 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan we make NeRF-based visual localization privacy-preserving?
Aug 26, 2025Visual localization (VL) is the task of estimating the camera pose in a known scene. VL methods, a.o., can be distinguished based on how they represent the scene, e.g., explicitly through a (sparse) point cloud or a collection of images or implicitly through the weights of a neural network. Recently, NeRF-based methods have become popular for VL. While NeRFs offer high-quality novel view synthesis, they inadvertently encode fine scene details, raising privacy concerns when deployed in cloud-based localization services as sensitive information could be recovered. In this paper, we tackle this challenge on two ends. We first propose a new protocol to assess privacy-preservation of NeRF-based representations. We show that NeRFs trained with photometric losses store fine-grained details in their geometry representations, making them vulnerable to privacy attacks, even if the head that predicts colors is removed. Second, we propose ppNeSF (Privacy-Preserving Neural Segmentation Field), a NeRF variant trained with segmentation supervision instead of RGB images. These segmentation labels are learned in a self-supervised manner, ensuring they are coarse enough to obscure identifiable scene details while remaining discriminativeness in 3D. The segmentation space of ppNeSF can be used for accurate visual localization, yielding state-of-the-art results.
Self-supervised Learning of Neural Implicit Feature Fields for Camera Pose Refinement
Jun 12, 2024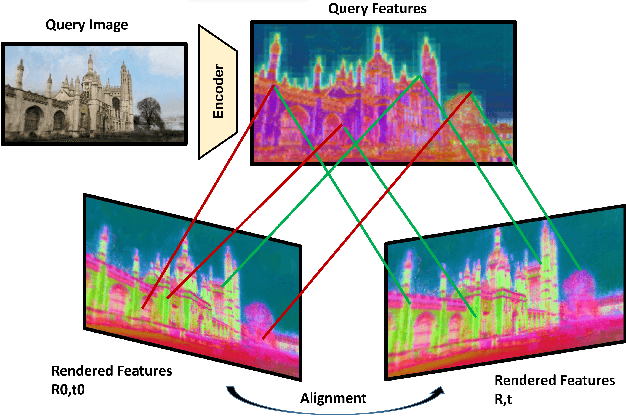
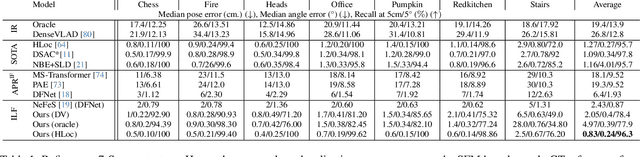
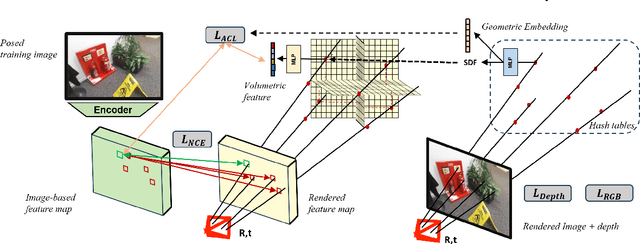
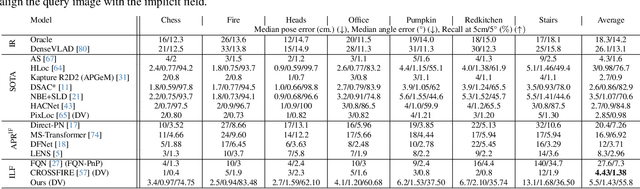
Visual localization techniques rely upon some underlying scene representation to localize against. These representations can be explicit such as 3D SFM map or implicit, such as a neural network that learns to encode the scene. The former requires sparse feature extractors and matchers to build the scene representation. The latter might lack geometric grounding not capturing the 3D structure of the scene well enough. This paper proposes to jointly learn the scene representation along with a 3D dense feature field and a 2D feature extractor whose outputs are embedded in the same metric space. Through a contrastive framework we align this volumetric field with the image-based extractor and regularize the latter with a ranking loss from learned surface information. We learn the underlying geometry of the scene with an implicit field through volumetric rendering and design our feature field to leverage intermediate geometric information encoded in the implicit field. The resulting features are discriminative and robust to viewpoint change while maintaining rich encoded information. Visual localization is then achieved by aligning the image-based features and the rendered volumetric features. We show the effectiveness of our approach on real-world scenes, demonstrating that our approach outperforms prior and concurrent work on leveraging implicit scene representations for localization.
