 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Reinforcement Learning support policy makers? A preliminary study with Integrated Assessment Models
Dec 11, 2023Governments around the world aspire to ground decision-making on evidence. Many of the foundations of policy making - e.g. sensing patterns that relate to societal needs, developing evidence-based programs, forecasting potential outcomes of policy changes, and monitoring effectiveness of policy programs - have the potential to benefit from the use of large-scale datasets or simulations together with intelligent algorithms. These could, if designed and deployed in a way that is well grounded on scientific evidence, enable a more comprehensive, faster, and rigorous approach to policy making. Integrated Assessment Models (IAM) is a broad umbrella covering scientific models that attempt to link main features of society and economy with the biosphere into one modelling framework. At present, these systems are probed by policy makers and advisory groups in a hypothesis-driven manner. In this paper, we empirically demonstrate that modern Reinforcement Learning can be used to probe IAMs and explore the space of solutions in a more principled manner. While the implication of our results are modest since the environment is simplistic, we believe that this is a stepping stone towards more ambitious use cases, which could allow for effective exploration of policies and understanding of their consequences and limitations.
Insights From the NeurIPS 2021 NetHack Challenge
Mar 22, 2022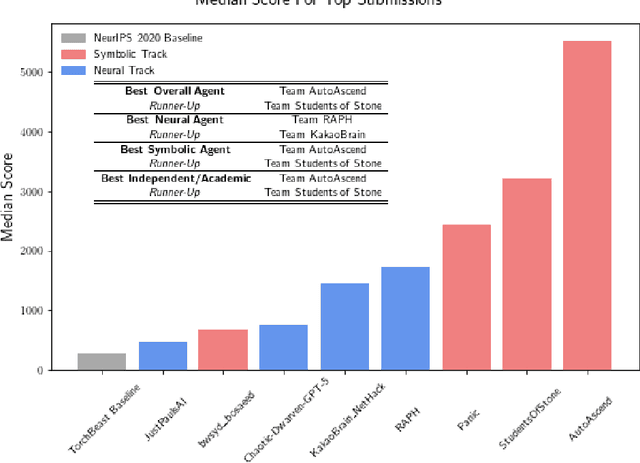

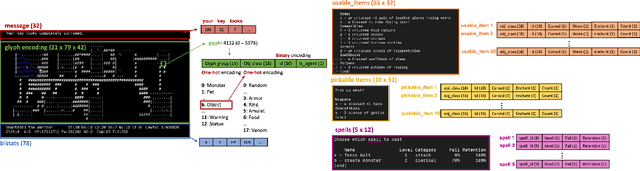
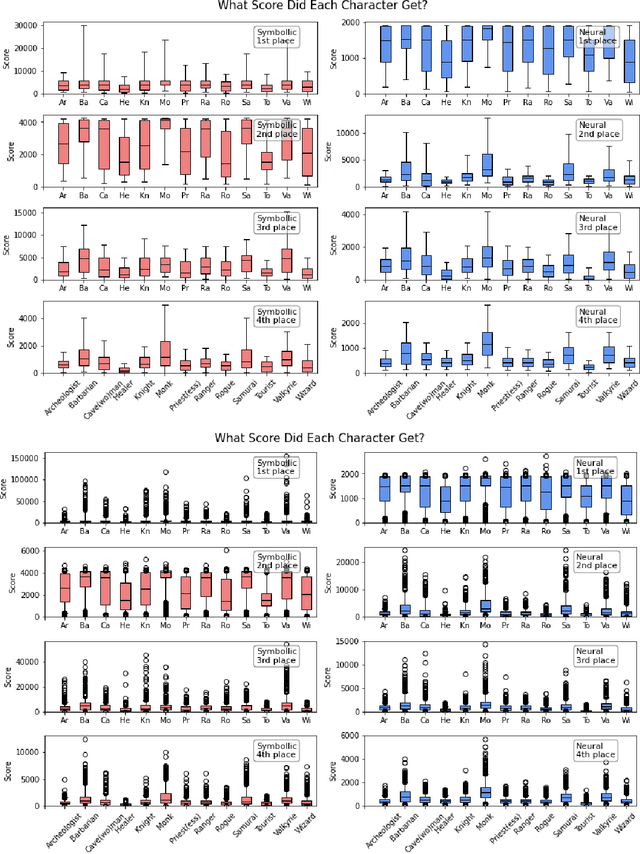
In this report, we summarize the takeaways from the first NeurIPS 2021 NetHack Challenge. Participants were tasked with developing a program or agent that can win (i.e., 'ascend' in) the popular dungeon-crawler game of NetHack by interacting with the NetHack Learning Environment (NLE), a scalable, procedurally generated, and challenging Gym environment for reinforcement learning (RL). The challenge showcased community-driven progress in AI with many diverse approaches significantly beating the previously best results on NetHack. Furthermore, it served as a direct comparison between neural (e.g., deep RL) and symbolic AI, as well as hybrid systems, demonstrating that on NetHack symbolic bots currently outperform deep RL by a large margin. Lastly, no agent got close to winning the game, illustrating NetHack's suitability as a long-term benchmark for AI research.
