 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Language Modeling: An Exploration of Multimodal Pretraining
Mar 03, 2026The visual world offers a critical axis for advancing foundation models beyond language. Despite growing interest in this direction, the design space for native multimodal models remains opaque. We provide empirical clarity through controlled, from-scratch pretraining experiments, isolating the factors that govern multimodal pretraining without interference from language pretraining. We adopt the Transfusion framework, using next-token prediction for language and diffusion for vision, to train on diverse data including text, video, image-text pairs, and even action-conditioned video. Our experiments yield four key insights: (i) Representation Autoencoder (RAE) provides an optimal unified visual representation by excelling at both visual understanding and generation; (ii) visual and language data are complementary and yield synergy for downstream capabilities; (iii) unified multimodal pretraining leads naturally to world modeling, with capabilities emerging from general training; and (iv) Mixture-of-Experts (MoE) enables efficient and effective multimodal scaling while naturally inducing modality specialization. Through IsoFLOP analysis, we compute scaling laws for both modalities and uncover a scaling asymmetry: vision is significantly more data-hungry than language. We demonstrate that the MoE architecture harmonizes this scaling asymmetry by providing the high model capacity required by language while accommodating the data-intensive nature of vision, paving the way for truly unified multimodal models.
Inference-time sparse attention with asymmetric indexing
Feb 12, 2025



Self-attention in transformer models is an incremental associative memory that maps key vectors to value vectors. One way to speed up self-attention is to employ GPU-compliant vector search algorithms, yet the standard partitioning methods yield poor results in this context, because (1) keys and queries follow different distributions and (2) the effect of RoPE positional encoding. In this paper, we introduce SAAP (Self-Attention with Asymmetric Partitions), which overcomes these problems. It is an asymmetrical indexing technique that employs distinct partitions for keys and queries, thereby approximating self-attention with a data-adaptive sparsity pattern. It works on pretrained language models without finetuning, as it only requires to train (offline) a small query classifier. On a long context Llama 3.1-8b model, with sequences ranging from 100k to 500k tokens, our method typically reduces by a factor 20 the fraction of memory that needs to be looked-up, which translates to a time saving of 60\% when compared to FlashAttention-v2.
Distilling Self-Supervised Vision Transformers for Weakly-Supervised Few-Shot Classification & Segmentation
Jul 07, 2023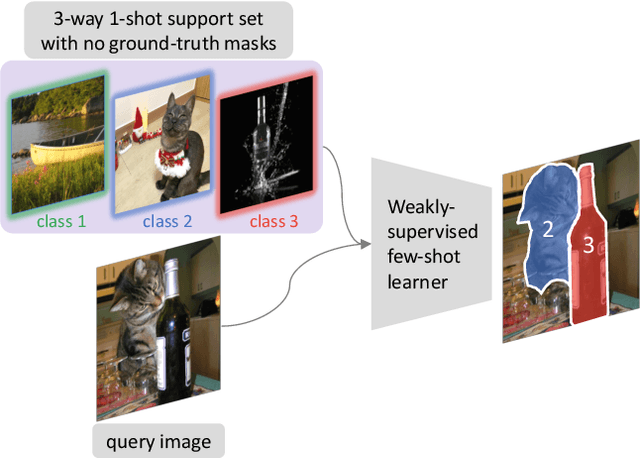

