 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnriched Feature Representation and Motion Prediction Module for MOSEv2 Track of 7th LSVOS Challenge: 3rd Place Solution
Sep 19, 2025Video object segmentation (VOS) is a challenging task with wide applications such as video editing and autonomous driving. While Cutie provides strong query-based segmentation and SAM2 offers enriched representations via a pretrained ViT encoder, each has limitations in feature capacity and temporal modeling. In this report, we propose a framework that integrates their complementary strengths by replacing the encoder of Cutie with the ViT encoder of SAM2 and introducing a motion prediction module for temporal stability. We further adopt an ensemble strategy combining Cutie, SAM2, and our variant, achieving 3rd place in the MOSEv2 track of the 7th LSVOS Challenge. We refer to our final model as SCOPE (SAM2-CUTIE Object Prediction Ensemble). This demonstrates the effectiveness of enriched feature representation and motion prediction for robust video object segmentation. The code is available at https://github.com/2025-LSVOS-3rd-place/MOSEv2_3rd_place.
Early Timestep Zero-Shot Candidate Selection for Instruction-Guided Image Editing
Apr 18, 2025Despite recent advances in diffusion models, achieving reliable image generation and editing remains challenging due to the inherent diversity induced by stochastic noise in the sampling process. Instruction-guided image editing with diffusion models offers user-friendly capabilities, yet editing failures, such as background distortion, frequently occur. Users often resort to trial and error, adjusting seeds or prompts to achieve satisfactory results, which is inefficient. While seed selection methods exist for Text-to-Image (T2I) generation, they depend on external verifiers, limiting applicability, and evaluating multiple seeds increases computational complexity. To address this, we first establish a multiple-seed-based image editing baseline using background consistency scores, achieving Best-of-N performance without supervision. Building on this, we introduce ELECT (Early-timestep Latent Evaluation for Candidate Selection), a zero-shot framework that selects reliable seeds by estimating background mismatches at early diffusion timesteps, identifying the seed that retains the background while modifying only the foreground. ELECT ranks seed candidates by a background inconsistency score, filtering unsuitable samples early based on background consistency while preserving editability. Beyond standalone seed selection, ELECT integrates into instruction-guided editing pipelines and extends to Multimodal Large-Language Models (MLLMs) for joint seed and prompt selection, further improving results when seed selection alone is insufficient. Experiments show that ELECT reduces computational costs (by 41 percent on average and up to 61 percent) while improving background consistency and instruction adherence, achieving around 40 percent success rates in previously failed cases - without any external supervision or training.
Deterministic Guidance Diffusion Model for Probabilistic Weather Forecasting
Dec 05, 2023



Weather forecasting requires not only accuracy but also the ability to perform probabilistic prediction. However, deterministic weather forecasting methods do not support probabilistic predictions, and conversely, probabilistic models tend to be less accurate. To address these challenges, in this paper, we introduce the \textbf{\textit{D}}eterministic \textbf{\textit{G}}uidance \textbf{\textit{D}}iffusion \textbf{\textit{M}}odel (DGDM) for probabilistic weather forecasting, integrating benefits of both deterministic and probabilistic approaches. During the forward process, both the deterministic and probabilistic models are trained end-to-end. In the reverse process, weather forecasting leverages the predicted result from the deterministic model, using as an intermediate starting point for the probabilistic model. By fusing deterministic models with probabilistic models in this manner, DGDM is capable of providing accurate forecasts while also offering probabilistic predictions. To evaluate DGDM, we assess it on the global weather forecasting dataset (WeatherBench) and the common video frame prediction benchmark (Moving MNIST). We also introduce and evaluate the Pacific Northwest Windstorm (PNW)-Typhoon weather satellite dataset to verify the effectiveness of DGDM in high-resolution regional forecasting. As a result of our experiments, DGDM achieves state-of-the-art results not only in global forecasting but also in regional forecasting. The code is available at: \url{https://github.com/DongGeun-Yoon/DGDM}.