4DHumanOutfit: a multi-subject 4D dataset of human motion sequences in varying outfits exhibiting large displacements
Jun 12, 2023
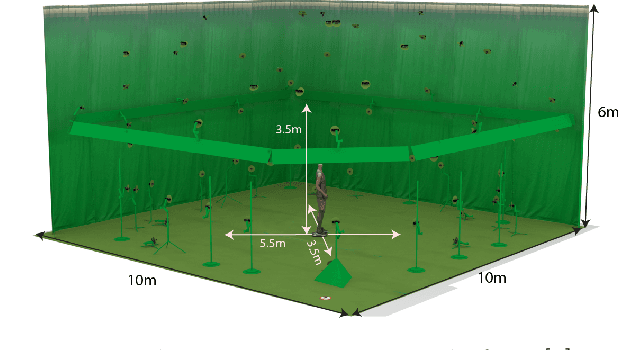

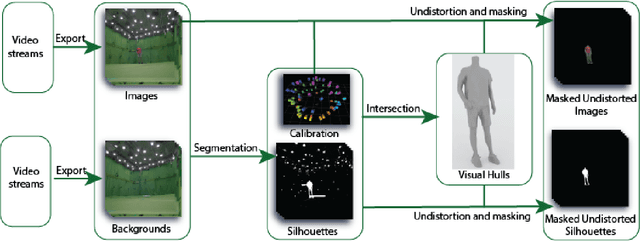
This work presents 4DHumanOutfit, a new dataset of densely sampled spatio-temporal 4D human motion data of different actors, outfits and motions. The dataset is designed to contain different actors wearing different outfits while performing different motions in each outfit. In this way, the dataset can be seen as a cube of data containing 4D motion sequences along 3 axes with identity, outfit and motion. This rich dataset has numerous potential applications for the processing and creation of digital humans, e.g. augmented reality, avatar creation and virtual try on. 4DHumanOutfit is released for research purposes at https://kinovis.inria.fr/4dhumanoutfit/. In addition to image data and 4D reconstructions, the dataset includes reference solutions for each axis. We present independent baselines along each axis that demonstrate the value of these reference solutions for evaluation tasks.
Investigating the Role of Image Retrieval for Visual Localization -- An exhaustive benchmark
May 31, 2022Visual localization, i.e., camera pose estimation in a known scene, is a core component of technologies such as autonomous driving and augmented reality. State-of-the-art localization approaches often rely on image retrieval techniques for one of two purposes: (1) provide an approximate pose estimate or (2) determine which parts of the scene are potentially visible in a given query image. It is common practice to use state-of-the-art image retrieval algorithms for both of them. These algorithms are often trained for the goal of retrieving the same landmark under a large range of viewpoint changes which often differs from the requirements of visual localization. In order to investigate the consequences for visual localization, this paper focuses on understanding the role of image retrieval for multiple visual localization paradigms. First, we introduce a novel benchmark setup and compare state-of-the-art retrieval representations on multiple datasets using localization performance as metric. Second, we investigate several definitions of "ground truth" for image retrieval. Using these definitions as upper bounds for the visual localization paradigms, we show that there is still sgnificant room for improvement. Third, using these tools and in-depth analysis, we show that retrieval performance on classical landmark retrieval or place recognition tasks correlates only for some but not all paradigms to localization performance. Finally, we analyze the effects of blur and dynamic scenes in the images. We conclude that there is a need for retrieval approaches specifically designed for localization paradigms. Our benchmark and evaluation protocols are available at https://github.com/naver/kapture-localization.