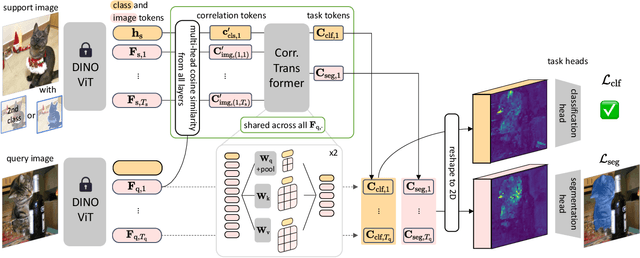

We address the task of weakly-supervised few-shot image classification and segmentation, by leveraging a Vision Transformer (ViT) pretrained with self-supervision. Our proposed method takes token representations from the self-supervised ViT and leverages their correlations, via self-attention, to produce classification and segmentation predictions through separate task heads. Our model is able to effectively learn to perform classification and segmentation in the absence of pixel-level labels during training, using only image-level labels. To do this it uses attention maps, created from tokens generated by the self-supervised ViT backbone, as pixel-level pseudo-labels. We also explore a practical setup with ``mixed" supervision, where a small number of training images contains ground-truth pixel-level labels and the remaining images have only image-level labels. For this mixed setup, we propose to improve the pseudo-labels using a pseudo-label enhancer that was trained using the available ground-truth pixel-level labels. Experiments on Pascal-5i and COCO-20i demonstrate significant performance gains in a variety of supervision settings, and in particular when little-to-no pixel-level labels are available.
* Accepted at CVPR 2023
Dungeons and Data: A Large-Scale NetHack Dataset
Nov 22, 2022Recent breakthroughs in the development of agents to solve challenging sequential decision making problems such as Go, StarCraft, or DOTA, have relied on both simulated environments and large-scale datasets. However, progress on this research has been hindered by the scarcity of open-sourced datasets and the prohibitive computational cost to work with them. Here we present the NetHack Learning Dataset (NLD), a large and highly-scalable dataset of trajectories from the popular game of NetHack, which is both extremely challenging for current methods and very fast to run. NLD consists of three parts: 10 billion state transitions from 1.5 million human trajectories collected on the NAO public NetHack server from 2009 to 2020; 3 billion state-action-score transitions from 100,000 trajectories collected from the symbolic bot winner of the NetHack Challenge 2021; and, accompanying code for users to record, load and stream any collection of such trajectories in a highly compressed form. We evaluate a wide range of existing algorithms including online and offline RL, as well as learning from demonstrations, showing that significant research advances are needed to fully leverage large-scale datasets for challenging sequential decision making tasks.
Time-rEversed diffusioN tEnsor Transformer: A new TENET of Few-Shot Object Detection
Oct 30, 2022In this paper, we tackle the challenging problem of Few-shot Object Detection. Existing FSOD pipelines (i) use average-pooled representations that result in information loss; and/or (ii) discard position information that can help detect object instances. Consequently, such pipelines are sensitive to large intra-class appearance and geometric variations between support and query images. To address these drawbacks, we propose a Time-rEversed diffusioN tEnsor Transformer (TENET), which i) forms high-order tensor representations that capture multi-way feature occurrences that are highly discriminative, and ii) uses a transformer that dynamically extracts correlations between the query image and the entire support set, instead of a single average-pooled support embedding. We also propose a Transformer Relation Head (TRH), equipped with higher-order representations, which encodes correlations between query regions and the entire support set, while being sensitive to the positional variability of object instances. Our model achieves state-of-the-art results on PASCAL VOC, FSOD, and COCO.
Temporally-Weighted Hierarchical Clustering for Unsupervised Action Segmentation
Mar 27, 2021

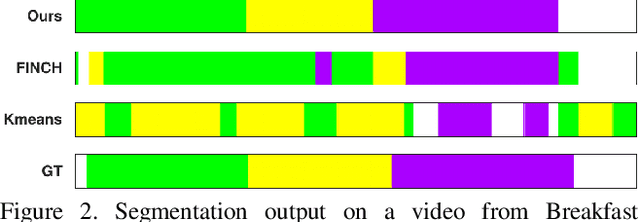
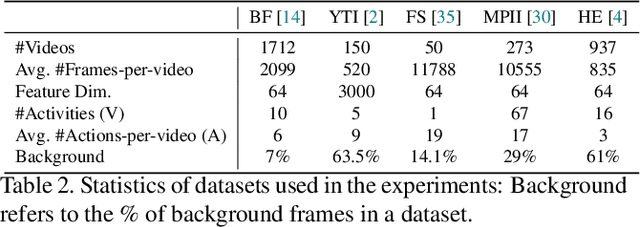
Action segmentation refers to inferring boundaries of semantically consistent visual concepts in videos and is an important requirement for many video understanding tasks. For this and other video understanding tasks, supervised approaches have achieved encouraging performance but require a high volume of detailed frame-level annotations. We present a fully automatic and unsupervised approach for segmenting actions in a video that does not require any training. Our proposal is an effective temporally-weighted hierarchical clustering algorithm that can group semantically consistent frames of the video. Our main finding is that representing a video with a 1-nearest neighbor graph by taking into account the time progression is sufficient to form semantically and temporally consistent clusters of frames where each cluster may represent some action in the video. Additionally, we establish strong unsupervised baselines for action segmentation and show significant performance improvements over published unsupervised methods on five challenging action segmentation datasets. Our code is available at https://github.com/ssarfraz/FINCH-Clustering/tree/master/TW-FINCH
Virtual KITTI 2
Jan 29, 2020
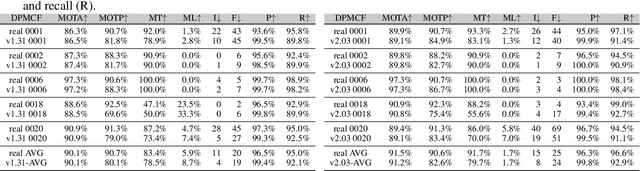

