaluation with benchmark precipitation products, QCGS demonstrates over 50\% improvement in RMSE compared to conventional gridded precipitation products, and consistently maintains high performance across multiple spatiotemporal scales.
AIS-LLM: A Unified Framework for Maritime Trajectory Prediction, Anomaly Detection, and Collision Risk Assessment with Explainable Forecasting
Aug 11, 2025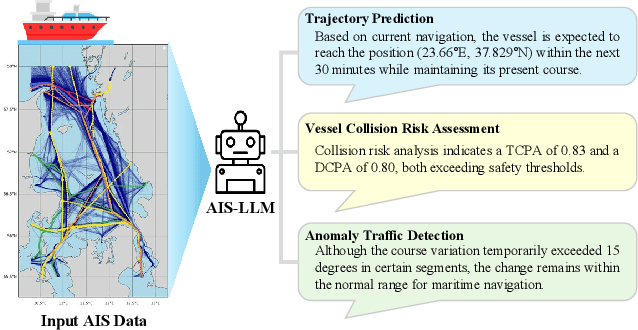

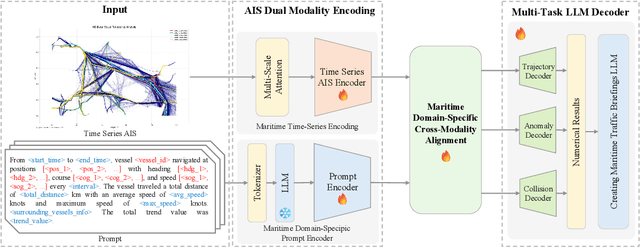

With the increase in maritime traffic and the mandatory implementation of the Automatic Identification System (AIS), the importance and diversity of maritime traffic analysis tasks based on AIS data, such as vessel trajectory prediction, anomaly detection, and collision risk assessment, is rapidly growing. However, existing approaches tend to address these tasks individually, making it difficult to holistically consider complex maritime situations. To address this limitation, we propose a novel framework, AIS-LLM, which integrates time-series AIS data with a large language model (LLM). AIS-LLM consists of a Time-Series Encoder for processing AIS sequences, an LLM-based Prompt Encoder, a Cross-Modality Alignment Module for semantic alignment between time-series data and textual prompts, and an LLM-based Multi-Task Decoder. This architecture enables the simultaneous execution of three key tasks: trajectory prediction, anomaly detection, and risk assessment of vessel collisions within a single end-to-end system. Experimental results demonstrate that AIS-LLM outperforms existing methods across individual tasks, validating its effectiveness. Furthermore, by integratively analyzing task outputs to generate situation summaries and briefings, AIS-LLM presents the potential for more intelligent and efficient maritime traffic management.
Data-driven Precipitation Nowcasting Using Satellite Imagery
Dec 16, 2024Accurate precipitation forecasting is crucial for early warnings of disasters, such as floods and landslides. Traditional forecasts rely on ground-based radar systems, which are space-constrained and have high maintenance costs. Consequently, most developing countries depend on a global numerical model with low resolution, instead of operating their own radar systems. To mitigate this gap, we propose the Neural Precipitation Model (NPM), which uses global-scale geostationary satellite imagery. NPM predicts precipitation for up to six hours, with an update every hour. We take three key channels to discriminate rain clouds as input: infrared radiation (at a wavelength of 10.5 $\mu m$), upper- (6.3 $\mu m$), and lower- (7.3 $\mu m$) level water vapor channels. Additionally, NPM introduces positional encoders to capture seasonal and temporal patterns, accounting for variations in precipitation. Our experimental results demonstrate that NPM can predict rainfall in real-time with a resolution of 2 km. The code and dataset are available at https://github.com/seominseok0429/Data-driven-Precipitation-Nowcasting-Using-Satellite-Imagery.
Masked Autoregressive Model for Weather Forecasting
Sep 30, 2024The growing impact of global climate change amplifies the need for accurate and reliable weather forecasting. Traditional autoregressive approaches, while effective for temporal modeling, suffer from error accumulation in long-term prediction tasks. The lead time embedding method has been suggested to address this issue, but it struggles to maintain crucial correlations in atmospheric events. To overcome these challenges, we propose the Masked Autoregressive Model for Weather Forecasting (MAM4WF). This model leverages masked modeling, where portions of the input data are masked during training, allowing the model to learn robust spatiotemporal relationships by reconstructing the missing information. MAM4WF combines the advantages of both autoregressive and lead time embedding methods, offering flexibility in lead time modeling while iteratively integrating predictions. We evaluate MAM4WF across weather, climate forecasting, and video frame prediction datasets, demonstrating superior performance on five test datasets.
ACE Metric: Advection and Convection Evaluation for Accurate Weather Forecasting
