 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyTorch: An Imperative Style, High-Performance Deep Learning Library
Dec 03, 2019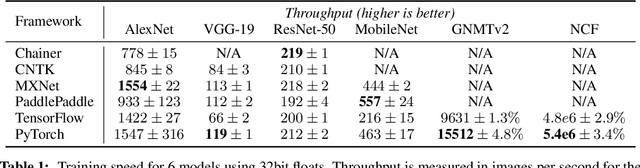

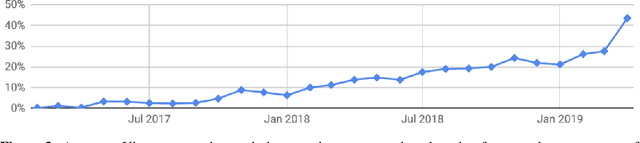
Deep learning frameworks have often focused on either usability or speed, but not both. PyTorch is a machine learning library that shows that these two goals are in fact compatible: it provides an imperative and Pythonic programming style that supports code as a model, makes debugging easy and is consistent with other popular scientific computing libraries, while remaining efficient and supporting hardware accelerators such as GPUs. In this paper, we detail the principles that drove the implementation of PyTorch and how they are reflected in its architecture. We emphasize that every aspect of PyTorch is a regular Python program under the full control of its user. We also explain how the careful and pragmatic implementation of the key components of its runtime enables them to work together to achieve compelling performance. We demonstrate the efficiency of individual subsystems, as well as the overall speed of PyTorch on several common benchmarks.
Growing Action Spaces
Jun 28, 2019

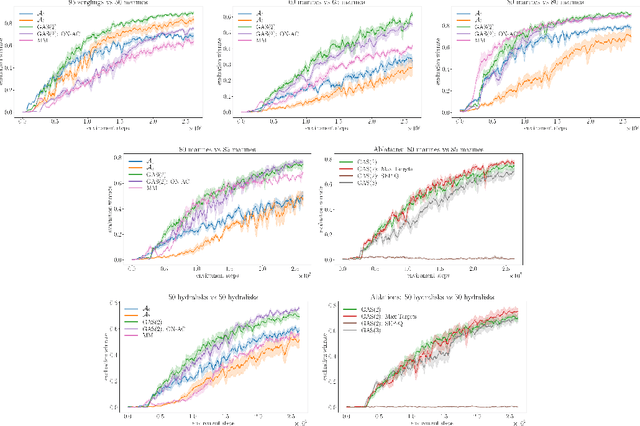

In complex tasks, such as those with large combinatorial action spaces, random exploration may be too inefficient to achieve meaningful learning progress. In this work, we use a curriculum of progressively growing action spaces to accelerate learning. We assume the environment is out of our control, but that the agent may set an internal curriculum by initially restricting its action space. Our approach uses off-policy reinforcement learning to estimate optimal value functions for multiple action spaces simultaneously and efficiently transfers data, value estimates, and state representations from restricted action spaces to the full task. We show the efficacy of our approach in proof-of-concept control tasks and on challenging large-scale StarCraft micromanagement tasks with large, multi-agent action spaces.