WordCraft: An Environment for Benchmarking Commonsense Agents
Jul 17, 2020



The ability to quickly solve a wide range of real-world tasks requires a commonsense understanding of the world. Yet, how to best extract such knowledge from natural language corpora and integrate it with reinforcement learning (RL) agents remains an open challenge. This is partly due to the lack of lightweight simulation environments that sufficiently reflect the semantics of the real world and provide knowledge sources grounded with respect to observations in an RL environment. To better enable research on agents making use of commonsense knowledge, we propose WordCraft, an RL environment based on Little Alchemy 2. This lightweight environment is fast to run and built upon entities and relations inspired by real-world semantics. We evaluate several representation learning methods on this new benchmark and propose a new method for integrating knowledge graphs with an RL agent.
The NetHack Learning Environment
Jun 24, 2020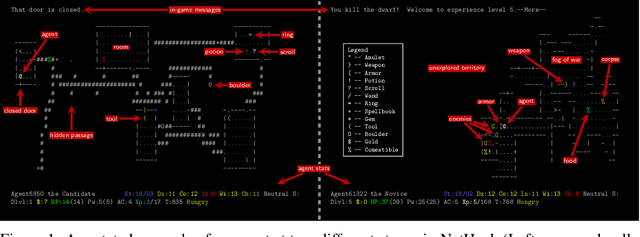
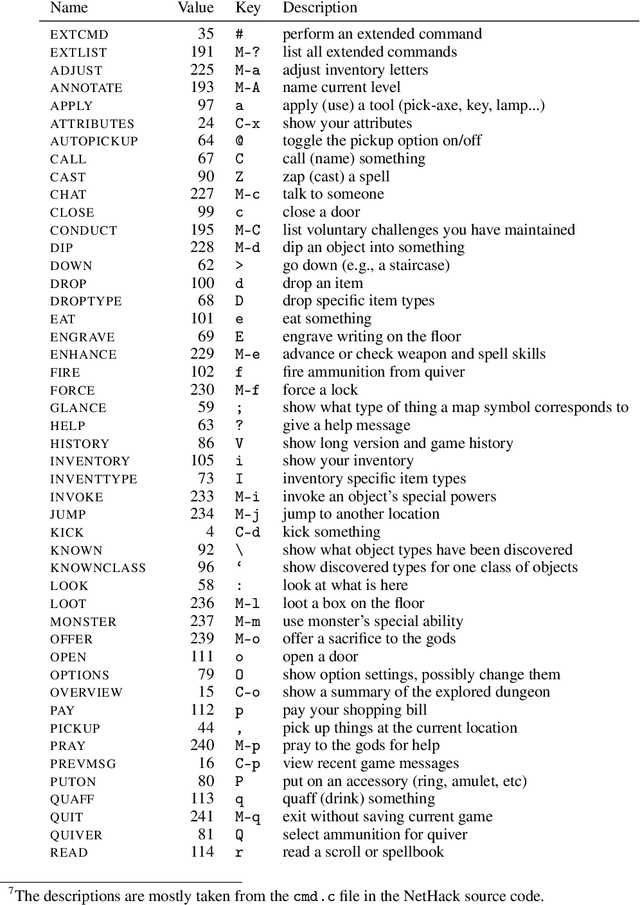
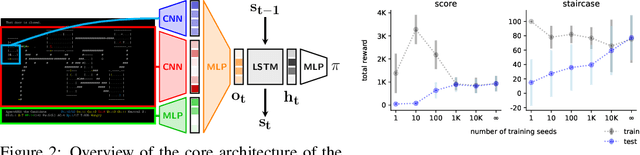
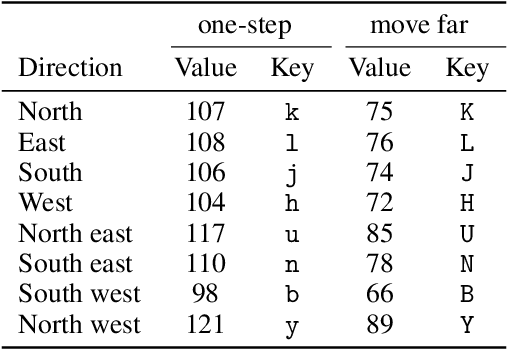
Progress in Reinforcement Learning (RL) algorithms goes hand-in-hand with the development of challenging environments that test the limits of current methods. While existing RL environments are either sufficiently complex or based on fast simulation, they are rarely both. Here, we present the NetHack Learning Environment (NLE), a scalable, procedurally generated, stochastic, rich, and challenging environment for RL research based on the popular single-player terminal-based roguelike game, NetHack. We argue that NetHack is sufficiently complex to drive long-term research on problems such as exploration, planning, skill acquisition, and language-conditioned RL, while dramatically reducing the computational resources required to gather a large amount of experience. We compare NLE and its task suite to existing alternatives, and discuss why it is an ideal medium for testing the robustness and systematic generalization of RL agents. We demonstrate empirical success for early stages of the game using a distributed Deep RL baseline and Random Network Distillation exploration, alongside qualitative analysis of various agents trained in the environment. NLE is open source at https://github.com/facebookresearch/nle.