Soundini: Sound-Guided Diffusion for Natural Video Editing
Apr 13, 2023



We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound. Please visit our page: https://kuai-lab.github.io/soundini-gallery/.
IFQA: Interpretable Face Quality Assessment
Nov 17, 2022



Existing face restoration models have relied on general assessment metrics that do not consider the characteristics of facial regions. Recent works have therefore assessed their methods using human studies, which is not scalable and involves significant effort. This paper proposes a novel face-centric metric based on an adversarial framework where a generator simulates face restoration and a discriminator assesses image quality. Specifically, our per-pixel discriminator enables interpretable evaluation that cannot be provided by traditional metrics. Moreover, our metric emphasizes facial primary regions considering that even minor changes to the eyes, nose, and mouth significantly affect human cognition. Our face-oriented metric consistently surpasses existing general or facial image quality assessment metrics by impressive margins. We demonstrate the generalizability of the proposed strategy in various architectural designs and challenging scenarios. Interestingly, we find that our IFQA can lead to performance improvement as an objective function.
Lightweight Alpha Matting Network Using Distillation-Based Channel Pruning
Oct 14, 2022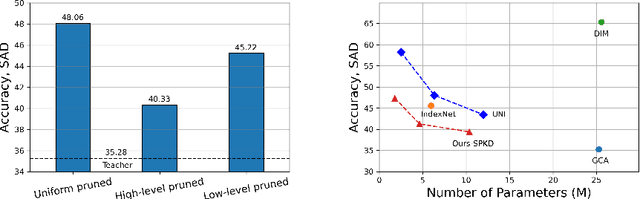

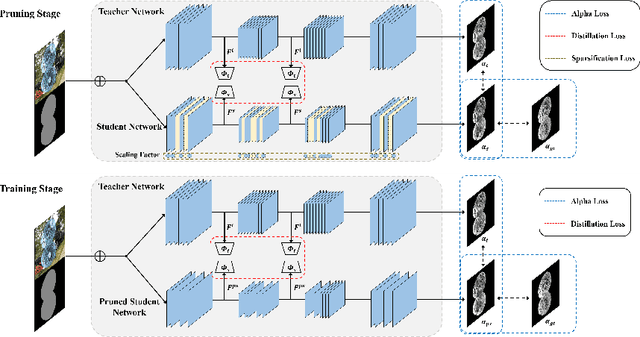
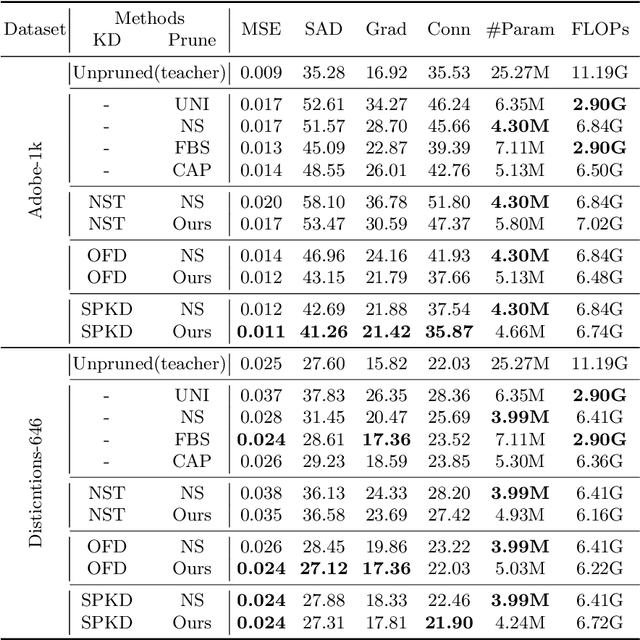
Recently, alpha matting has received a lot of attention because of its usefulness in mobile applications such as selfies. Therefore, there has been a demand for a lightweight alpha matting model due to the limited computational resources of commercial portable devices. To this end, we suggest a distillation-based channel pruning method for the alpha matting networks. In the pruning step, we remove channels of a student network having fewer impacts on mimicking the knowledge of a teacher network. Then, the pruned lightweight student network is trained by the same distillation loss. A lightweight alpha matting model from the proposed method outperforms existing lightweight methods. To show superiority of our algorithm, we provide various quantitative and qualitative experiments with in-depth analyses. Furthermore, we demonstrate the versatility of the proposed distillation-based channel pruning method by applying it to semantic segmentation.
