 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation-Based Inference for Global Health Decisions
May 14, 2020
The COVID-19 pandemic has highlighted the importance of in-silico epidemiological modelling in predicting the dynamics of infectious diseases to inform health policy and decision makers about suitable prevention and containment strategies. Work in this setting involves solving challenging inference and control problems in individual-based models of ever increasing complexity. Here we discuss recent breakthroughs in machine learning, specifically in simulation-based inference, and explore its potential as a novel venue for model calibration to support the design and evaluation of public health interventions. To further stimulate research, we are developing software interfaces that turn two cornerstone COVID-19 and malaria epidemiology models COVID-sim, (https://github.com/mrc-ide/covid-sim/) and OpenMalaria (https://github.com/SwissTPH/openmalaria) into probabilistic programs, enabling efficient interpretable Bayesian inference within those simulators.
Amortized Rejection Sampling in Universal Probabilistic Programming
Nov 30, 2019
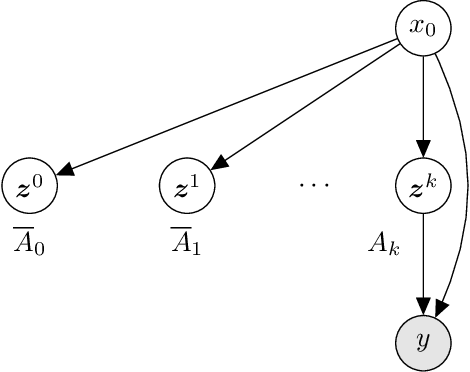
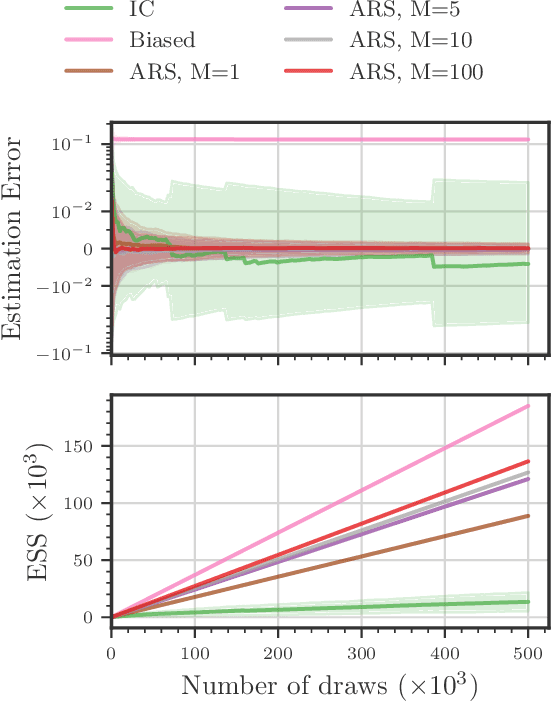
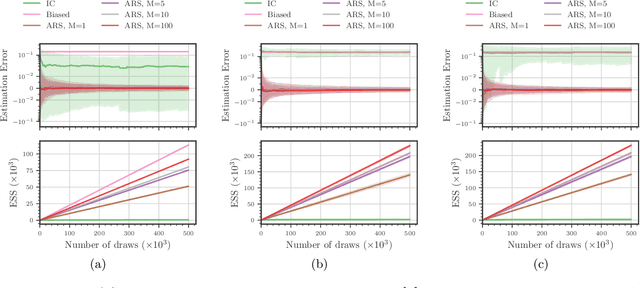
Existing approaches to amortized inference in probabilistic programs with unbounded loops can produce estimators with infinite variance. An instance of this is importance sampling inference in programs that explicitly include rejection sampling as part of the user-programmed generative procedure. In this paper we develop a new and efficient amortized importance sampling estimator. We prove finite variance of our estimator and empirically demonstrate our method's correctness and efficiency compared to existing alternatives on generative programs containing rejection sampling loops and discuss how to implement our method in a generic probabilistic programming framework.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019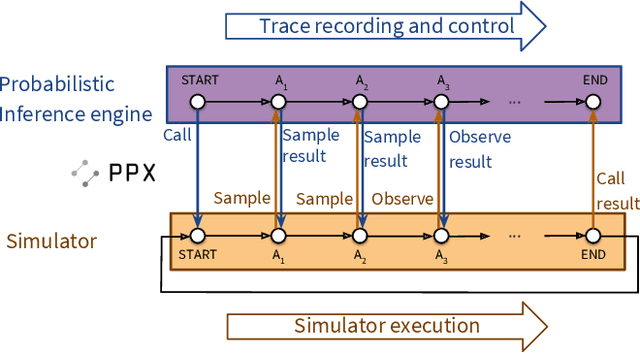