Jun 07, 2024Recently, data-driven weather forecasting methods have received significant attention for surpassing the RMSE performance of traditional NWP (Numerical Weather Prediction)-based methods. However, data-driven models are tuned to minimize the loss between forecasted data and ground truths, often using pixel-wise loss. This can lead to models that produce blurred outputs, which, despite being significantly different in detail from the actual weather conditions, still demonstrate low RMSE values. Although evaluation metrics from the computer vision field, such as PSNR, SSIM, and FVD, can be used, they are not entirely suitable for weather variables. This is because weather variables exhibit continuous physical changes over time and lack the distinct boundaries of objects typically seen in computer vision images. To resolve these issues, we propose the advection and convection Error (ACE) metric, specifically designed to assess how well models predict advection and convection, which are significant atmospheric transfer methods. We have validated the ACE evaluation metric on the WeatherBench2 and MovingMNIST datasets.
Long-Term Typhoon Trajectory Prediction: A Physics-Conditioned Approach Without Reanalysis Data
Jan 28, 2024In the face of escalating climate changes, typhoon intensities and their ensuing damage have surged. Accurate trajectory prediction is crucial for effective damage control. Traditional physics-based models, while comprehensive, are computationally intensive and rely heavily on the expertise of forecasters. Contemporary data-driven methods often rely on reanalysis data, which can be considered to be the closest to the true representation of weather conditions. However, reanalysis data is not produced in real-time and requires time for adjustment because prediction models are calibrated with observational data. This reanalysis data, such as ERA5, falls short in challenging real-world situations. Optimal preparedness necessitates predictions at least 72 hours in advance, beyond the capabilities of standard physics models. In response to these constraints, we present an approach that harnesses real-time Unified Model (UM) data, sidestepping the limitations of reanalysis data. Our model provides predictions at 6-hour intervals for up to 72 hours in advance and outperforms both state-of-the-art data-driven methods and numerical weather prediction models. In line with our efforts to mitigate adversities inflicted by \rthree{typhoons}, we release our preprocessed \textit{PHYSICS TRACK} dataset, which includes ERA5 reanalysis data, typhoon best-track, and UM forecast data.
Deterministic Guidance Diffusion Model for Probabilistic Weather Forecasting
Dec 05, 2023



Weather forecasting requires not only accuracy but also the ability to perform probabilistic prediction. However, deterministic weather forecasting methods do not support probabilistic predictions, and conversely, probabilistic models tend to be less accurate. To address these challenges, in this paper, we introduce the \textbf{\textit{D}}eterministic \textbf{\textit{G}}uidance \textbf{\textit{D}}iffusion \textbf{\textit{M}}odel (DGDM) for probabilistic weather forecasting, integrating benefits of both deterministic and probabilistic approaches. During the forward process, both the deterministic and probabilistic models are trained end-to-end. In the reverse process, weather forecasting leverages the predicted result from the deterministic model, using as an intermediate starting point for the probabilistic model. By fusing deterministic models with probabilistic models in this manner, DGDM is capable of providing accurate forecasts while also offering probabilistic predictions. To evaluate DGDM, we assess it on the global weather forecasting dataset (WeatherBench) and the common video frame prediction benchmark (Moving MNIST). We also introduce and evaluate the Pacific Northwest Windstorm (PNW)-Typhoon weather satellite dataset to verify the effectiveness of DGDM in high-resolution regional forecasting. As a result of our experiments, DGDM achieves state-of-the-art results not only in global forecasting but also in regional forecasting. The code is available at: \url{https://github.com/DongGeun-Yoon/DGDM}.