Forward Modeling for Partial Observation Strategy Games - A StarCraft Defogger
Nov 30, 2018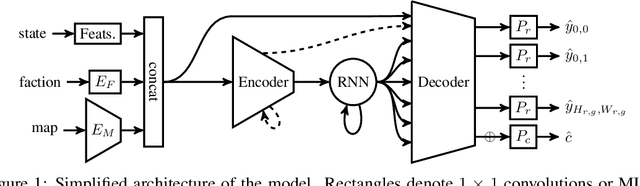
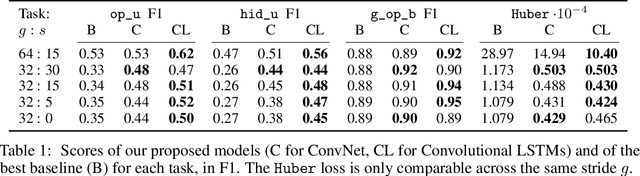
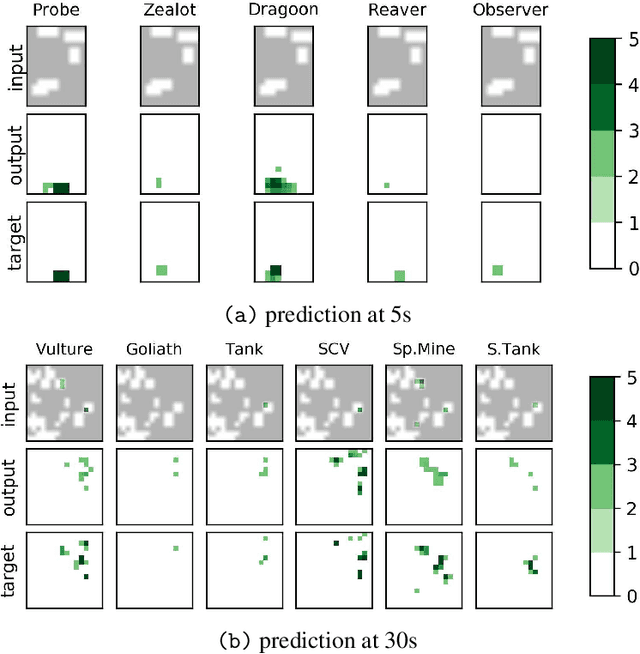
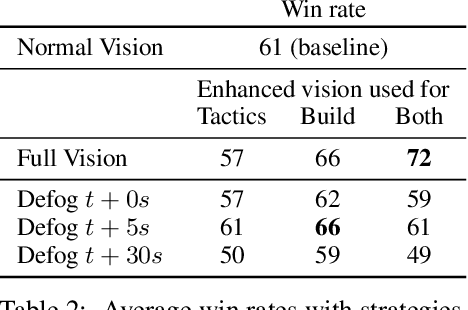
We formulate the problem of defogging as state estimation and future state prediction from previous, partial observations in the context of real-time strategy games. We propose to employ encoder-decoder neural networks for this task, and introduce proxy tasks and baselines for evaluation to assess their ability of capturing basic game rules and high-level dynamics. By combining convolutional neural networks and recurrent networks, we exploit spatial and sequential correlations and train well-performing models on a large dataset of human games of StarCraft: Brood War. Finally, we demonstrate the relevance of our models to downstream tasks by applying them for enemy unit prediction in a state-of-the-art, rule-based StarCraft bot. We observe improvements in win rates against several strong community bots.
Value Propagation Networks
May 28, 2018


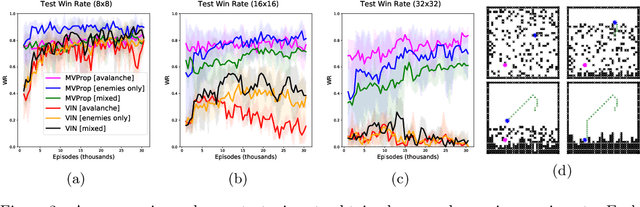
We present Value Propagation (VProp), a parameter-efficient differentiable planning module built on Value Iteration which can successfully be trained using reinforcement learning to solve unseen tasks, has the capability to generalize to larger map sizes, and can learn to navigate in dynamic environments. Furthermore, we show that the module enables learning to plan when the environment also includes stochastic elements, providing a cost-efficient learning system to build low-level size-invariant planners for a variety of interactive navigation problems. We evaluate on static and dynamic configurations of MazeBase grid-worlds, with randomly generated environments of several different sizes, and on a StarCraft navigation scenario, with more complex dynamics, and pixels as input.
