 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLINT: Modeling Scene-Scale Transparency via Gaussian Radiance Transport
Mar 27, 2026While 3D Gaussian splatting has emerged as a powerful paradigm, it fundamentally fails to model transparency such as glass panels. The core challenge lies in decoupling the intertwined radiance contributions from transparent interfaces and the transmitted geometry observed through the glass. We present GLINT, a framework that models scene-scale transparency through explicit decomposed Gaussian representation. GLINT reconstructs the primary interface and models reflected and transmitted radiance separately, enabling consistent radiance transport. During optimization, GLINT bootstraps transparency localization from geometry-separation cues induced by the decomposition, together with geometry and material priors from a pre-trained video relighting model. Extensive experiments demonstrate consistent improvements over prior methods for reconstructing complex transparent scenes.
Discounted Beta--Bernoulli Reward Estimation for Sample-Efficient Reinforcement Learning with Verifiable Rewards
Mar 19, 2026Reinforcement learning with verifiable rewards (RLVR) has emerged as an effective post-training paradigm for improving the reasoning capabilities of large language models. However, existing group-based RLVR methods often suffer from severe sample inefficiency. This inefficiency stems from reliance on point estimation of rewards from a small number of rollouts, leading to high estimation variance, variance collapse, and ineffective utilization of generated responses. In this work, we reformulate RLVR from a statistical estimation perspective by modeling rewards as samples drawn from a policy-induced distribution and casting advantage computation as the problem of estimating the reward distribution from finite data. Building on this view, we propose Discounted Beta--Bernoulli (DBB) reward estimation, which leverages historical reward statistics for the non-stationary distribution. Although biased, the resulting estimator exhibits reduced and stable variance, theoretically avoids estimated variance collapse, and achieves lower mean squared error than standard point estimation. Extensive experiments across six in-distribution and three out-of-distribution reasoning benchmarks demonstrate that GRPO with DBB consistently outperforms naive GRPO, achieving average Acc@8 improvements of 3.22/2.42 points in-distribution and 12.49/6.92 points out-of-distribution on the 1.7B and 8B models, respectively, without additional computational cost or memory usage.
Augmentation-Driven Metric for Balancing Preservation and Modification in Text-Guided Image Editing
Oct 15, 2024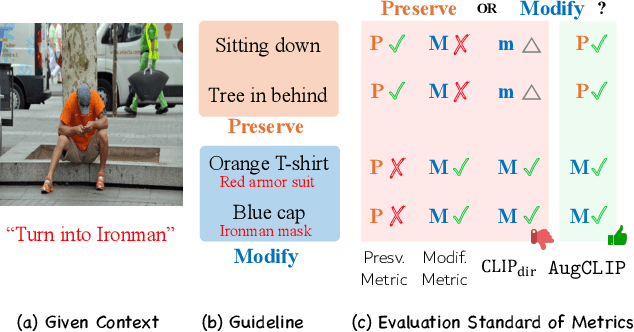

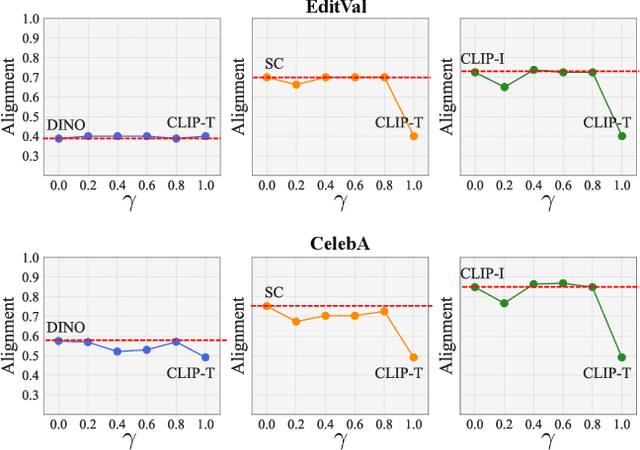
The development of vision-language and generative models has significantly advanced text-guided image editing, which seeks \textit{preservation} of core elements in the source image while implementing \textit{modifications} based on the target text. However, in the absence of evaluation metrics specifically tailored for text-guided image editing, existing metrics are limited in balancing the consideration of preservation and modification. Especially, our analysis reveals that CLIPScore, the most commonly used metric, tends to favor modification and ignore core attributes to be preserved, resulting in inaccurate evaluations. To address this problem, we propose \texttt{AugCLIP}, \black{which balances preservation and modification by estimating the representation of an ideal edited image that aligns with the target text with minimum alteration on the source image. We augment detailed textual descriptions on the source image and the target text using a multi-modal large language model, to model a hyperplane that separates CLIP space into source or target. The representation of the ideal edited image is an orthogonal projection of the source image into the hyperplane, which encapsulates the relative importance of each attribute considering the interdependent relationships.} Our extensive experiments on five benchmark datasets, encompassing a diverse range of editing scenarios, demonstrate that \texttt{AugCLIP} aligns remarkably well with human evaluation standards compared to existing metrics. The code for evaluation will be open-sourced to contribute to the community.