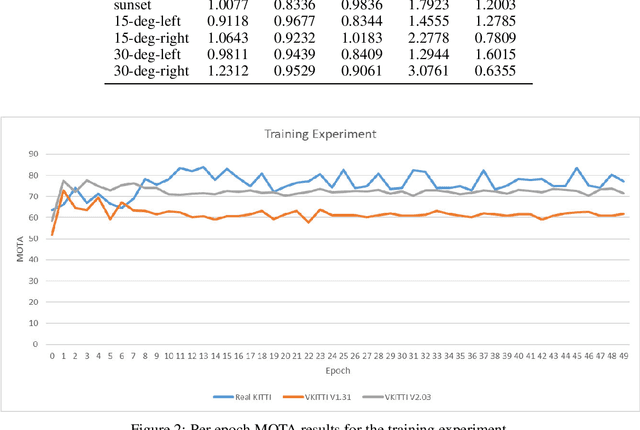
This paper introduces an updated version of the well-known Virtual KITTI dataset which consists of 5 sequence clones from the KITTI tracking benchmark. In addition, the dataset provides different variants of these sequences such as modified weather conditions (e.g. fog, rain) or modified camera configurations (e.g. rotated by 15 degrees). For each sequence, we provide multiple sets of images containing RGB, depth, class segmentation, instance segmentation, flow, and scene flow data. Camera parameters and poses as well as vehicle locations are available as well. In order to showcase some of the dataset's capabilities, we ran multiple relevant experiments using state-of-the-art algorithms from the field of autonomous driving. The dataset is available for download at https://europe.naverlabs.com/Research/Computer-Vision/Proxy-Virtual-Worlds.
Generating Human Action Videos by Coupling 3D Game Engines and Probabilistic Graphical Models
Oct 12, 2019



Deep video action recognition models have been highly successful in recent years but require large quantities of manually annotated data, which are expensive and laborious to obtain. In this work, we investigate the generation of synthetic training data for video action recognition, as synthetic data have been successfully used to supervise models for a variety of other computer vision tasks. We propose an interpretable parametric generative model of human action videos that relies on procedural generation, physics models and other components of modern game engines. With this model we generate a diverse, realistic, and physically plausible dataset of human action videos, called PHAV for "Procedural Human Action Videos". PHAV contains a total of 39,982 videos, with more than 1,000 examples for each of 35 action categories. Our video generation approach is not limited to existing motion capture sequences: 14 of these 35 categories are procedurally defined synthetic actions. In addition, each video is represented with 6 different data modalities, including RGB, optical flow and pixel-level semantic labels. These modalities are generated almost simultaneously using the Multiple Render Targets feature of modern GPUs. In order to leverage PHAV, we introduce a deep multi-task (i.e. that considers action classes from multiple datasets) representation learning architecture that is able to simultaneously learn from synthetic and real video datasets, even when their action categories differ. Our experiments on the UCF-101 and HMDB-51 benchmarks suggest that combining our large set of synthetic videos with small real-world datasets can boost recognition performance. Our approach also significantly outperforms video representations produced by fine-tuning state-of-the-art unsupervised generative models of videos.
End-to-End Saliency Mapping via Probability Distribution Prediction
Apr 05, 2018

