 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRLEF: Grounding Code LLMs in Execution Feedback with Reinforcement Learning
Oct 02, 2024


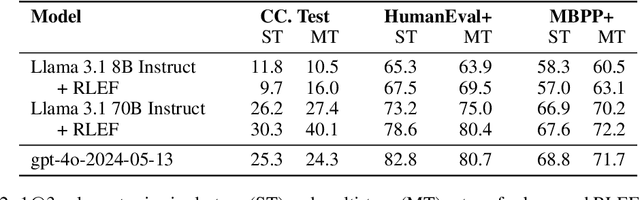
Large language models (LLMs) deployed as agents solve user-specified tasks over multiple steps while keeping the required manual engagement to a minimum. Crucially, such LLMs need to ground their generations in any feedback obtained to reliably achieve desired outcomes. We propose an end-to-end reinforcement learning method for teaching models to leverage execution feedback in the realm of code synthesis, where state-of-the-art LLMs struggle to improve code iteratively compared to independent sampling. We benchmark on competitive programming tasks, where we achieve new start-of-the art results with both small (8B parameters) and large (70B) models while reducing the amount of samples required by an order of magnitude. Our analysis of inference-time behavior demonstrates that our method produces LLMs that effectively leverage automatic feedback over multiple steps.
Dungeons and Data: A Large-Scale NetHack Dataset
Nov 22, 2022Recent breakthroughs in the development of agents to solve challenging sequential decision making problems such as Go, StarCraft, or DOTA, have relied on both simulated environments and large-scale datasets. However, progress on this research has been hindered by the scarcity of open-sourced datasets and the prohibitive computational cost to work with them. Here we present the NetHack Learning Dataset (NLD), a large and highly-scalable dataset of trajectories from the popular game of NetHack, which is both extremely challenging for current methods and very fast to run. NLD consists of