On the Limits of Pseudo Ground Truth in Visual Camera Re-localisation
Sep 01, 2021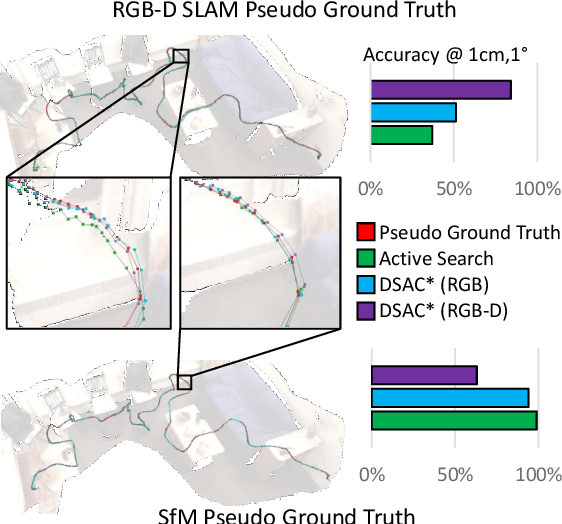
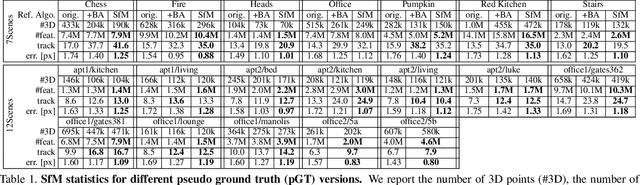
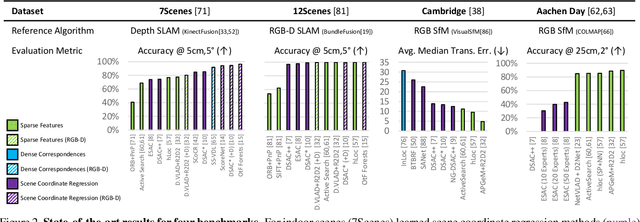

Benchmark datasets that measure camera pose accuracy have driven progress in visual re-localisation research. To obtain poses for thousands of images, it is common to use a reference algorithm to generate pseudo ground truth. Popular choices include Structure-from-Motion (SfM) and Simultaneous-Localisation-and-Mapping (SLAM) using additional sensors like depth cameras if available. Re-localisation benchmarks thus measure how well each method replicates the results of the reference algorithm. This begs the question whether the choice of the reference algorithm favours a certain family of re-localisation methods. This paper analyzes two widely used re-localisation datasets and shows that evaluation outcomes indeed vary with the choice of the reference algorithm. We thus question common beliefs in the re-localisation literature, namely that learning-based scene coordinate regression outperforms classical feature-based methods, and that RGB-D-based methods outperform RGB-based methods. We argue that any claims on ranking re-localisation methods should take the type of the reference algorithm, and the similarity of the methods to the reference algorithm, into account.
Large-scale Localization Datasets in Crowded Indoor Spaces
May 19, 2021
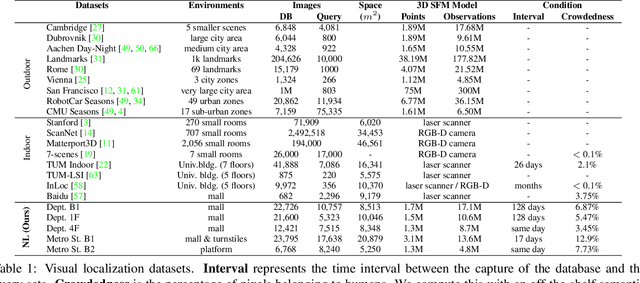


Estimating the precise location of a camera using visual localization enables interesting applications such as augmented reality or robot navigation. This is particularly useful in indoor environments where other localization technologies, such as GNSS, fail. Indoor spaces impose interesting challenges on visual localization algorithms: occlusions due to people, textureless surfaces, large viewpoint changes, low light, repetitive textures, etc. Existing indoor datasets are either comparably small or do only cover a subset of the mentioned challenges. In this paper, we introduce 5 new indoor datasets for visual localization in challenging real-world environments. They were captured in a large shopping mall and a large metro station in Seoul, South Korea, using a dedicated mapping platform consisting of 10 cameras and 2 laser scanners. In order to obtain accurate ground truth camera poses, we developed a robust LiDAR SLAM which provides initial poses that are then refined using a novel structure-from-motion based optimization. We present a benchmark of modern visual localization algorithms on these challenging datasets showing superior performance of structure-based methods using robust image features. The datasets are available at: https://naverlabs.com/datasets