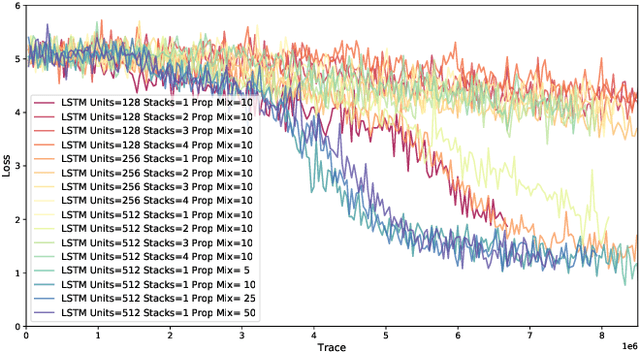
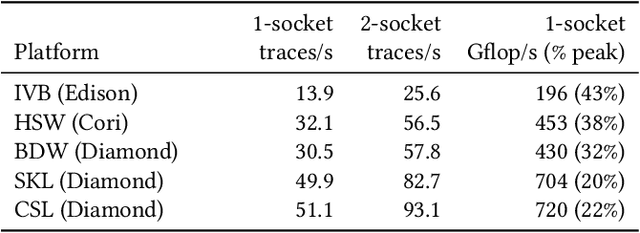
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
Hijacking Malaria Simulators with Probabilistic Programming
May 29, 2019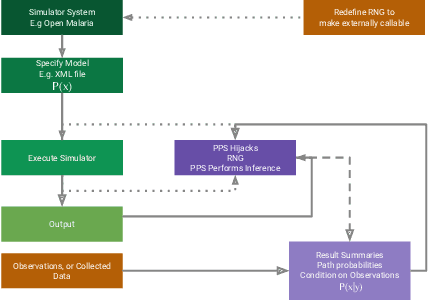
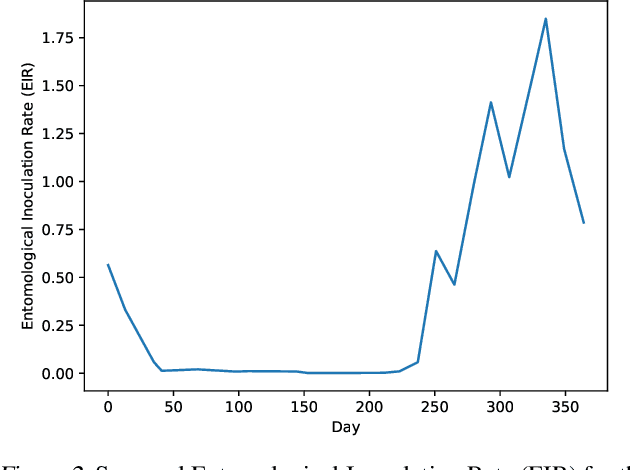

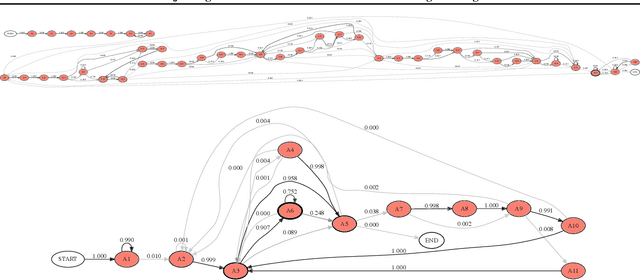
Epidemiology simulations have become a fundamental tool in the fight against the epidemics of various infectious diseases like AIDS and malaria. However, the complicated and stochastic nature of these simulators can mean their output is difficult to interpret, which reduces their usefulness to policymakers. In this paper, we introduce an approach that allows one to treat a large class of population-based epidemiology simulators as probabilistic generative models. This is achieved by hijacking the internal random number generator calls, through the use of a universal probabilistic programming system (PPS). In contrast to other methods, our approach can be easily retrofitted to simulators written in popular industrial programming frameworks. We demonstrate that our method can be used for interpretable introspection and inference, thus shedding light on black-box simulators. This reinstates much-needed trust between policymakers and evidence-based methods.
* 6 pages, 3 figures, Accepted at the International Conference on Machine Learning AI for Social Good Workshop, Long Beach, United States, 2019
Mapping Informal Settlements in Developing Countries using Machine Learning and Low Resolution Multi-spectral Data
Jan 03, 2019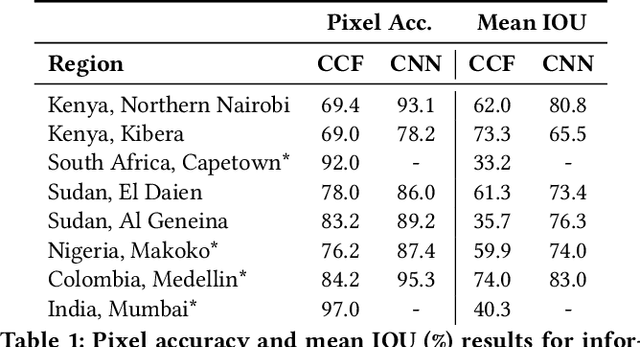