three parts: 10 billion state transitions from 1.5 million human trajectories collected on the NAO public NetHack server from 2009 to 2020; 3 billion state-action-score transitions from 100,000 trajectories collected from the symbolic bot winner of the NetHack Challenge 2021; and, accompanying code for users to record, load and stream any collection of such trajectories in a highly compressed form. We evaluate a wide range of existing algorithms including online and offline RL, as well as learning from demonstrations, showing that significant research advances are needed to fully leverage large-scale datasets for challenging sequential decision making tasks.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022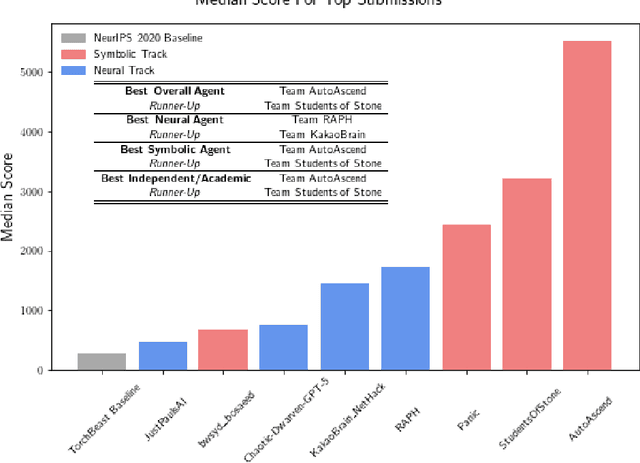

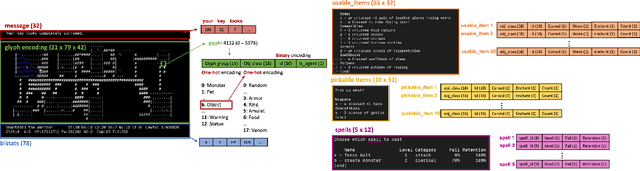
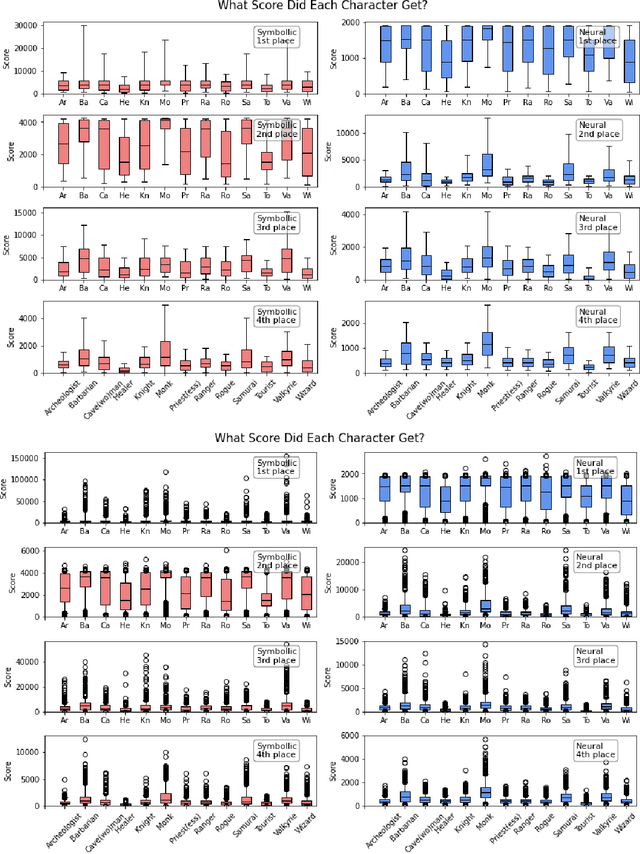
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
Transfer of Fully Convolutional Policy-Value Networks Between Games and Game Variants
Feb 24, 2021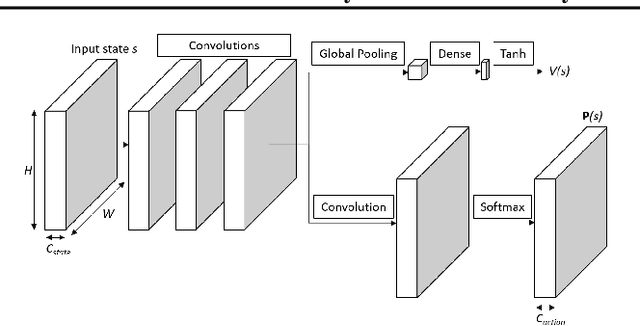
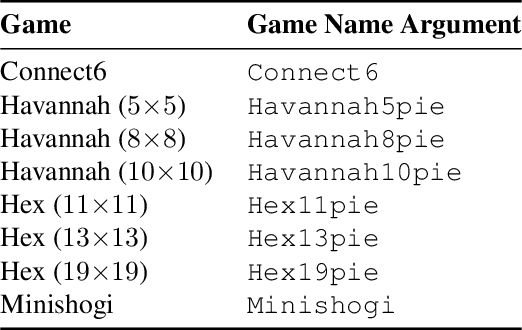
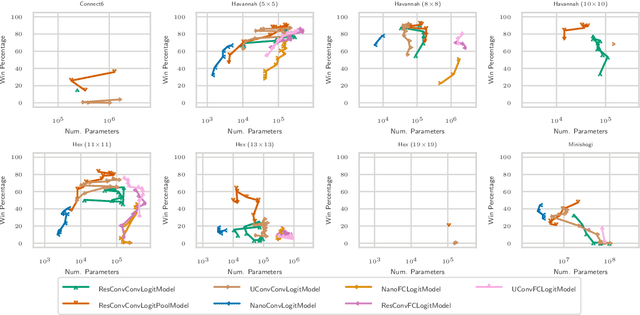
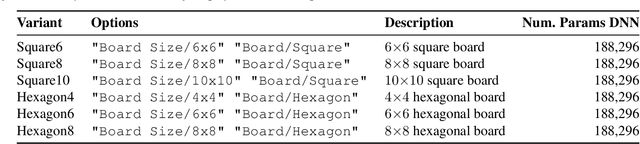
In this paper, we use fully convolutional architectures in AlphaZero-like self-play training setups to facilitate transfer between variants of board games as well as distinct games. We explore how to transfer trained parameters of these architectures based on shared semantics of channels in the state and action representations of the Ludii general game system. We use Ludii's large library of games and game variants for extensive transfer learning evaluations, in zero-shot transfer experiments as well as experiments with additional fine-tuning time.