Simulation-Based Inference for Global Health Decisions
May 14, 2020
The COVID-19 pandemic has highlighted the importance of in-silico epidemiological modelling in predicting the dynamics of infectious diseases to inform health policy and decision makers about suitable prevention and containment strategies. Work in this setting involves solving challenging inference and control problems in individual-based models of ever increasing complexity. Here we discuss recent breakthroughs in machine learning, specifically in simulation-based inference, and explore its potential as a novel venue for model calibration to support the design and evaluation of public health interventions. To further stimulate research, we are developing software interfaces that turn two cornerstone COVID-19 and malaria epidemiology models COVID-sim, (https://github.com/mrc-ide/covid-sim/) and OpenMalaria (https://github.com/SwissTPH/openmalaria) into probabilistic programs, enabling efficient interpretable Bayesian inference within those simulators.
Lessons from reinforcement learning for biological representations of space
Dec 13, 2019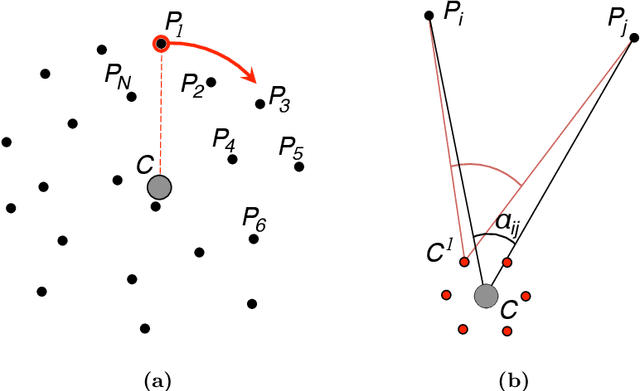

Neuroscientists postulate 3D representations in the brain in a variety of different coordinate frames (e.g. 'head-centred', 'hand-centred' and 'world-based'). Recent advances in reinforcement learning demonstrate a quite different approach that may provide a more promising model for biological representations underlying spatial perception and navigation. In this paper, we focus on reinforcement learning methods that reward an agent for arriving at a target image without any attempt to build up a 3D 'map'. We test the ability of this type of representation to support geometrically consistent spatial tasks, such as interpolating between learned locations, and compare its performance to that of a hand-crafted representation which has, by design, a high degree of geometric consistency. Our comparison of these two models demonstrates that it is advantageous to include information about the persistence of features as the camera translates (e.g. distant features persist). It is likely that non-Cartesian representations of this sort will be increasingly important in the search for robust models of human spatial perception and navigation.
