 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoPlane: Plane-Aware Panoramic Completion for Sparse-View Indoor 3D Gaussian Splatting
May 13, 2026We present PanoPlane, an approach for high-fidelity sparse-view indoor novel view synthesis that reconstructs closed room geometry via panoramic scene completion. Unlike perspective-based methods that generate training views from limited fields of view, PanoPlane leverages $360^{\circ}$ panoramic completion to condition the generative process on the full spatial layout. We propose Layout Anchored Attention Steering, a training-free mechanism that steers attention within the diffusion model's internal representation toward scene's detected planar surfaces at inference time. By directing each unobserved region's attention toward geometrically consistent observed content, our method replaces unconstrained hallucination with grounded surface extrapolation. The resulting panoramic completions provide supervision for 3D Gaussian Splatting, enabling accurate novel-view synthesis across unobserved regions from as few as three input views. Experiments on Replica, ScanNet++, and Matterport3D demonstrate state-of-the-art novel view synthesis quality across 3, 6, and 9 input views, achieving up to $+17.8\%$ improvement in PSNR over the current state-of-the-art baseline without any training or fine-tuning of the diffusion model.
Wid3R: Wide Field-of-View 3D Reconstruction via Camera Model Conditioning
Feb 05, 2026We present Wid3R, a feed-forward neural network for visual geometry reconstruction that supports wide field-of-view camera models. Prior methods typically assume that input images are rectified or captured with pinhole cameras, since both their architectures and training datasets are tailored to perspective images only. These assumptions limit their applicability in real-world scenarios that use fisheye or panoramic cameras and often require careful calibration and undistortion. In contrast, Wid3R is a generalizable multi-view 3D estimation method that can model wide field-of-view camera types. Our approach leverages a ray representation with spherical harmonics and a novel camera model token within the network, enabling distortion-aware 3D reconstruction. Furthermore, Wid3R is the first multi-view foundation model to support feed-forward 3D reconstruction directly from 360 imagery. It demonstrates strong zero-shot robustness and consistently outperforms prior methods, achieving improvements of up to +77.33 on Stanford2D3D.
MoRe: Monocular Geometry Refinement via Graph Optimization for Cross-View Consistency
Oct 08, 2025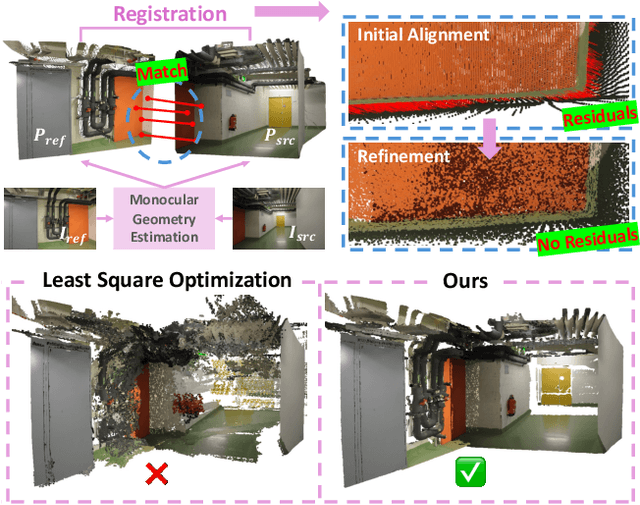
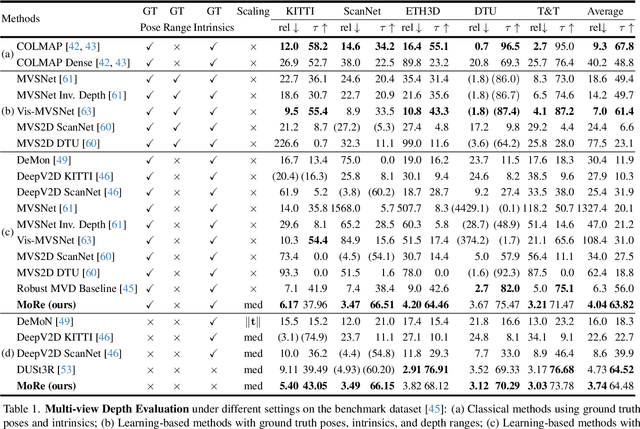


Monocular 3D foundation models offer an extensible solution for perception tasks, making them attractive for broader 3D vision applications. In this paper, we propose MoRe, a training-free Monocular Geometry Refinement method designed to improve cross-view consistency and achieve scale alignment. To induce inter-frame relationships, our method employs feature matching between frames to establish correspondences. Rather than applying simple least squares optimization on these matched points, we formulate a graph-based optimization framework that performs local planar approximation using the estimated 3D points and surface normals estimated by monocular foundation models. This formulation addresses the scale ambiguity inherent in monocular geometric priors while preserving the underlying 3D structure. We further demonstrate that MoRe not only enhances 3D reconstruction but also improves novel view synthesis, particularly in sparse view rendering scenarios.