Deep Learning for General Game Playing with Ludii and Polygames
Jan 23, 2021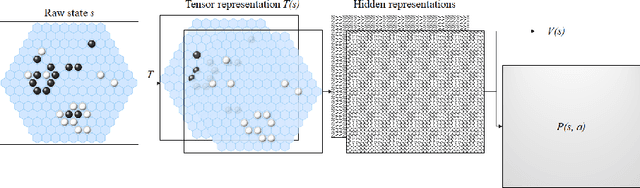

Combinations of Monte-Carlo tree search and Deep Neural Networks, trained through self-play, have produced state-of-the-art results for automated game-playing in many board games. The training and search algorithms are not game-specific, but every individual game that these approaches are applied to still requires domain knowledge for the implementation of the game's rules, and constructing the neural network's architecture -- in particular the shapes of its input and output tensors. Ludii is a general game system that already contains over 500 different games, which can rapidly grow thanks to its powerful and user-friendly game description language. Polygames is a framework with training and search algorithms, which has already produced superhuman players for several board games. This paper describes the implementation of a bridge between Ludii and Polygames, which enables Polygames to train and evaluate models for games that are implemented and run through Ludii. We do not require any game-specific domain knowledge anymore, and instead leverage our domain knowledge of the Ludii system and its abstract state and move representations to write functions that can automatically determine the appropriate shapes for input and output tensors for any game implemented in Ludii. We describe experimental results for short training runs in a wide variety of different board games, and discuss several open problems and avenues for future research.
Polygames: Improved Zero Learning
Jan 27, 2020
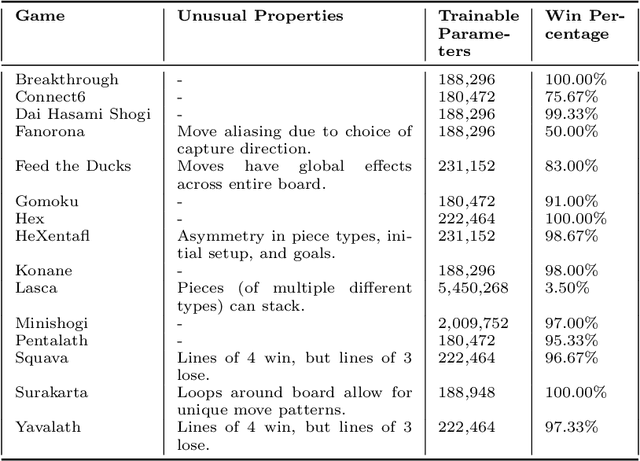
Since DeepMind's AlphaZero, Zero learning quickly became the state-of-the-art method for many board games. It can be improved using a fully convolutional structure (no fully connected layer). Using such an architecture plus global pooling, we can create bots independent of the board size. The training can be made more robust by keeping track of the best checkpoints during the training and by training against them. Using these features, we release Polygames, our framework for Zero learning, with its library of games and its checkpoints. We won against strong humans at the game of Hex in 19x19, which was often said to be untractable for zero learning; and in Havannah. We also won several first places at the TAAI competitions.