Intrinsic Motivation and Automatic Curricula via Asymmetric Self-Play
Apr 27, 2018
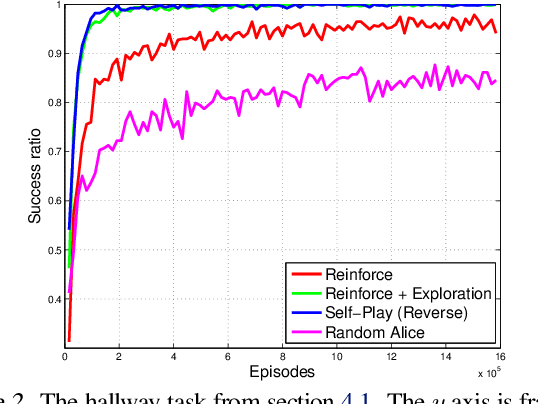
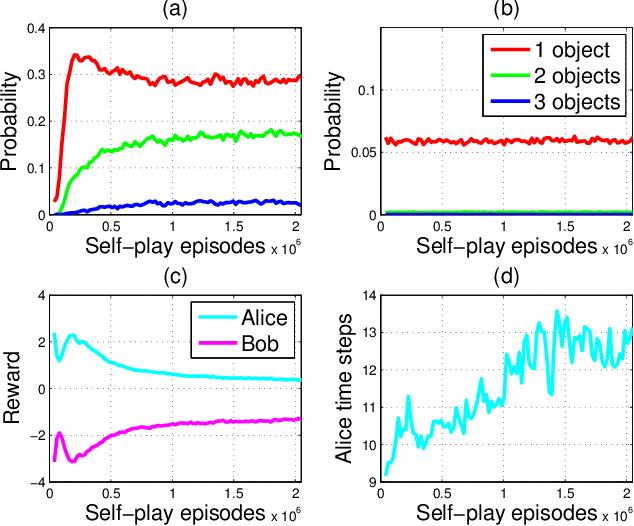

We describe a simple scheme that allows an agent to learn about its environment in an unsupervised manner. Our scheme pits two versions of the same agent, Alice and Bob, against one another. Alice proposes a task for Bob to complete; and then Bob attempts to complete the task. In this work we will focus on two kinds of environments: (nearly) reversible environments and environments that can be reset. Alice will "propose" the task by doing a sequence of actions and then Bob must undo or repeat them, respectively. Via an appropriate reward structure, Alice and Bob automatically generate a curriculum of exploration, enabling unsupervised training of the agent. When Bob is deployed on an RL task within the environment, this unsupervised training reduces the number of supervised episodes needed to learn, and in some cases converges to a higher reward.
STARDATA: A StarCraft AI Research Dataset
Aug 07, 2017
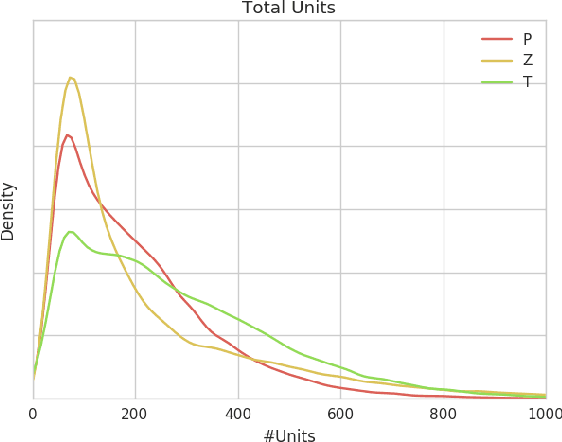

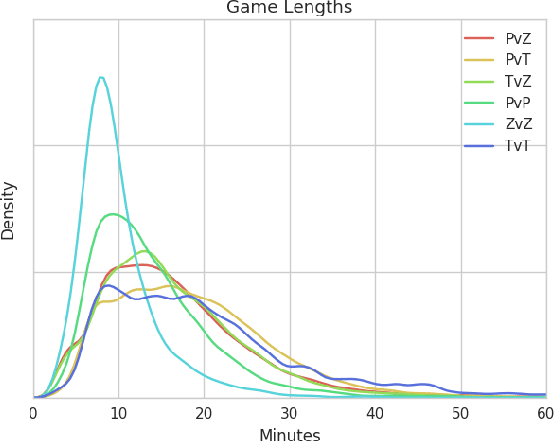
We release a dataset of 65646 StarCraft replays that contains 1535 million frames and 496 million player actions. We provide full game state data along with the original replays that can be viewed in StarCraft. The game state data was recorded every 3 frames which ensures suitability for a wide variety of machine learning tasks such as strategy classification, inverse reinforcement learning, imitation learning, forward modeling, partial information extraction, and others. We use TorchCraft to extract and store the data, which standardizes the data format for both reading from replays and reading directly from the game. Furthermore, the data can be used on different operating systems and platforms. The dataset contains valid, non-corrupted replays only and its quality and diversity was ensured by a number of heuristics. We illustrate the diversity of the data with various statistics and provide examples of tasks that benefit from the dataset. We make the dataset available at https://github.com/TorchCraft/StarData . En Taro Adun!