UAV4D: Dynamic Neural Rendering of Human-Centric UAV Imagery using Gaussian Splatting
Jun 05, 2025Despite significant advancements in dynamic neural rendering, existing methods fail to address the unique challenges posed by UAV-captured scenarios, particularly those involving monocular camera setups, top-down perspective, and multiple small, moving humans, which are not adequately represented in existing datasets. In this work, we introduce UAV4D, a framework for enabling photorealistic rendering for dynamic real-world scenes captured by UAVs. Specifically, we address the challenge of reconstructing dynamic scenes with multiple moving pedestrians from monocular video data without the need for additional sensors. We use a combination of a 3D foundation model and a human mesh reconstruction model to reconstruct both the scene background and humans. We propose a novel approach to resolve the scene scale ambiguity and place both humans and the scene in world coordinates by identifying human-scene contact points. Additionally, we exploit the SMPL model and background mesh to initialize Gaussian splats, enabling holistic scene rendering. We evaluated our method on three complex UAV-captured datasets: VisDrone, Manipal-UAV, and Okutama-Action, each with distinct characteristics and 10~50 humans. Our results demonstrate the benefits of our approach over existing methods in novel view synthesis, achieving a 1.5 dB PSNR improvement and superior visual sharpness.
UAVTwin: Neural Digital Twins for UAVs using Gaussian Splatting
Apr 02, 2025



We present UAVTwin, a method for creating digital twins from real-world environments and facilitating data augmentation for training downstream models embedded in unmanned aerial vehicles (UAVs). Specifically, our approach focuses on synthesizing foreground components, such as various human instances in motion within complex scene backgrounds, from UAV perspectives. This is achieved by integrating 3D Gaussian Splatting (3DGS) for reconstructing backgrounds along with controllable synthetic human models that display diverse appearances and actions in multiple poses. To the best of our knowledge, UAVTwin is the first approach for UAV-based perception that is capable of generating high-fidelity digital twins based on 3DGS. The proposed work significantly enhances downstream models through data augmentation for real-world environments with multiple dynamic objects and significant appearance variations-both of which typically introduce artifacts in 3DGS-based modeling. To tackle these challenges, we propose a novel appearance modeling strategy and a mask refinement module to enhance the training of 3D Gaussian Splatting. We demonstrate the high quality of neural rendering by achieving a 1.23 dB improvement in PSNR compared to recent methods. Furthermore, we validate the effectiveness of data augmentation by showing a 2.5% to 13.7% improvement in mAP for the human detection task.
EDM: Equirectangular Projection-Oriented Dense Kernelized Feature Matching
Feb 28, 2025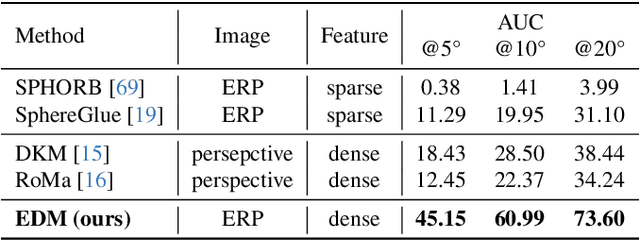
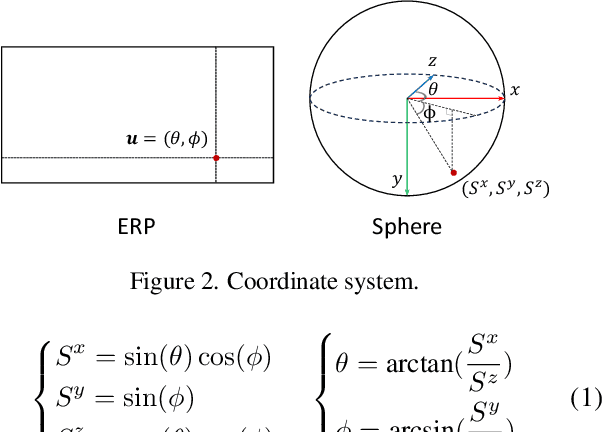
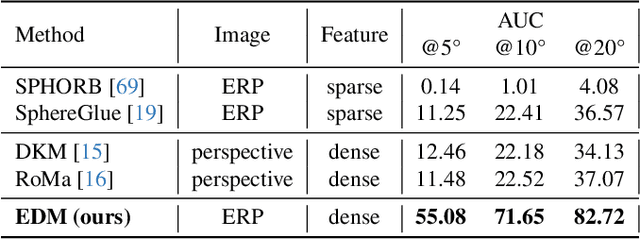

We introduce the first learning-based dense matching algorithm, termed Equirectangular Projection-Oriented Dense Kernelized Feature Matching (EDM), specifically designed for omnidirectional images. Equirectangular projection (ERP) images, with their large fields of view, are particularly suited for dense matching techniques that aim to establish comprehensive correspondences across images. However, ERP images are subject to significant distortions, which we address by leveraging the spherical camera model and geodesic flow refinement in the dense matching method. To further mitigate these distortions, we propose spherical positional embeddings based on 3D Cartesian coordinates of the feature grid. Additionally, our method incorporates bidirectional transformations between spherical and Cartesian coordinate systems during refinement, utilizing a unit sphere to improve matching performance. We demonstrate that our proposed method achieves notable performance enhancements, with improvements of +26.72 and +42.62 in AUC@5{\deg} on the Matterport3D and Stanford2D3D datasets.