Forward Modeling for Partial Observation Strategy Games - A StarCraft Defogger
Nov 30, 2018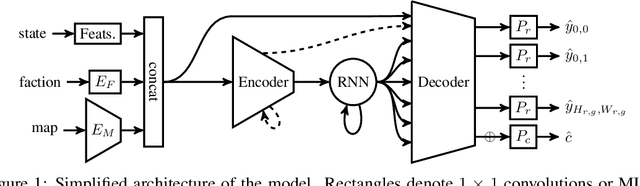
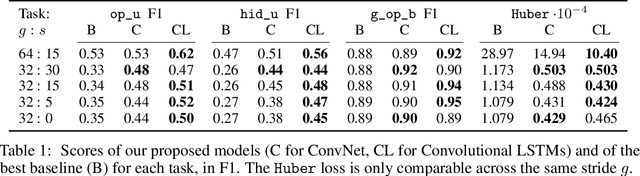
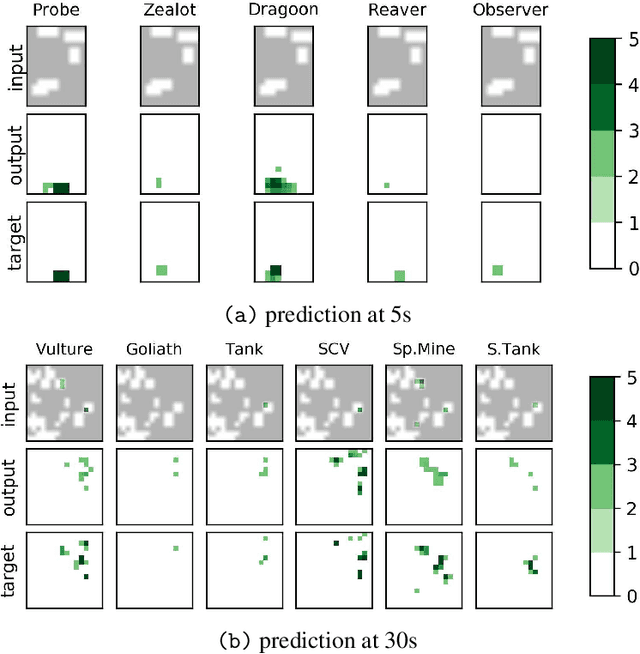
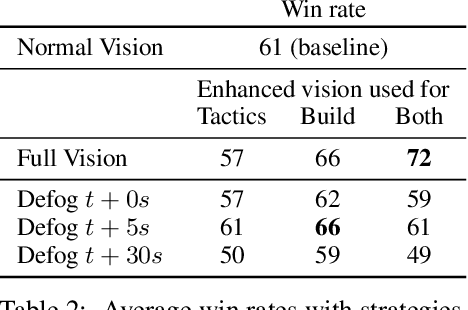
We formulate the problem of defogging as state estimation and future state prediction from previous, partial observations in the context of real-time strategy games. We propose to employ encoder-decoder neural networks for this task, and introduce proxy tasks and baselines for evaluation to assess their ability of capturing basic game rules and high-level dynamics. By combining convolutional neural networks and recurrent networks, we exploit spatial and sequential correlations and train well-performing models on a large dataset of human games of StarCraft: Brood War. Finally, we demonstrate the relevance of our models to downstream tasks by applying them for enemy unit prediction in a state-of-the-art, rule-based StarCraft bot. We observe improvements in win rates against several strong community bots.
High-Level Strategy Selection under Partial Observability in StarCraft: Brood War
Nov 21, 2018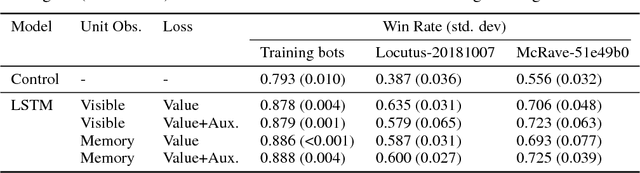
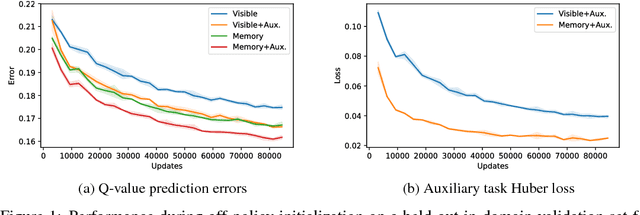

We consider the problem of high-level strategy selection in the adversarial setting of real-time strategy games from a reinforcement learning perspective, where taking an action corresponds to switching to the respective strategy. Here, a good strategy successfully counters the opponent's current and possible future strategies which can only be estimated using partial observations. We investigate whether we can utilize the full game state information during training time (in the form of an auxiliary prediction task) to increase performance. Experiments carried out within a StarCraft: Brood War bot against strong community bots show substantial win rate improvements over a fixed-strategy baseline and encouraging results when learning with the auxiliary task.