 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOne Click per Cell Type Suffices: Training-free Group Interaction for Cell Instance Segmentation
May 28, 2026Cell instance segmentation models trained on cell-specific datasets suffer severe performance drops on out-of-distribution cell types, while interactive foundation models overcome this through per-instance prompting at a cost that is prohibitively expensive for histopathology images containing hundreds to thousands of densely packed instances. We introduce Group Prompting, a new paradigm that shifts interactive segmentation from per-instance $O(N)$ to per-type $O(T)$, where a single click per cell type suffices to segment all instances of that type. Our key observation is that the frozen image encoder of the Segment Anything Model (SAM) already clusters same-type cells in its feature space before any prompt is given. Exploiting this property, we propose Chain-of-Prompts (CoP), a training-free framework that recursively expands a single user click by (1) identifying reliable same-type locations through non-parametric gating of multi-scale encoder features, and (2) selecting the most spatially distant reliable point as the next prompt to maximize coverage. On three cell-type-annotated benchmarks, CoP with one click per type retains over 90% of per-instance performance and surpasses fully-supervised methods without any additional training. On four morphologically homogeneous benchmarks, a single click retains over 99%. Project Page: https://shjo-april.github.io/Chain-of-Prompts/
EraseLoRA: MLLM-Driven Foreground Exclusion and Background Subtype Aggregation for Dataset-Free Object Removal
Dec 25, 2025



Object removal differs from common inpainting, since it must prevent the masked target from reappearing and reconstruct the occluded background with structural and contextual fidelity, rather than merely filling a hole plausibly. Recent dataset-free approaches that redirect self-attention inside the mask fail in two ways: non-target foregrounds are often misinterpreted as background, which regenerates unwanted objects, and direct attention manipulation disrupts fine details and hinders coherent integration of background cues. We propose EraseLoRA, a novel dataset-free framework that replaces attention surgery with background-aware reasoning and test-time adaptation. First, Background-aware Foreground Exclusion (BFE), uses a multimodal large-language models to separate target foreground, non-target foregrounds, and clean background from a single image-mask pair without paired supervision, producing reliable background cues while excluding distractors. Second, Background-aware Reconstruction with Subtype Aggregation (BRSA), performs test-time optimization that treats inferred background subtypes as complementary pieces and enforces their consistent integration through reconstruction and alignment objectives, preserving local detail and global structure without explicit attention intervention. We validate EraseLoRA as a plug-in to pretrained diffusion models and across benchmarks for object removal, demonstrating consistent improvements over dataset-free baselines and competitive results against dataset-driven methods. The code will be made available upon publication.
On the Collapse of Generative Paths: A Criterion and Correction for Diffusion Steering
Dec 11, 2025Inference-time steering enables pretrained diffusion/flow models to be adapted to new tasks without retraining. A widely used approach is the ratio-of-densities method, which defines a time-indexed target path by reweighting probability-density trajectories from multiple models with positive, or in some cases, negative exponents. This construction, however, harbors a critical and previously unformalized failure mode: Marginal Path Collapse, where intermediate densities become non-normalizable even though endpoints remain valid. Collapse arises systematically when composing heterogeneous models trained on different noise schedules or datasets, including a common setting in molecular design where de-novo, conformer, and pocket-conditioned models must be combined for tasks such as flexible-pose scaffold decoration. We provide a novel and complete solution for the problem. First, we derive a simple path existence criterion that predicts exactly when collapse occurs from noise schedules and exponents alone. Second, we introduce Adaptive path Correction with Exponents (ACE), which extends Feynman-Kac steering to time-varying exponents and guarantees a valid probability path. On a synthetic 2D benchmark and on flexible-pose scaffold decoration, ACE eliminates collapse and enables high-guidance compositional generation, improving distributional and docking metrics over constant-exponent baselines and even specialized task-specific scaffold decoration models. Our work turns ratio-of-densities steering with heterogeneous experts from an unstable heuristic into a reliable tool for controllable generation.
