 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWid3R: Wide Field-of-View 3D Reconstruction via Camera Model Conditioning
Feb 05, 2026We present Wid3R, a feed-forward neural network for visual geometry reconstruction that supports wide field-of-view camera models. Prior methods typically assume that input images are rectified or captured with pinhole cameras, since both their architectures and training datasets are tailored to perspective images only. These assumptions limit their applicability in real-world scenarios that use fisheye or panoramic cameras and often require careful calibration and undistortion. In contrast, Wid3R is a generalizable multi-view 3D estimation method that can model wide field-of-view camera types. Our approach leverages a ray representation with spherical harmonics and a novel camera model token within the network, enabling distortion-aware 3D reconstruction. Furthermore, Wid3R is the first multi-view foundation model to support feed-forward 3D reconstruction directly from 360 imagery. It demonstrates strong zero-shot robustness and consistently outperforms prior methods, achieving improvements of up to +77.33 on Stanford2D3D.
EDM: Equirectangular Projection-Oriented Dense Kernelized Feature Matching
Feb 28, 2025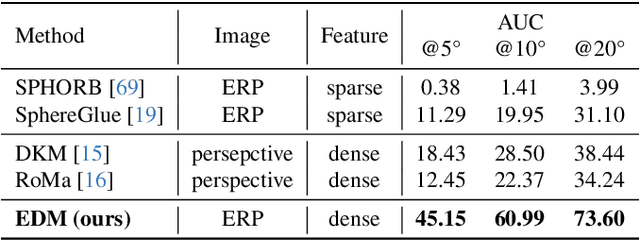
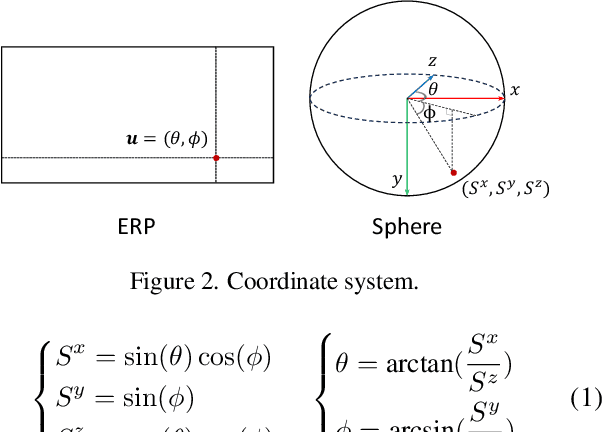
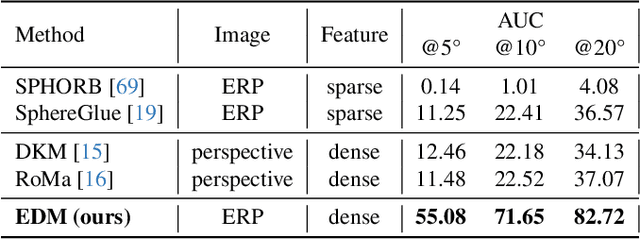

We introduce the first learning-based dense matching algorithm, termed Equirectangular Projection-Oriented Dense Kernelized Feature Matching (EDM), specifically designed for omnidirectional images. Equirectangular projection (ERP) images, with their large fields of view, are particularly suited for dense matching techniques that aim to establish comprehensive correspondences across images. However, ERP images are subject to significant distortions, which we address by leveraging the spherical camera model and geodesic flow refinement in the dense matching method. To further mitigate these distortions, we propose spherical positional embeddings based on 3D Cartesian coordinates of the feature grid. Additionally, our method incorporates bidirectional transformations between spherical and Cartesian coordinate systems during refinement, utilizing a unit sphere to improve matching performance. We demonstrate that our proposed method achieves notable performance enhancements, with improvements of +26.72 and +42.62 in AUC@5{\deg} on the Matterport3D and Stanford2D3D datasets.