Benchmarking Image Retrieval for Visual Localization
Dec 01, 2020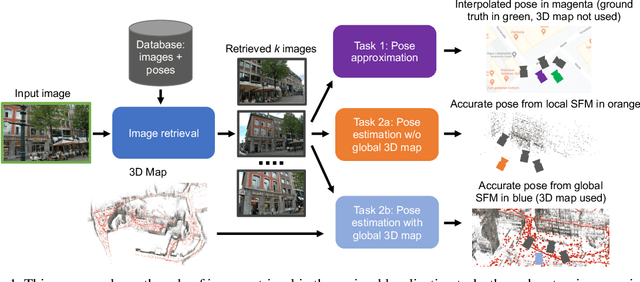

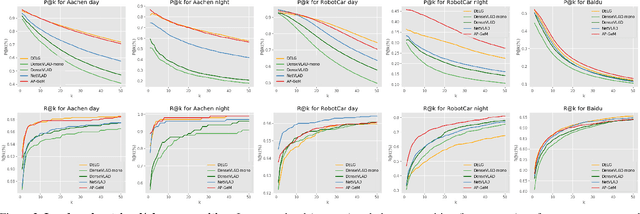
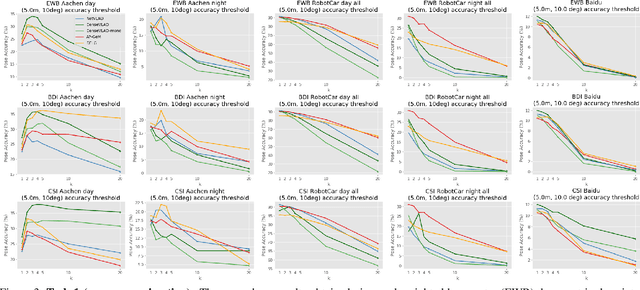
Visual localization, i.e., camera pose estimation in a known scene, is a core component of technologies such as autonomous driving and augmented reality. State-of-the-art localization approaches often rely on image retrieval techniques for one of two tasks: (1) provide an approximate pose estimate or (2) determine which parts of the scene are potentially visible in a given query image. It is common practice to use state-of-the-art image retrieval algorithms for these tasks. These algorithms are often trained for the goal of retrieving the same landmark under a large range of viewpoint changes. However, robustness to viewpoint changes is not necessarily desirable in the context of visual localization. This paper focuses on understanding the role of image retrieval for multiple visual localization tasks. We introduce a benchmark setup and compare state-of-the-art retrieval representations on multiple datasets. We show that retrieval performance on classical landmark retrieval/recognition tasks correlates only for some but not all tasks to localization performance. This indicates a need for retrieval approaches specifically designed for localization tasks. Our benchmark and evaluation protocols are available at https://github.com/naver/kapture-localization.
Robust Image Retrieval-based Visual Localization using Kapture
Aug 31, 2020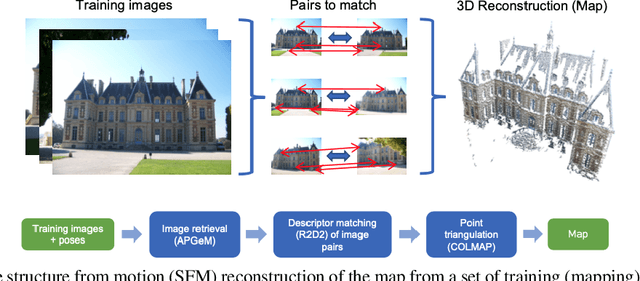
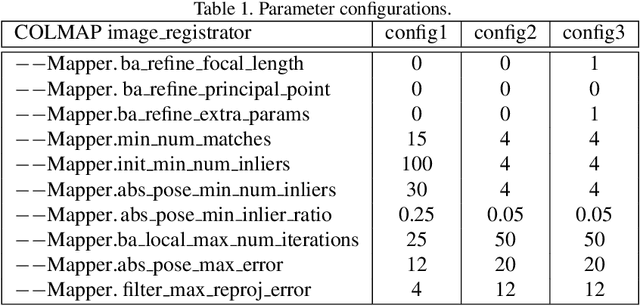
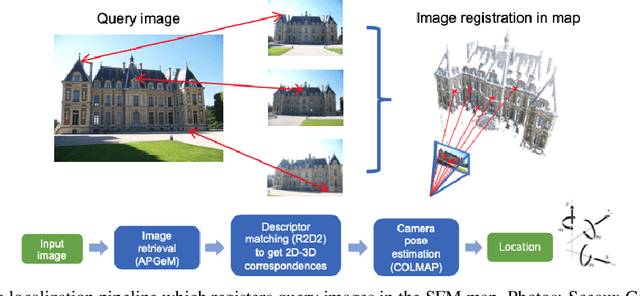

In this paper, we present a versatile method for visual localization. It is based on robust image retrieval for coarse camera pose estimation and robust local features for accurate pose refinement. Our method is top ranked on various public datasets showing its ability of generalization and its great variety of applications. To facilitate experiments, we introduce kapture, a flexible data format and processing pipeline for structure from motion and visual localization that is released open source. We furthermore provide all datasets used in this paper in the kapture format to facilitate research and data processing. Code and datasets can be found at https://github.com/naver/kapture, more information, updates, and news can be found at https://europe.naverlabs.com/research/3d-vision/kapture.