Weakly-Supervised Stitching Network for Real-World Panoramic Image Generation
Sep 13, 2022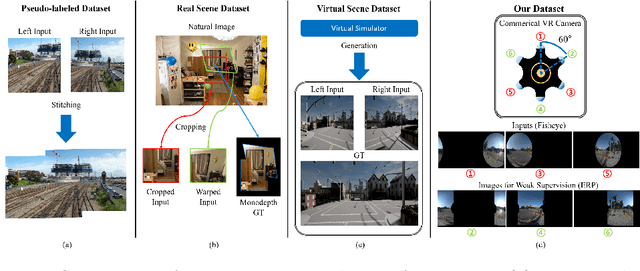
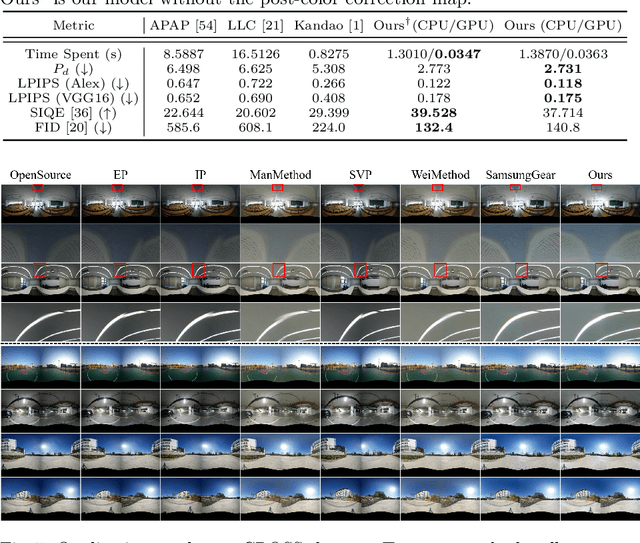
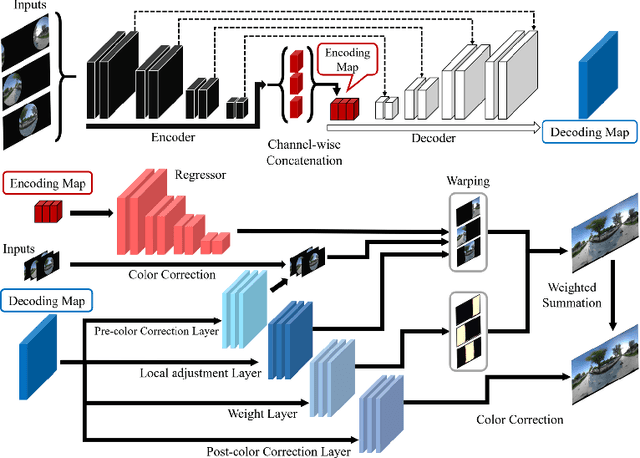

Recently, there has been growing attention on an end-to-end deep learning-based stitching model. However, the most challenging point in deep learning-based stitching is to obtain pairs of input images with a narrow field of view and ground truth images with a wide field of view captured from real-world scenes. To overcome this difficulty, we develop a weakly-supervised learning mechanism to train the stitching model without requiring genuine ground truth images. In addition, we propose a stitching model that takes multiple real-world fisheye images as inputs and creates a 360 output image in an equirectangular projection format. In particular, our model consists of color consistency corrections, warping, and blending, and is trained by perceptual and SSIM losses. The effectiveness of the proposed algorithm is verified on two real-world stitching datasets.