Mode-GS: Monocular Depth Guided Anchored 3D Gaussian Splatting for Robust Ground-View Scene Rendering
Oct 06, 2024We present a novel-view rendering algorithm, Mode-GS, for ground-robot trajectory datasets. Our approach is based on using anchored Gaussian splats, which are designed to overcome the limitations of existing 3D Gaussian splatting algorithms. Prior neural rendering methods suffer from severe splat drift due to scene complexity and insufficient multi-view observation, and can fail to fix splats on the true geometry in ground-robot datasets. Our method integrates pixel-aligned anchors from monocular depths and generates Gaussian splats around these anchors using residual-form Gaussian decoders. To address the inherent scale ambiguity of monocular depth, we parameterize anchors with per-view depth-scales and employ scale-consistent depth loss for online scale calibration. Our method results in improved rendering performance, based on PSNR, SSIM, and LPIPS metrics, in ground scenes with free trajectory patterns, and achieves state-of-the-art rendering performance on the R3LIVE odometry dataset and the Tanks and Temples dataset.
A Single Correspondence Is Enough: Robust Global Registration to Avoid Degeneracy in Urban Environments
Mar 13, 2022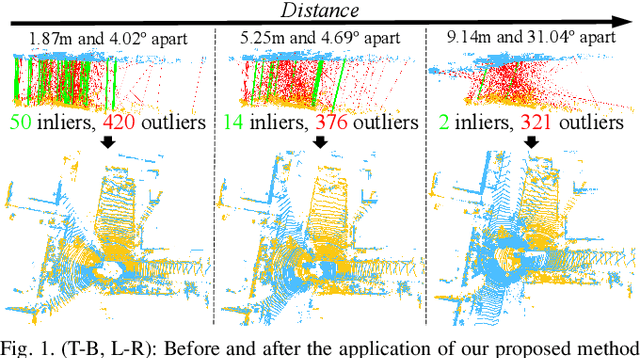
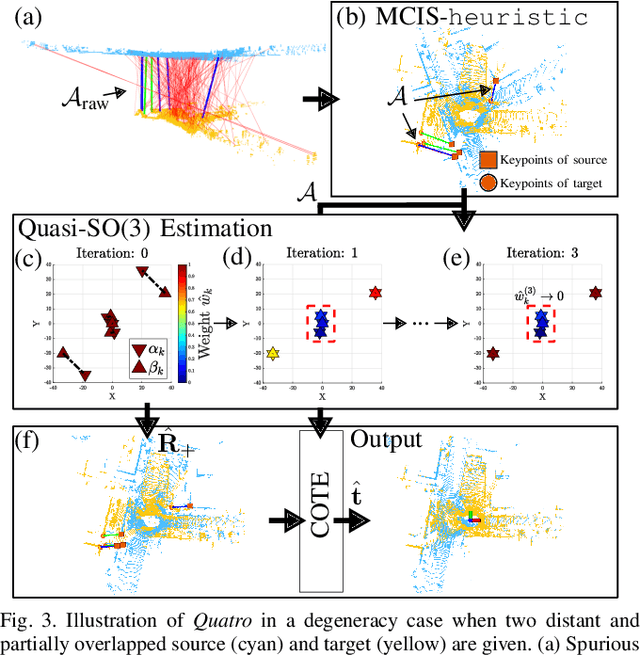
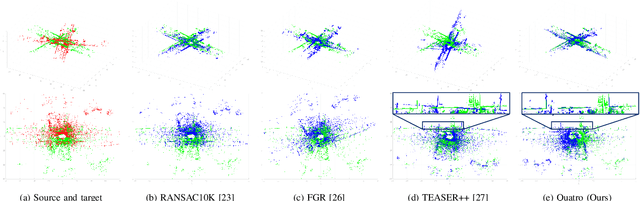
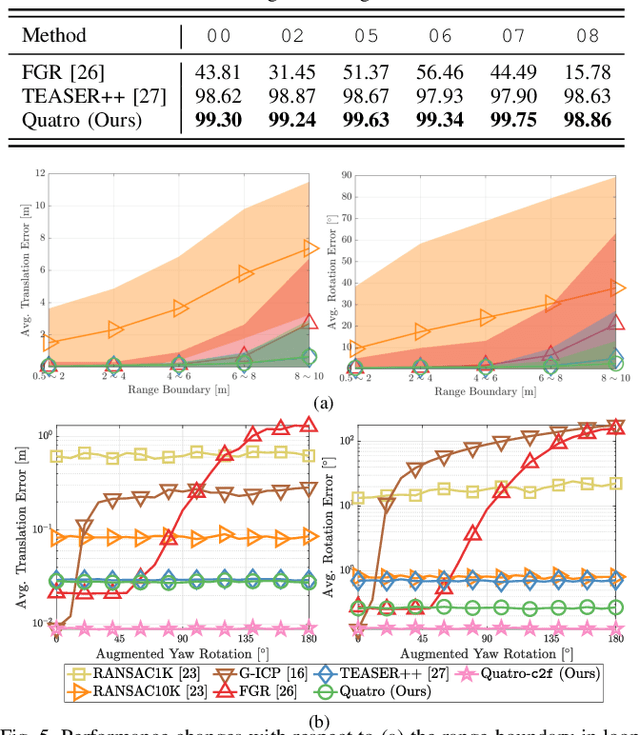
Global registration using 3D point clouds is a crucial technology for mobile platforms to achieve localization or manage loop-closing situations. In recent years, numerous researchers have proposed global registration methods to address a large number of outlier correspondences. Unfortunately, the degeneracy problem, which represents the phenomenon in which the number of estimated inliers becomes lower than three, is still potentially inevitable. To tackle the problem, a degeneracy-robust decoupling-based global registration method is proposed, called Quatro. In