ISAC: Training-Free Instance-to-Semantic Attention Control for Improving Multi-Instance Generation
May 27, 2025Text-to-image diffusion models excel at generating single-instance scenes but struggle with multi-instance scenarios, often merging or omitting objects. Unlike previous training-free approaches that rely solely on semantic-level guidance without addressing instance individuation, our training-free method, Instance-to-Semantic Attention Control (ISAC), explicitly resolves incomplete instance formation and semantic entanglement through an instance-first modeling approach. This enables ISAC to effectively leverage a hierarchical, tree-structured prompt mechanism, disentangling multiple object instances and individually aligning them with their corresponding semantic labels. Without employing any external models, ISAC achieves up to 52% average multi-class accuracy and 83% average multi-instance accuracy by effectively forming disentangled instances. The code will be made available upon publication.
Early Timestep Zero-Shot Candidate Selection for Instruction-Guided Image Editing
Apr 18, 2025Despite recent advances in diffusion models, achieving reliable image generation and editing remains challenging due to the inherent diversity induced by stochastic noise in the sampling process. Instruction-guided image editing with diffusion models offers user-friendly capabilities, yet editing failures, such as background distortion, frequently occur. Users often resort to trial and error, adjusting seeds or prompts to achieve satisfactory results, which is inefficient. While seed selection methods exist for Text-to-Image (T2I) generation, they depend on external verifiers, limiting applicability, and evaluating multiple seeds increases computational complexity. To address this, we first establish a multiple-seed-based image editing baseline using background consistency scores, achieving Best-of-N performance without supervision. Building on this, we introduce ELECT (Early-timestep Latent Evaluation for Candidate Selection), a zero-shot framework that selects reliable seeds by estimating background mismatches at early diffusion timesteps, identifying the seed that retains the background while modifying only the foreground. ELECT ranks seed candidates by a background inconsistency score, filtering unsuitable samples early based on background consistency while preserving editability. Beyond standalone seed selection, ELECT integrates into instruction-guided editing pipelines and extends to Multimodal Large-Language Models (MLLMs) for joint seed and prompt selection, further improving results when seed selection alone is insufficient. Experiments show that ELECT reduces computational costs (by 41 percent on average and up to 61 percent) while improving background consistency and instruction adherence, achieving around 40 percent success rates in previously failed cases - without any external supervision or training.
COIN: Confidence Score-Guided Distillation for Annotation-Free Cell Segmentation
Mar 17, 2025



Cell instance segmentation (CIS) is crucial for identifying individual cell morphologies in histopathological images, providing valuable insights for biological and medical research. While unsupervised CIS (UCIS) models aim to reduce the heavy reliance on labor-intensive image annotations, they fail to accurately capture cell boundaries, causing missed detections and poor performance. Recognizing the absence of error-free instances as a key limitation, we present COIN (COnfidence score-guided INstance distillation), a novel annotation-free framework with three key steps: (1) Increasing the sensitivity for the presence of error-free instances via unsupervised semantic segmentation with optimal transport, leveraging its ability to discriminate spatially minor instances, (2) Instance-level confidence scoring to measure the consistency between model prediction and refined mask and identify highly confident instances, offering an alternative to ground truth annotations, and (3) Progressive expansion of confidence with recursive self-distillation. Extensive experiments across six datasets show COIN outperforming existing UCIS methods, even surpassing semi- and weakly-supervised approaches across all metrics on the MoNuSeg and TNBC datasets. The code is available at https://github.com/shjo-april/COIN.