Virtual KITTI 2
Jan 29, 2020
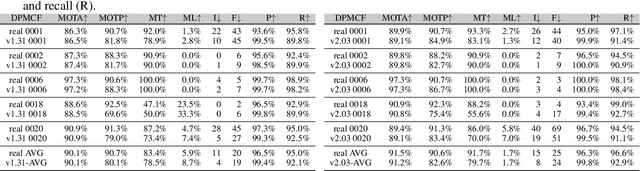

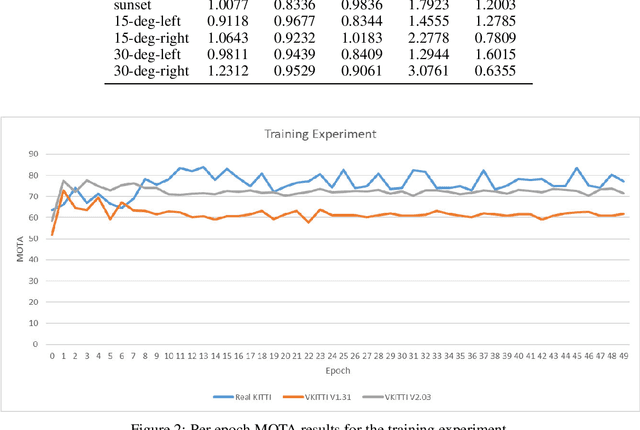
This paper introduces an updated version of the well-known Virtual KITTI dataset which consists of 5 sequence clones from the KITTI tracking benchmark. In addition, the dataset provides different variants of these sequences such as modified weather conditions (e.g. fog, rain) or modified camera configurations (e.g. rotated by 15 degrees). For each sequence, we provide multiple sets of images containing RGB, depth, class segmentation, instance segmentation, flow, and scene flow data. Camera parameters and poses as well as vehicle locations are available as well. In order to showcase some of the dataset's capabilities, we ran multiple relevant experiments using state-of-the-art algorithms from the field of autonomous driving. The dataset is available for download at https://europe.naverlabs.com/Research/Computer-Vision/Proxy-Virtual-Worlds.
R2D2: Repeatable and Reliable Detector and Descriptor
Jun 17, 2019

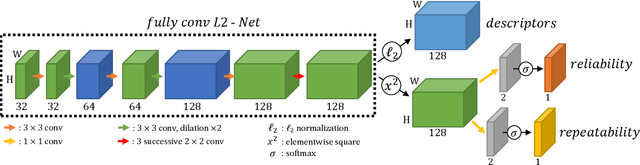
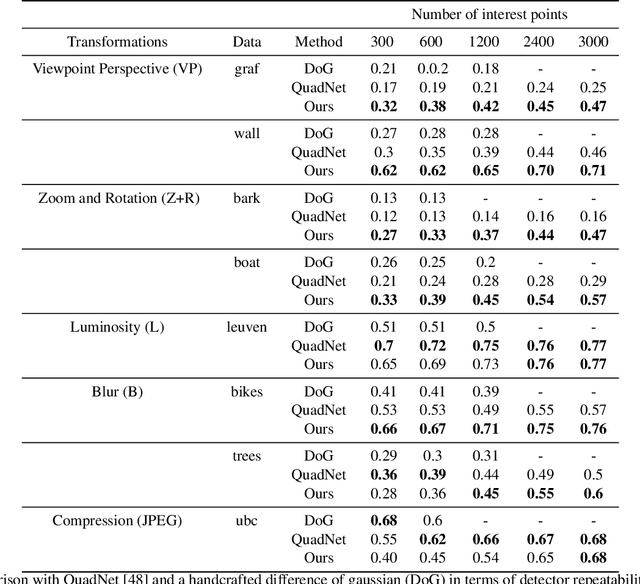
Interest point detection and local feature description are fundamental steps in many computer vision applications. Classical methods for these tasks are based on a detect-then-describe paradigm where separate handcrafted methods are used to first identify repeatable keypoints and then represent them with a local descriptor. Neural networks trained with metric learning losses have recently caught up with these techniques, focusing on learning repeatable saliency maps for keypoint detection and learning descriptors at the detected keypoint locations. In this work, we argue that salient regions are not necessarily discriminative, and therefore can harm the performance of the description. Furthermore, we claim that descriptors should be learned only in regions for which matching can be performed with high confidence. We thus propose to jointly learn keypoint detection and description together with a predictor of the local descriptor discriminativeness. This allows us to avoid ambiguous areas and leads to reliable keypoint detections and descriptions. Our detection-and-description approach, trained with self-supervision, can simultaneously output sparse, repeatable and reliable keypoints that outperforms state-of-the-art detectors and descriptors on the HPatches dataset. It also establishes a record on the recently released Aachen Day-Night localization dataset.