MVFST-RL: An Asynchronous RL Framework for Congestion Control with Delayed Actions
Oct 30, 2019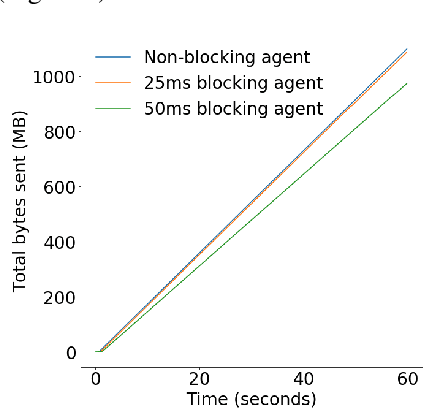
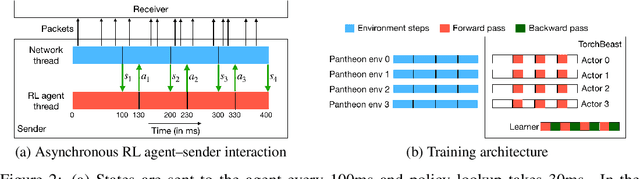
Effective network congestion control strategies are key to keeping the Internet (or any large computer network) operational. Network congestion control has been dominated by hand-crafted heuristics for decades. Recently, ReinforcementLearning (RL) has emerged as an alternative to automatically optimize such control strategies. Research so far has primarily considered RL interfaces which block the sender while an agent considers its next action. This is largely an artifact of building on top of frameworks designed for RL in games (e.g. OpenAI Gym). However, this does not translate to real-world networking environments, where a network sender waiting on a policy without sending data leads to under-utilization of bandwidth. We instead propose to formulate congestion control with an asynchronous RL agent that handles delayed actions. We present MVFST-RL, a scalable framework for congestion control in the QUIC transport protocol that leverages state-of-the-art in asynchronous RL training with off-policy correction. We analyze modeling improvements to mitigate the deviation from Markovian dynamics, and evaluate our method on emulated networks from the Pantheon benchmark platform. The source code is publicly available at https://github.com/facebookresearch/mvfst-rl.
TorchBeast: A PyTorch Platform for Distributed RL
Oct 08, 2019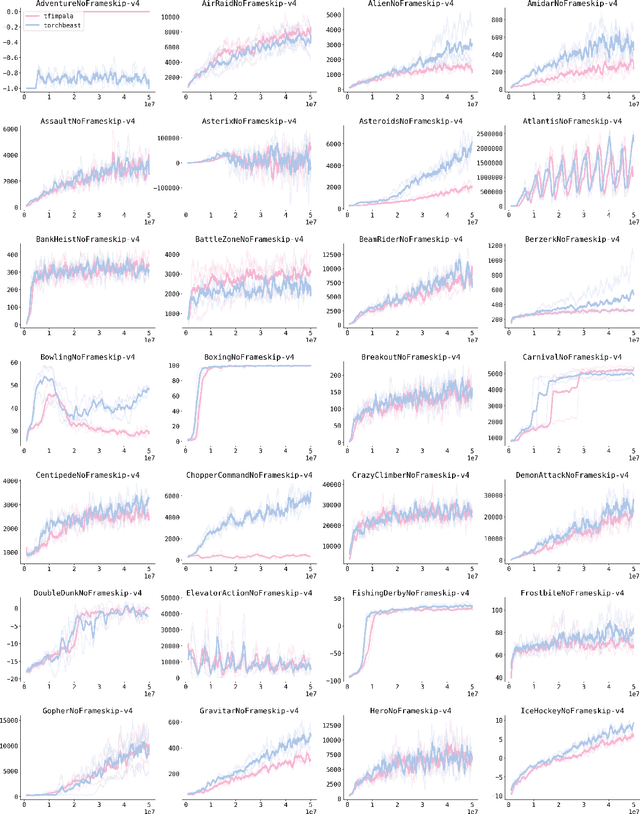
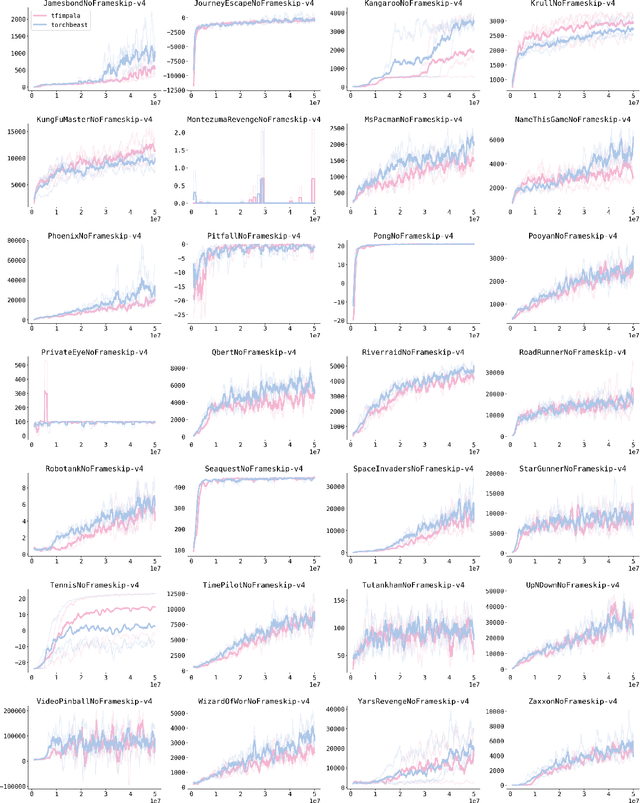
TorchBeast is a platform for reinforcement learning (RL) research in PyTorch. It implements a version of the popular IMPALA algorithm for fast, asynchronous, parallel training of RL agents. Additionally, TorchBeast has simplicity as an explicit design goal: We provide both a pure-Python implementation ("MonoBeast") as well as a multi-machine high-performance version ("PolyBeast"). In the latter, parts of the implementation are written in C++, but all parts pertaining to machine learning are kept in simple Python using PyTorch, with the environments provided using the OpenAI Gym interface. This