DiffEGG: Diffusion-Driven Edge Generation as a Pixel-Annotation-Free Alternative for Instance Annotation
Mar 11, 2025



Achieving precise panoptic segmentation relies on pixel-wise instance annotations, but obtaining such datasets is costly. Unsupervised instance segmentation (UIS) eliminates annotation requirements but struggles with adjacent instance merging and single-instance fragmentation, largely due to the limitations of DINO-based backbones which lack strong instance separation cues. Weakly-supervised panoptic segmentation (WPS) reduces annotation costs using sparse labels (e.g., points, boxes), yet these annotations remain expensive and introduce human bias and boundary errors. To address these challenges, we propose DiffEGG (Diffusion-Driven EdGe Generation), a fully annotation-free method that extracts instance-aware features from pretrained diffusion models to generate precise instance edge maps. Unlike DINO-based UIS methods, diffusion models inherently capture fine-grained, instance-aware features, enabling more precise boundary delineation. For WPS, DiffEGG eliminates annotation costs and human bias by operating without any form of manual supervision, addressing the key limitations of prior best methods. Additionally, we introduce RIP, a post-processing technique that fuses DiffEGG's edge maps with segmentation masks in a task-agnostic manner. RIP allows DiffEGG to be seamlessly integrated into various segmentation frameworks. When applied to UIS, DiffEGG and RIP achieve an average $+4.4\text{ AP}$ improvement over prior best UIS methods. When combined with weakly-supervised semantic segmentation (WSS), DiffEGG enables WPS without instance annotations, outperforming prior best point-supervised WPS methods by $+1.7\text{ PQ}$. These results demonstrate that DiffEGG's edge maps serve as a cost-effective, annotation-free alternative to instance annotations, significantly improving segmentation without human intervention. Code is available at https://github.com/shjo-april/DiffEGG.
DHR: Dual Features-Driven Hierarchical Rebalancing in Inter- and Intra-Class Regions for Weakly-Supervised Semantic Segmentation
Mar 30, 2024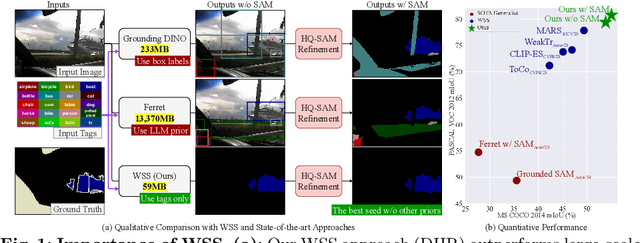


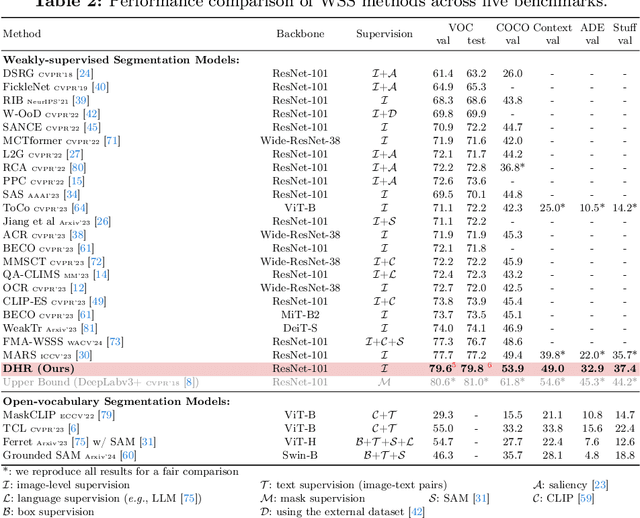
Weakly-supervised semantic segmentation (WSS) ensures high-quality segmentation with limited data and excels when employed as input seed masks for large-scale vision models such as Segment Anything. However, WSS faces challenges related to minor classes since those are overlooked in images with adjacent multiple classes, a limitation originating from the overfitting of traditional expansion methods like Random Walk. We first address this by employing unsupervised and weakly-supervised feature maps instead of conventional methodologies, allowing for hierarchical mask enhancement. This method distinctly categorizes higher-level classes and subsequently separates their associated lower-level classes, ensuring all classes are correctly restored in the mask without losing minor ones. Our approach, validated through extensive experimentation, significantly improves WSS across five benchmarks (VOC: 79.8\%, COCO: 53.9\%, Context: 49.0\%, ADE: 32.9\%, Stuff: 37.4\%), reducing the gap with fully supervised methods by over 84\% on the VOC validation set. Code is available at https://github.com/shjo-april/DHR.