DeepCloak: Masking Deep Neural Network Models for Robustness Against Adversarial Samples
Apr 17, 2017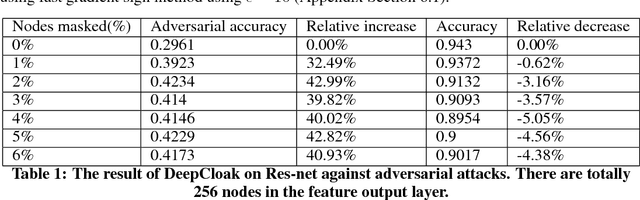
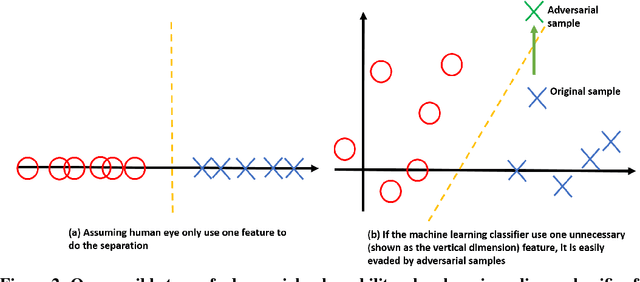
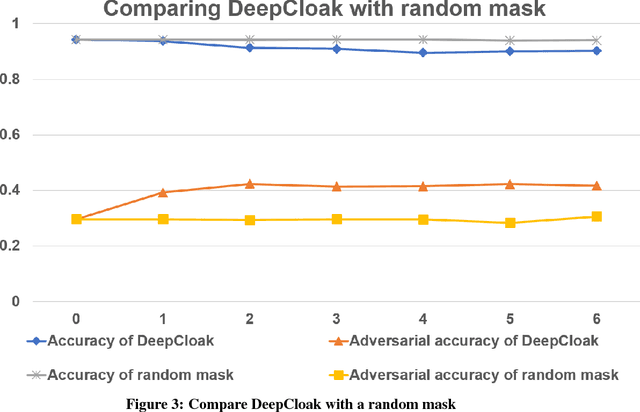
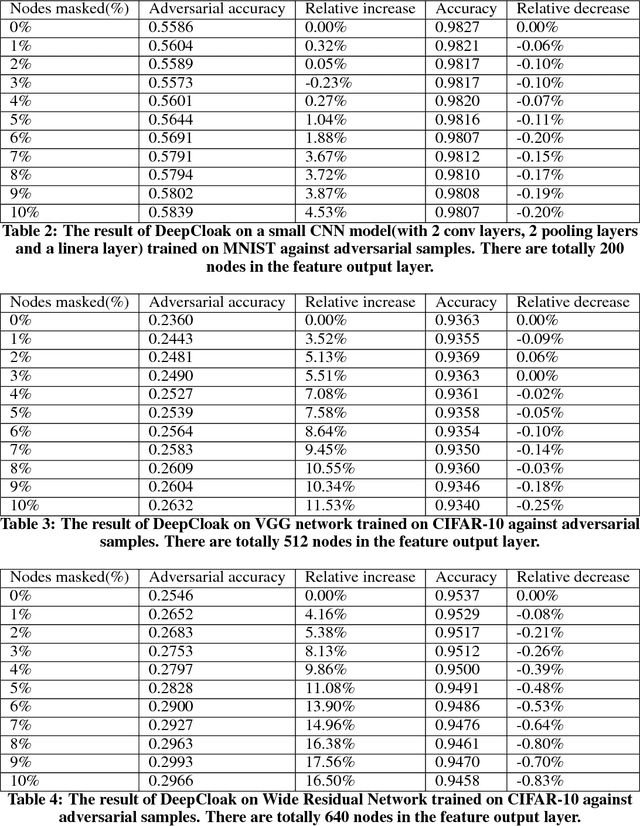
Recent studies have shown that deep neural networks (DNN) are vulnerable to adversarial samples: maliciously-perturbed samples crafted to yield incorrect model outputs. Such attacks can severely undermine DNN systems, particularly in security-sensitive settings. It was observed that an adversary could easily generate adversarial samples by making a small perturbation on irrelevant feature dimensions that are unnecessary for the current classification task. To overcome this problem, we introduce a defensive mechanism called DeepCloak. By identifying and removing unnecessary features in a DNN model, DeepCloak limits the capacity an attacker can use generating adversarial samples and therefore increase the robustness against such inputs. Comparing with other defensive approaches, DeepCloak is easy to implement and computationally efficient. Experimental results show that DeepCloak can increase the performance of state-of-the-art DNN models against adversarial samples.