particular, our method employs quasi-SO(3) estimation by leveraging the Atlanta world assumption in urban environments to avoid degeneracy in rotation estimation. Thus, the minimum degree of freedom (DoF) of our method is reduced from three to one. As verified in indoor and outdoor 3D LiDAR datasets, our proposed method yields robust global registration performance compared with other global registration methods, even for distant point cloud pairs. Furthermore, the experimental results confirm the applicability of our method as a coarse alignment. Our code is available: https://github.com/url-kaist/quatro.
Large-scale Localization Datasets in Crowded Indoor Spaces
May 19, 2021
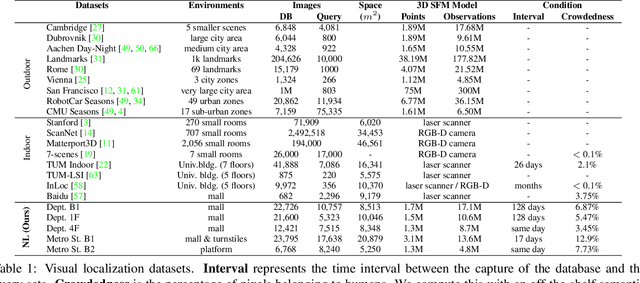


Estimating the precise location of a camera using visual localization enables interesting applications such as augmented reality or robot navigation. This is particularly useful in indoor environments where other localization technologies, such as GNSS, fail. Indoor spaces impose interesting challenges on visual localization algorithms: occlusions due to people, textureless surfaces, large viewpoint changes, low light, repetitive textures, etc. Existing indoor datasets are either comparably small or do only cover a subset of the mentioned challenges. In this paper, we introduce 5 new indoor datasets for visual localization in challenging real-world environments. They were captured in a large shopping mall and a large metro station in Seoul, South Korea, using a dedicated mapping platform consisting of 10 cameras and 2 laser scanners. In order to obtain accurate ground truth camera poses, we developed a robust LiDAR SLAM which provides initial poses that are then refined using a novel structure-from-motion based optimization. We present a benchmark of modern visual localization algorithms on these challenging datasets showing superior performance of structure-based methods using robust image features. The datasets are available at: https://naverlabs.com/datasets