TTD: Text-Tag Self-Distillation Enhancing Image-Text Alignment in CLIP to Alleviate Single Tag Bias
Mar 30, 2024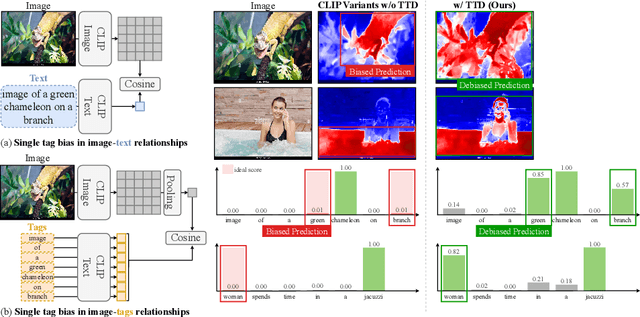
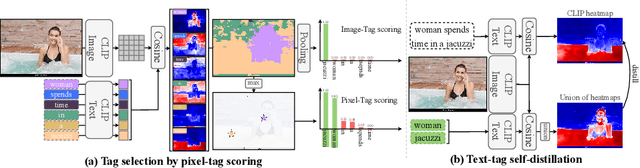

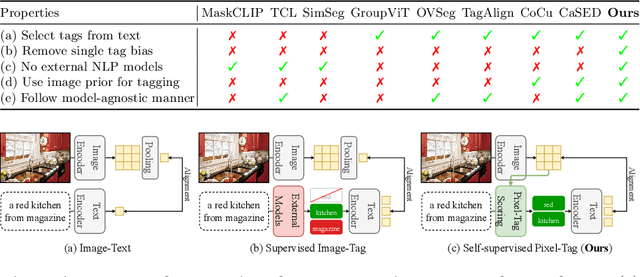
We identify a critical bias in contemporary CLIP-based models, which we denote as \textit{single tag bias}. This bias manifests as a disproportionate focus on a singular tag (word) while neglecting other pertinent tags, stemming from CLIP's text embeddings that prioritize one specific tag in image-text relationships. When deconstructing text into individual tags, only one tag tends to have high relevancy with CLIP's image embedding, leading to an imbalanced tag relevancy. This results in an uneven alignment among multiple tags present in the text. To tackle this challenge, we introduce a novel two-step fine-tuning approach. First, our method leverages the similarity between tags and their nearest pixels for scoring, enabling the extraction of image-relevant tags from the text. Second, we present a self-distillation strategy aimed at aligning the combined masks from extracted tags with the text-derived mask. This approach mitigates the single tag bias, thereby significantly improving the alignment of CLIP's model without necessitating additional data or supervision. Our technique demonstrates model-agnostic improvements in multi-tag classification and segmentation tasks, surpassing competing methods that rely on external resources. Code is available at https://github.com/shjo-april/TTD.
MARS: Model-agnostic Biased Object Removal without Additional Supervision for Weakly-Supervised Semantic Segmentation
Apr 19, 2023Weakly-supervised semantic segmentation aims to reduce labeling costs by training semantic segmentation models using weak supervision, such as image-level class labels. However, most approaches struggle to produce accurate localization maps and suffer from false predictions in class-related backgrounds (i.e., biased objects), such as detecting a railroad with the train class. Recent methods that remove biased objects require additional supervision for manually identifying biased objects for each problematic class and collecting their datasets by reviewing predictions, limiting their applicability to the real-world dataset with multiple labels and complex relationships for biasing. Following the first observation that biased features can be separated and eliminated by matching biased objects with backgrounds in the same dataset, we propose a fully-automatic/model-agnostic biased removal framework called MARS (Model-Agnostic biased object Removal without additional Supervision), which utilizes semantically consistent features of an unsupervised technique to eliminate biased objects in pseudo labels. Surprisingly, we show that MARS achieves new state-of-the-art results on two popular benchmarks, PASCAL VOC 2012 (val: 77.7%, test: 77.2%) and MS COCO 2014 (val: 49.4%), by consistently improving the performance of various WSSS models by at least 30% without additional supervision.