Mode-GS: Monocular Depth Guided Anchored 3D Gaussian Splatting for Robust Ground-View Scene Rendering
Oct 06, 2024We present a novel-view rendering algorithm, Mode-GS, for ground-robot trajectory datasets. Our approach is based on using anchored Gaussian splats, which are designed to overcome the limitations of existing 3D Gaussian splatting algorithms. Prior neural rendering methods suffer from severe splat drift due to scene complexity and insufficient multi-view observation, and can fail to fix splats on the true geometry in ground-robot datasets. Our method integrates pixel-aligned anchors from monocular depths and generates Gaussian splats around these anchors using residual-form Gaussian decoders. To address the inherent scale ambiguity of monocular depth, we parameterize anchors with per-view depth-scales and employ scale-consistent depth loss for online scale calibration. Our method results in improved rendering performance, based on PSNR, SSIM, and LPIPS metrics, in ground scenes with free trajectory patterns, and achieves state-of-the-art rendering performance on the R3LIVE odometry dataset and the Tanks and Temples dataset.
TTD: Text-Tag Self-Distillation Enhancing Image-Text Alignment in CLIP to Alleviate Single Tag Bias
Mar 30, 2024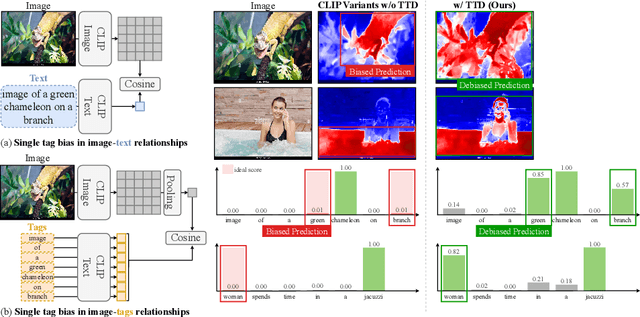
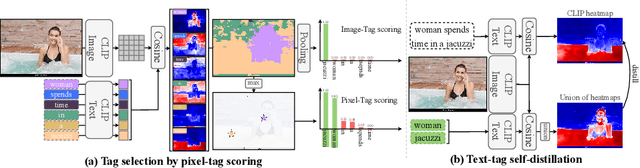

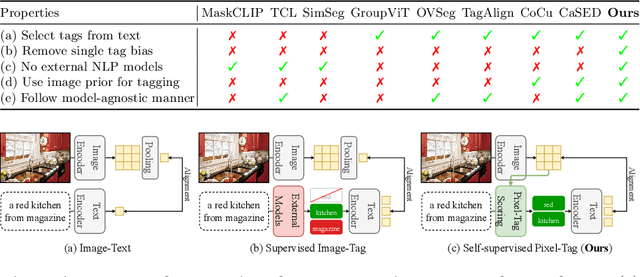
We identify a critical bias in contemporary CLIP-based models, which we denote as \textit{single tag bias}. This bias manifests as a disproportionate focus on a singular tag (word) while neglecting other pertinent tags, stemming from CLIP's text embeddings that prioritize one specific tag in image-text relationships. When deconstructing text into individual tags, only one tag tends to have high relevancy with CLIP's image embedding, leading to an imbalanced tag relevancy. This results in an uneven alignment among multiple tags present in the text. To tackle this challenge, we introduce a novel two-step fine-tuning approach. First, our method leverages the similarity between tags and their nearest pixels for scoring, enabling the extraction of image-relevant tags from the text. Second, we present a self-distillation strategy aimed at aligning the combined masks from extracted tags with the text-derived mask. This approach mitigates the single tag bias, thereby significantly improving the alignment of CLIP's model without necessitating additional data or supervision. Our technique demonstrates model-agnostic improvements in multi-tag classification and segmentation tasks, surpassing competing methods that rely on external resources. Code is available at https://github.com/shjo-april/TTD.