Episodic Exploration for Deep Deterministic Policies: An Application to StarCraft Micromanagement Tasks
Nov 26, 2016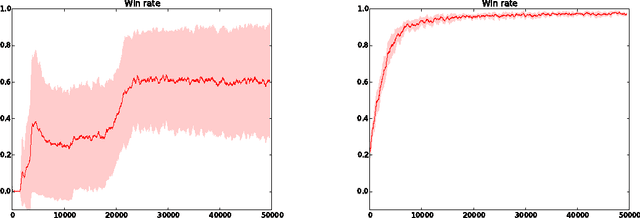


We consider scenarios from the real-time strategy game StarCraft as new benchmarks for reinforcement learning algorithms. We propose micromanagement tasks, which present the problem of the short-term, low-level control of army members during a battle. From a reinforcement learning point of view, these scenarios are challenging because the state-action space is very large, and because there is no obvious feature representation for the state-action evaluation function. We describe our approach to tackle the micromanagement scenarios with deep neural network controllers from raw state features given by the game engine. In addition, we present a heuristic reinforcement learning algorithm which combines direct exploration in the policy space and backpropagation. This algorithm allows for the collection of traces for learning using deterministic policies, which appears much more efficient than, for example, {\epsilon}-greedy exploration. Experiments show that with this algorithm, we successfully learn non-trivial strategies for scenarios with armies of up to 15 agents, where both Q-learning and REINFORCE struggle.
TorchCraft: a Library for Machine Learning Research on Real-Time Strategy Games
Nov 03, 2016
We present TorchCraft, a library that enables deep learning research on Real-Time Strategy (RTS) games such as StarCraft: Brood War, by making it easier to control these games from a machine learning framework, here Torch. This white paper argues for using RTS games as a benchmark for AI research, and describes the design and components of TorchCraft.
Deep Motif: Visualizing Genomic Sequence Classifications
Jun 02, 2016

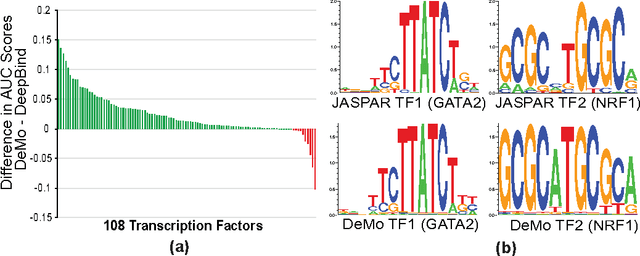
This paper applies a deep convolutional/highway MLP framework to classify genomic sequences on the transcription factor binding site task. To make the model understandable, we propose an optimization driven strategy to extract "motifs", or symbolic patterns which visualize the positive class learned by the network. We show that our system, Deep Motif (DeMo), extracts motifs that are similar to, and in some cases outperform the current well known motifs. In addition, we find that a deeper model consisting of multiple convolutional and highway layers can outperform a single convolutional and fully connected layer in the previous state-of-the-art.