Domain Adaptation without Source Data
Jul 11, 2020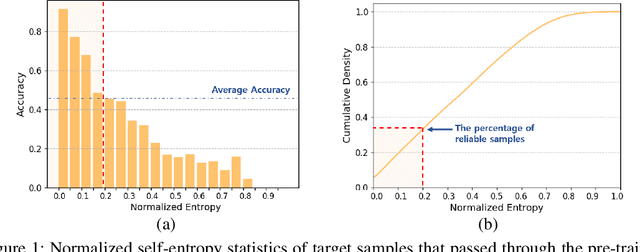
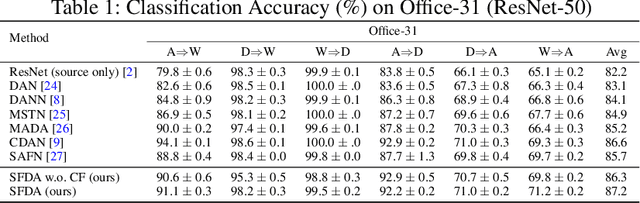


Domain adaptation assumes that samples from source and target domains are freely accessible during a training phase. However, such an assumption is rarely plausible in real cases and possibly causes data-privacy issues, especially when the label of the source domain can be a sensitive attribute as an identifier. To avoid accessing source data which may contain sensitive information, we introduce source data-free domain adaptation (SFDA). Our key idea is to leverage a pre-trained model from the source domain and progressively update the target model in a self-learning manner. We observe that target samples with lower self-entropy measured by the pre-trained source model are more likely to be classified correctly. From this, we select the reliable samples with the self-entropy criterion and define these as class prototypes. We then assign pseudo labels for every target sample based on the similarity score with class prototypes. Further, to reduce the uncertainty from the pseudo labeling process, we propose set-to-set distance-based filtering which does not require any tunable hyperparameters. Finally, we train the target model with the filtered pseudo labels with regularization from the pre-trained source model. Surprisingly, without direct usage of labeled source samples, our SFDA outperforms conventional domain adaptation methods on benchmark datasets. Our code is publicly available at https://github.com/youngryan1993/SFDA-Domain-Adaptation-without-Source-Data.
Restore from Restored: Video Restoration with Pseudo Clean Video
Mar 09, 2020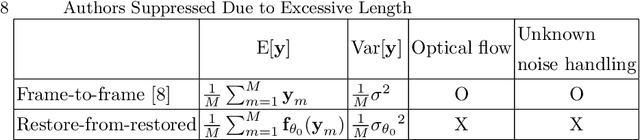
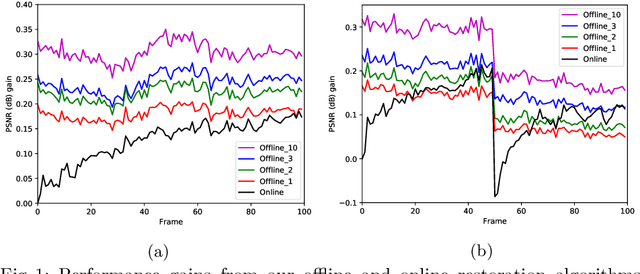

In this paper, we propose a self-supervised video denoising method called "restore-from-restored" that fine-tunes a baseline network by using a pseudo clean video at the test phase. The pseudo clean video can be obtained by applying an input noisy video to the pre-trained baseline network. By adopting a fully convolutional network (FCN) as the baseline, we can restore videos without accurate optical flow and registration due to its translation-invariant property unlike many conventional video restoration methods. Moreover, the proposed method can take advantage of the existence of many similar patches across consecutive frames (i.e., patch-recurrence), which can boost performance of the baseline network by a large margin. We analyze the restoration performance of the FCN fine-tuned with the proposed self-supervision-based training algorithm, and demonstrate that FCN can utilize recurring patches without the need for registration among adjacent frames. The proposed method can be applied to any FCN-based denoising models. In our experiments, we apply the proposed method to the state-of-the-art denoisers, and our results indicate a considerable improvementin task performance.