A Single Correspondence Is Enough: Robust Global Registration to Avoid Degeneracy in Urban Environments
Mar 13, 2022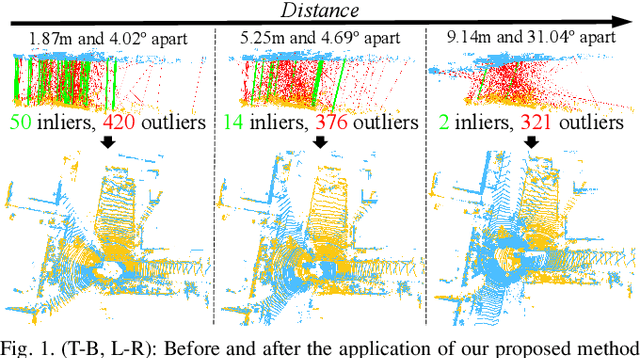
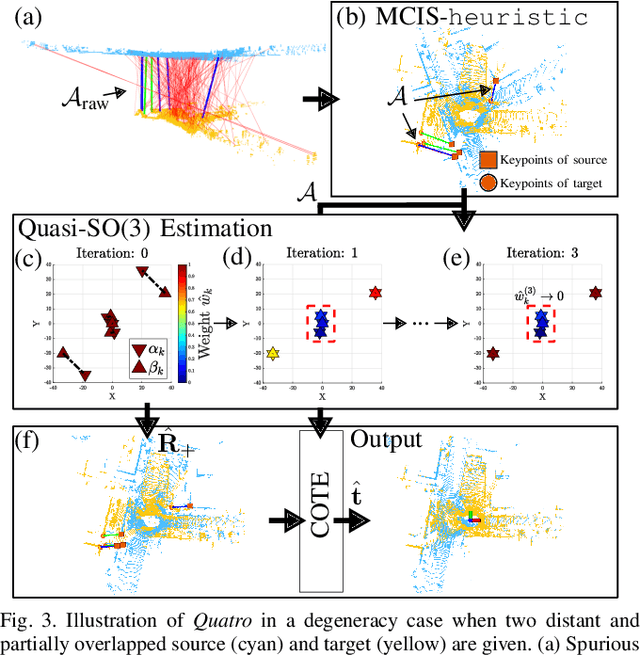
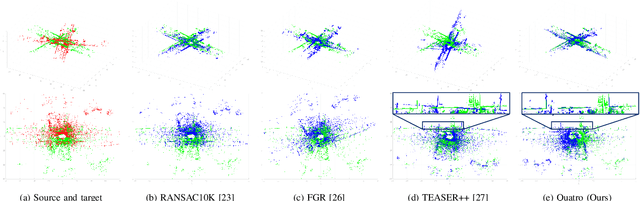
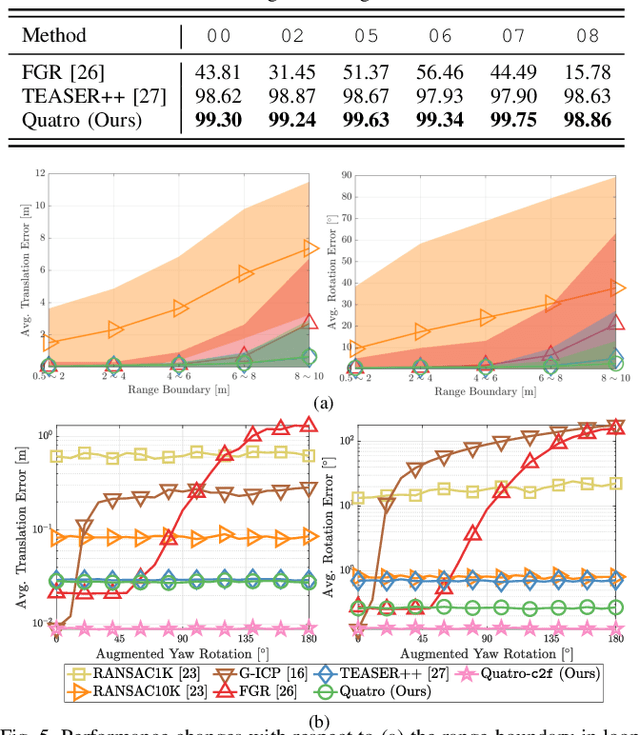
Global registration using 3D point clouds is a crucial technology for mobile platforms to achieve localization or manage loop-closing situations. In recent years, numerous researchers have proposed global registration methods to address a large number of outlier correspondences. Unfortunately, the degeneracy problem, which represents the phenomenon in which the number of estimated inliers becomes lower than three, is still potentially inevitable. To tackle the problem, a degeneracy-robust decoupling-based global registration method is proposed, called Quatro. In particular, our method employs quasi-SO(3) estimation by leveraging the Atlanta world assumption in urban environments to avoid degeneracy in rotation estimation. Thus, the minimum degree of freedom (DoF) of our method is reduced from three to one. As verified in indoor and outdoor 3D LiDAR datasets, our proposed method yields robust global registration performance compared with other global registration methods, even for distant point cloud pairs. Furthermore, the experimental results confirm the applicability of our method as a coarse alignment. Our code is available: https://github.com/url-kaist/quatro.