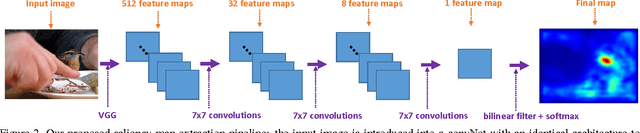
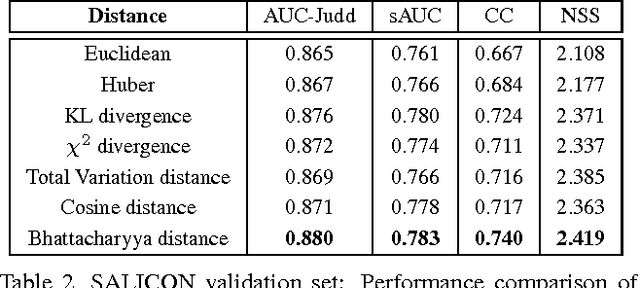
Most saliency estimation methods aim to explicitly model low-level conspicuity cues such as edges or blobs and may additionally incorporate top-down cues using face or text detection. Data-driven methods for training saliency models using eye-fixation data are increasingly popular, particularly with the introduction of large-scale datasets and deep architectures. However, current methods in this latter paradigm use loss functions designed for classification or regression tasks whereas saliency estimation is evaluated on topographical maps. In this work, we introduce a new saliency map model which formulates a map as a generalized Bernoulli distribution. We then train a deep architecture to predict such maps using novel loss functions which pair the softmax activation function with measures designed to compute distances between probability distributions. We show in extensive experiments the effectiveness of such loss functions over standard ones on four public benchmark datasets, and demonstrate improved performance over state-of-the-art saliency methods.
Re-ID done right: towards good practices for person re-identification
Jan 16, 2018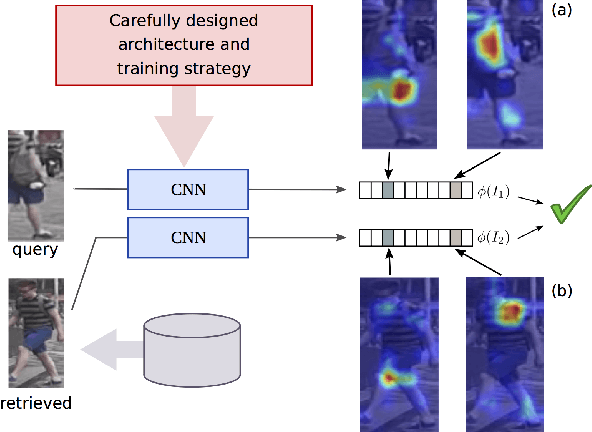

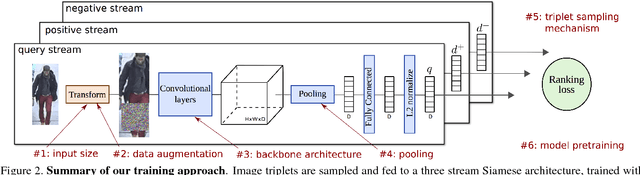
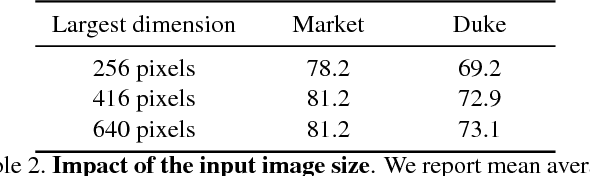
Training a deep architecture using a ranking loss has become standard for the person re-identification task. Increasingly, these deep architectures include additional components that leverage part detections, attribute predictions, pose estimators and other auxiliary information, in order to more effectively localize and align discriminative image regions. In this paper we adopt a different approach and carefully design each component of a simple deep architecture and, critically, the strategy for training it effectively for person re-identification. We extensively evaluate each design choice, leading to a list of good practices for person re-identification. By following these practices, our approach outperforms the state of the art, including more complex methods with auxiliary components, by large margins on four benchmark datasets. We also provide a qualitative analysis of our trained representation which indicates that, while compact, it is able to capture information from localized and discriminative regions, in a manner akin to an implicit attention mechanism.