IM360: Textured Mesh Reconstruction for Large-scale Indoor Mapping with 360$^\circ$ Cameras
Feb 19, 2025



We present a novel 3D reconstruction pipeline for 360$^\circ$ cameras for 3D mapping and rendering of indoor environments. Traditional Structure-from-Motion (SfM) methods may not work well in large-scale indoor scenes due to the prevalence of textureless and repetitive regions. To overcome these challenges, our approach (IM360) leverages the wide field of view of omnidirectional images and integrates the spherical camera model into every core component of the SfM pipeline. In order to develop a comprehensive 3D reconstruction solution, we integrate a neural implicit surface reconstruction technique to generate high-quality surfaces from sparse input data. Additionally, we utilize a mesh-based neural rendering approach to refine texture maps and accurately capture view-dependent properties by combining diffuse and specular components. We evaluate our pipeline on large-scale indoor scenes from the Matterport3D and Stanford2D3D datasets. In practice, IM360 demonstrate superior performance in terms of textured mesh reconstruction over SOTA. We observe accuracy improvements in terms of camera localization and registration as well as rendering high frequency details.
MeshGS: Adaptive Mesh-Aligned Gaussian Splatting for High-Quality Rendering
Oct 11, 2024Recently, 3D Gaussian splatting has gained attention for its capability to generate high-fidelity rendering results. At the same time, most applications such as games, animation, and AR/VR use mesh-based representations to represent and render 3D scenes. We propose a novel approach that integrates mesh representation with 3D Gaussian splats to perform high-quality rendering of reconstructed real-world scenes. In particular, we introduce a distance-based Gaussian splatting technique to align the Gaussian splats with the mesh surface and remove redundant Gaussian splats that do not contribute to the rendering. We consider the distance between each Gaussian splat and the mesh surface to distinguish between tightly-bound and loosely-bound Gaussian splats. The tightly-bound splats are flattened and aligned well with the mesh geometry. The loosely-bound Gaussian splats are used to account for the artifacts in reconstructed 3D meshes in terms of rendering. We present a training strategy of binding Gaussian splats to the mesh geometry, and take into account both types of splats. In this context, we introduce several regularization techniques aimed at precisely aligning tightly-bound Gaussian splats with the mesh surface during the training process. We validate the effectiveness of our method on large and unbounded scene from mip-NeRF 360 and Deep Blending datasets. Our method surpasses recent mesh-based neural rendering techniques by achieving a 2dB higher PSNR, and outperforms mesh-based Gaussian splatting methods by 1.3 dB PSNR, particularly on the outdoor mip-NeRF 360 dataset, demonstrating better rendering quality. We provide analyses for each type of Gaussian splat and achieve a reduction in the number of Gaussian splats by 30% compared to the original 3D Gaussian splatting.
Mode-GS: Monocular Depth Guided Anchored 3D Gaussian Splatting for Robust Ground-View Scene Rendering
Oct 06, 2024We present a novel-view rendering algorithm, Mode-GS, for ground-robot trajectory datasets. Our approach is based on using anchored Gaussian splats, which are designed to overcome the limitations of existing 3D Gaussian splatting algorithms. Prior neural rendering methods suffer from severe splat drift due to scene complexity and insufficient multi-view observation, and can fail to fix splats on the true geometry in ground-robot datasets. Our method integrates pixel-aligned anchors from monocular depths and generates Gaussian splats around these anchors using residual-form Gaussian decoders. To address the inherent scale ambiguity of monocular depth, we parameterize anchors with per-view depth-scales and employ scale-consistent depth loss for online scale calibration. Our method results in improved rendering performance, based on PSNR, SSIM, and LPIPS metrics, in ground scenes with free trajectory patterns, and achieves state-of-the-art rendering performance on the R3LIVE odometry dataset and the Tanks and Temples dataset.
TK-Planes: Tiered K-Planes with High Dimensional Feature Vectors for Dynamic UAV-based Scenes
May 04, 2024In this paper, we present a new approach to bridge the domain gap between synthetic and real-world data for un- manned aerial vehicle (UAV)-based perception. Our formu- lation is designed for dynamic scenes, consisting of moving objects or human actions, where the goal is to recognize the pose or actions. We propose an extension of K-Planes Neural Radiance Field (NeRF), wherein our algorithm stores a set of tiered feature vectors. The tiered feature vectors are generated to effectively model conceptual information about a scene as well as an image decoder that transforms output feature maps into RGB images. Our technique leverages the information amongst both static and dynamic objects within a scene and is able to capture salient scene attributes of high altitude videos. We evaluate its performance on challenging datasets, including Okutama Action and UG2, and observe considerable improvement in accuracy over state of the art aerial perception algorithms.