Large-scale Localization Datasets in Crowded Indoor Spaces
May 19, 2021
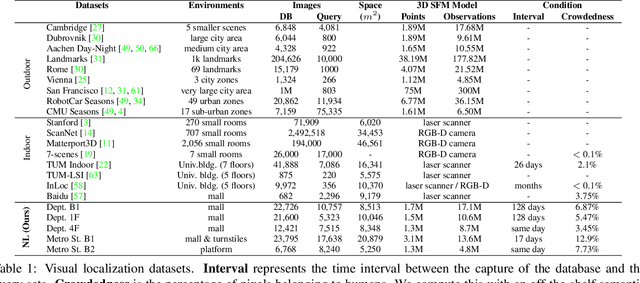


Estimating the precise location of a camera using visual localization enables interesting applications such as augmented reality or robot navigation. This is particularly useful in indoor environments where other localization technologies, such as GNSS, fail. Indoor spaces impose interesting challenges on visual localization algorithms: occlusions due to people, textureless surfaces, large viewpoint changes, low light, repetitive textures, etc. Existing indoor datasets are either comparably small or do only cover a subset of the mentioned challenges. In this paper, we introduce 5 new indoor datasets for visual localization in challenging real-world environments. They were captured in a large shopping mall and a large metro station in Seoul, South Korea, using a dedicated mapping platform consisting of 10 cameras and 2 laser scanners. In order to obtain accurate ground truth camera poses, we developed a robust LiDAR SLAM which provides initial poses that are then refined using a novel structure-from-motion based optimization. We present a benchmark of modern visual localization algorithms on these challenging datasets showing superior performance of structure-based methods using robust image features. The datasets are available at: https://naverlabs.com/datasets