enables researchers to conduct scalable RL research using TorchBeast without any programming knowledge beyond Python and PyTorch. In this paper, we describe the TorchBeast design principles and implementation and demonstrate that it performs on-par with IMPALA on Atari. TorchBeast is released as an open-source package under the Apache 2.0 license and is available at \url{https://github.com/facebookresearch/torchbeast}.
A Survey of Reinforcement Learning Informed by Natural Language
Jun 10, 2019
To be successful in real-world tasks, Reinforcement Learning (RL) needs to exploit the compositional, relational, and hierarchical structure of the world, and learn to transfer it to the task at hand. Recent advances in representation learning for language make it possible to build models that acquire world knowledge from text corpora and integrate this knowledge into downstream decision making problems. We thus argue that the time is right to investigate a tight integration of natural language understanding into RL in particular. We survey the state of the field, including work on instruction following, text games, and learning from textual domain knowledge. Finally, we call for the development of new environments as well as further investigation into the potential uses of recent Natural Language Processing (NLP) techniques for such tasks.
Multitask Soft Option Learning
Apr 01, 2019
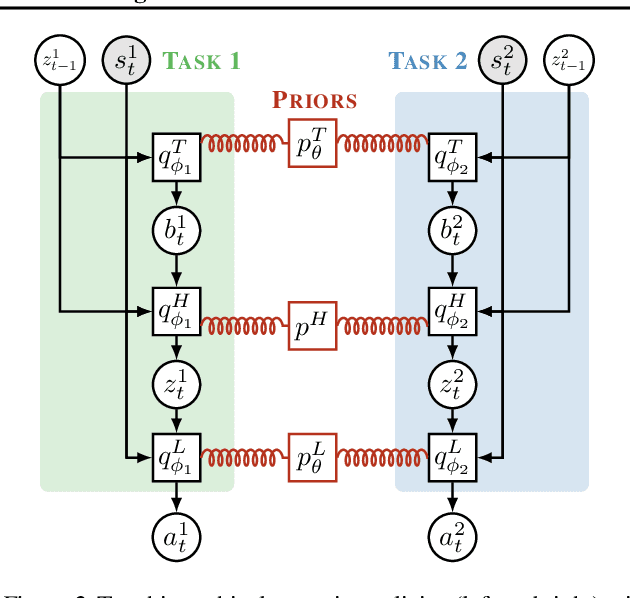


We present Multitask Soft Option Learning (MSOL), a hierarchical multitask framework based on Planning as Inference. MSOL extends the concept of options, using separate variational posteriors for each task, regularized by a shared prior. This allows fine-tuning of options for new tasks without forgetting their learned policies, leading to faster training without reducing the expressiveness of the hierarchical policy. Additionally, MSOL avoids several instabilities during training in a multitask setting and provides a natural way to not only learn intra-option policies, but also their terminations. We demonstrate empirically that MSOL significantly outperforms both hierarchical and flat transfer-learning baselines in challenging multi-task environments.