Restore from Restored: Single Image Denoising with Pseudo Clean Image
Mar 09, 2020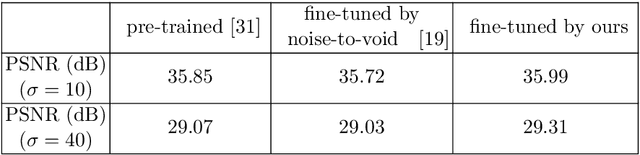

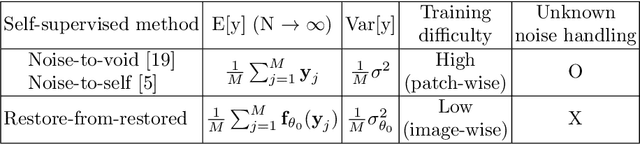
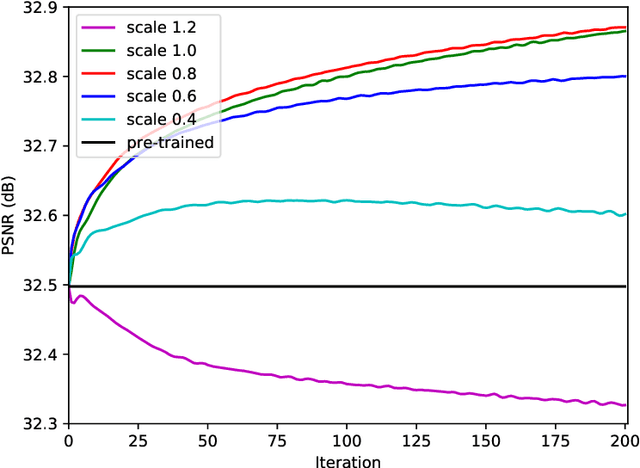
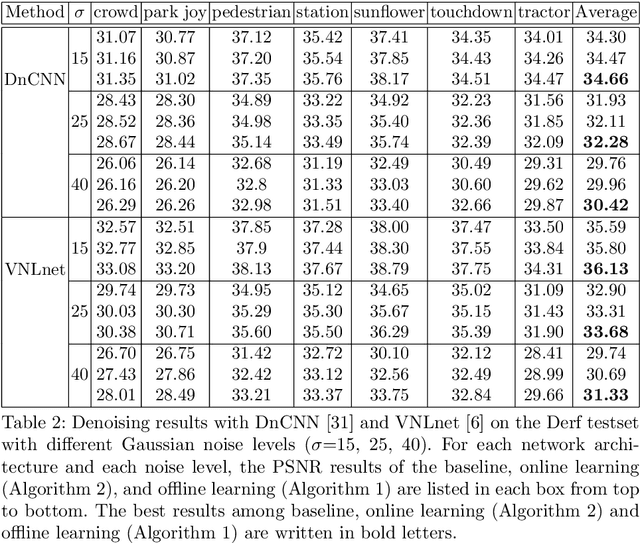
Under certain statistical assumptions of noise (e.g., zero-mean noise), recent self-supervised approaches for denoising have been introduced to learn network parameters without ground-truth clean images, and these methods can restore an image by exploiting information available from the given input (i.e., internal statistics) at test time. However, self-supervised methods are not yet properly combined with conventional supervised denoising methods which train the denoising networks with a large number of external training images. Thus, we propose a new denoising approach that can greatly outperform the state-of-the-art supervised denoising methods by adapting (fine-tuning) their network parameters to the given specific input through self-supervision without changing the fully original network architectures. We demonstrate that the proposed method can be easily employed with state-of-the-art denoising networks without additional parameters, and achieve state-of-the-art performance on numerous denoising benchmark datasets.