 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Role of Image Retrieval for Visual Localization -- An exhaustive benchmark
May 31, 2022Visual localization, i.e., camera pose estimation in a known scene, is a core component of technologies such as autonomous driving and augmented reality. State-of-the-art localization approaches often rely on image retrieval techniques for one of two purposes: (1) provide an approximate pose estimate or (2) determine which parts of the scene are potentially visible in a given query image. It is common practice to use state-of-the-art image retrieval algorithms for both of them. These algorithms are often trained for the goal of retrieving the same landmark under a large range of viewpoint changes which often differs from the requirements of visual localization. In order to investigate the consequences for visual localization, this paper focuses on understanding the role of image retrieval for multiple visual localization paradigms. First, we introduce a novel benchmark setup and compare state-of-the-art retrieval representations on multiple datasets using localization performance as metric. Second, we investigate several definitions of "ground truth" for image retrieval. Using these definitions as upper bounds for the visual localization paradigms, we show that there is still sgnificant room for improvement. Third, using these tools and in-depth analysis, we show that retrieval performance on classical landmark retrieval or place recognition tasks correlates only for some but not all paradigms to localization performance. Finally, we analyze the effects of blur and dynamic scenes in the images. We conclude that there is a need for retrieval approaches specifically designed for localization paradigms. Our benchmark and evaluation protocols are available at https://github.com/naver/kapture-localization.
Large-scale Localization Datasets in Crowded Indoor Spaces
May 19, 2021
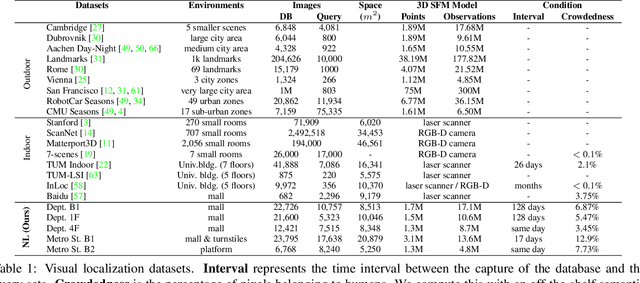


Estimating the precise location of a camera using visual localization enables interesting applications such as augmented reality or robot navigation. This is particularly useful in indoor environments where other localization technologies, such as GNSS, fail. Indoor spaces impose interesting challenges on visual localization algorithms: occlusions due to people, textureless surfaces, large viewpoint changes, low light, repetitive textures, etc. Existing indoor datasets are either comparably small or do only cover a subset of the mentioned challenges. In this paper, we introduce 5 new indoor datasets for visual localization in challenging real-world environments. They were captured in a large shopping mall and a large metro station in Seoul, South Korea, using a dedicated mapping platform consisting of 10 cameras and 2 laser scanners. In order to obtain accurate ground truth camera poses, we developed a robust LiDAR SLAM which provides initial poses that are then refined using a novel structure-from-motion based optimization. We present a benchmark of modern visual localization algorithms on these challenging datasets showing superior performance of structure-based methods using robust image features. The datasets are available at: https://naverlabs.com/datasets