 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Continual Learning Without the Storage Constraint
May 16, 2023



Online continual learning (OCL) research has primarily focused on mitigating catastrophic forgetting with fixed and limited storage allocation throughout the agent's lifetime. However, the growing affordability of data storage highlights a broad range of applications that do not adhere to these assumptions. In these cases, the primary concern lies in managing computational expenditures rather than storage. In this paper, we target such settings, investigating the online continual learning problem by relaxing storage constraints and emphasizing fixed, limited economical budget. We provide a simple algorithm that can compactly store and utilize the entirety of the incoming data stream under tiny computational budgets using a kNN classifier and universal pre-trained feature extractors. Our algorithm provides a consistency property attractive to continual learning: It will never forget past seen data. We set a new state of the art on two large-scale OCL datasets: Continual LOCalization (CLOC), which has 39M images over 712 classes, and Continual Google Landmarks V2 (CGLM), which has 580K images over 10,788 classes -- beating methods under far higher computational budgets than ours in terms of both reducing catastrophic forgetting of past data and quickly adapting to rapidly changing data streams. We provide code to reproduce our results at \url{https://github.com/drimpossible/ACM}.
Computationally Budgeted Continual Learning: What Does Matter?
Mar 20, 2023Continual Learning (CL) aims to sequentially train models on streams of incoming data that vary in distribution by preserving previous knowledge while adapting to new data. Current CL literature focuses on restricted access to previously seen data, while imposing no constraints on the computational budget for training. This is unreasonable for applications in-the-wild, where systems are primarily constrained by computational and time budgets, not storage. We revisit this problem with a large-scale benchmark and analyze the performance of traditional CL approaches in a compute-constrained setting, where effective memory samples used in training can be implicitly restricted as a consequence of limited computation. We conduct experiments evaluating various CL sampling strategies, distillation losses, and partial fine-tuning on two large-scale datasets, namely ImageNet2K and Continual Google Landmarks V2 in data incremental, class incremental, and time incremental settings. Through extensive experiments amounting to a total of over 1500 GPU-hours, we find that, under compute-constrained setting, traditional CL approaches, with no exception, fail to outperform a simple minimal baseline that samples uniformly from memory. Our conclusions are consistent in a different number of stream time steps, e.g., 20 to 200, and under several computational budgets. This suggests that most existing CL methods are particularly too computationally expensive for realistic budgeted deployment. Code for this project is available at: https://github.com/drimpossible/BudgetCL.
Multilevel Knowledge Transfer for Cross-Domain Object Detection
Aug 03, 2021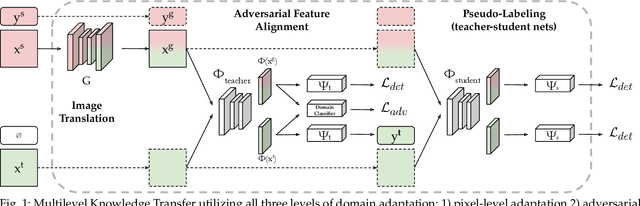
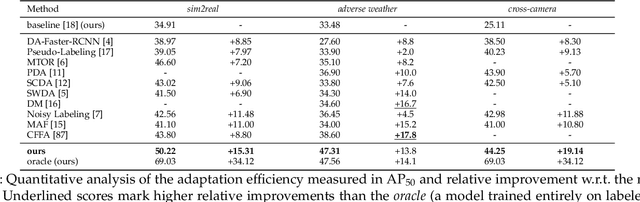
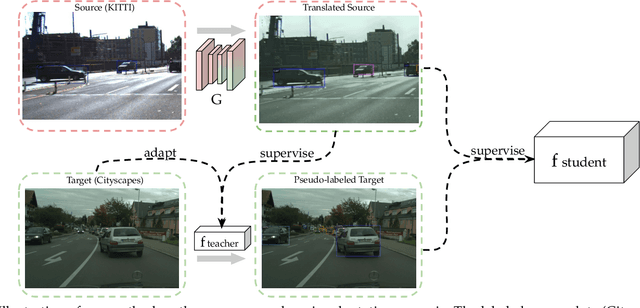
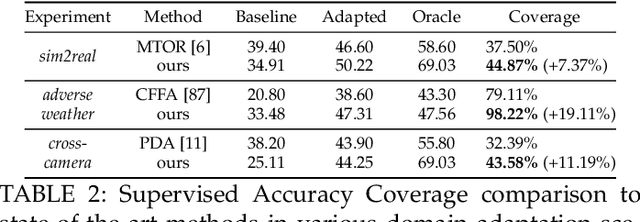
Domain shift is a well known problem where a model trained on a particular domain (source) does not perform well when exposed to samples from a different domain (target). Unsupervised methods that can adapt to domain shift are highly desirable as they allow effective utilization of the source data without requiring additional annotated training data from the target. Practically, obtaining sufficient amount of annotated data from the target domain can be both infeasible and extremely expensive. In this work, we address the domain shift problem for the object detection task. Our approach relies on gradually removing the domain shift between the source and the target domains. The key ingredients to our approach are -- (a) mapping the source to the target domain on pixel-level; (b) training a teacher network on the mapped source and the unannotated target domain using adversarial feature alignment; and (c) finally training a student network using the pseudo-labels obtained from the teacher. Experimentally, when tested on challenging scenarios involving domain shift, we consistently obtain significantly large performance gains over various recent state of the art approaches.
Simulation-Based Inference for Global Health Decisions
May 14, 2020
The COVID-19 pandemic has highlighted the importance of in-silico epidemiological modelling in predicting the dynamics of infectious diseases to inform health policy and decision makers about suitable prevention and containment strategies. Work in this setting involves solving challenging inference and control problems in individual-based models of ever increasing complexity. Here we discuss recent breakthroughs in machine learning, specifically in simulation-based inference, and explore its potential as a novel venue for model calibration to support the design and evaluation of public health interventions. To further stimulate research, we are developing software interfaces that turn two cornerstone COVID-19 and malaria epidemiology models COVID-sim, (https://github.com/mrc-ide/covid-sim/) and OpenMalaria (https://github.com/SwissTPH/openmalaria) into probabilistic programs, enabling efficient interpretable Bayesian inference within those simulators.