Informal settlements are home to the most socially and economically vulnerable people on the planet. In order to deliver effective economic and social aid, non-government organizations (NGOs), such as the United Nations Children's Fund (UNICEF), require detailed maps of the locations of informal settlements. However, data regarding informal and formal settlements is primarily unavailable and if available is often incomplete. This is due, in part, to the cost and complexity of gathering data on a large scale. An additional complication is that the definition of an informal settlement is also very broad, which makes it a non-trivial task to collect data. This also makes it challenging to teach a machine what to look for. Due to these challenges we provide three contributions in this work. 1) A brand new machine learning data-set, purposely developed for informal settlement detection that contains a series of low and very-high resolution imagery, with accompanying ground truth annotations marking the locations of known informal settlements. 2) We demonstrate that it is possible to detect informal settlements using freely available low-resolution (LR) data, in contrast to previous studies that use very-high resolution (VHR) satellite and aerial imagery, which is typically cost-prohibitive for NGOs. 3) We demonstrate two effective classification schemes on our curated data set, one that is cost-efficient for NGOs and another that is cost-prohibitive for NGOs, but has additional utility. We integrate these schemes into a semi-automated pipeline that converts either a LR or VHR satellite image into a binary map that encodes the locations of informal settlements. We evaluate and compare our methods.
Mapping Informal Settlements in Developing Countries with Multi-resolution, Multi-spectral Data
Nov 30, 2018
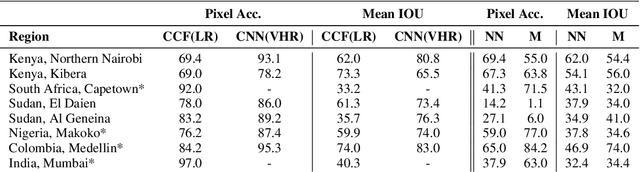


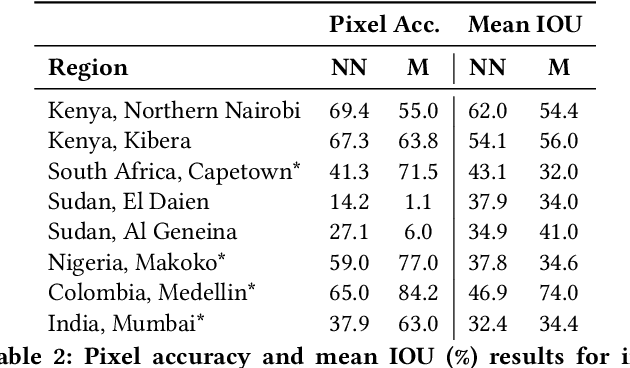
Detecting and mapping informal settlements encompasses several of the United Nations sustainable development goals. This is because informal settlements are home to the most socially and economically vulnerable people on the planet. Thus, understanding where these settlements are is of paramount importance to both government and non-government organizations (NGOs), such as the United Nations Children's Fund (UNICEF), who can use this information to deliver effective social and economic aid. We propose two effective methods for detecting and mapping the locations of informal settlements. One uses only low-resolution (LR), freely available, Sentinel-2 multispectral satellite imagery with noisy annotations, whilst the other is a deep learning approach that uses only costly very-high-resolution (VHR) satellite imagery. To our knowledge, we are the first to map informal settlements successfully with low-resolution satellite imagery. We extensively evaluate and compare the proposed methods. Please find additional material at https://frontierdevelopmentlab.github.io/informal-settlements/.
Generating Material Maps to Map Informal Settlements
Nov 30, 2018

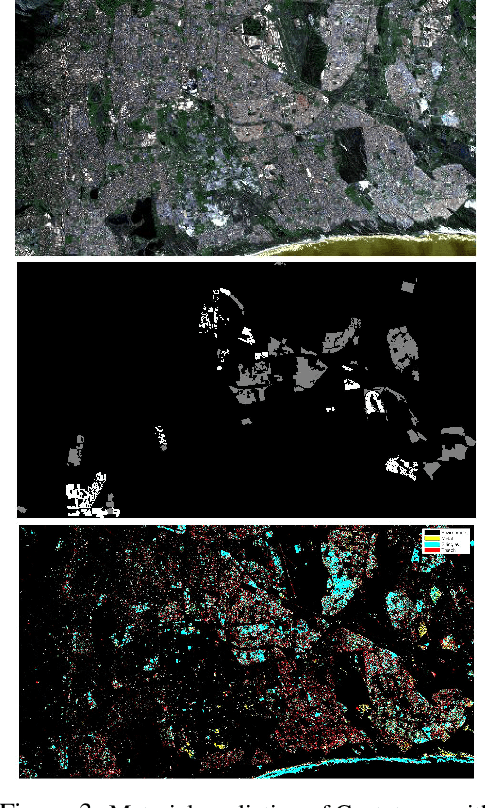
Detecting and mapping informal settlements encompasses several of the United Nations sustainable development goals. This is because informal settlements are home to the most socially and economically vulnerable people on the planet. Thus, understanding where these settlements are is of paramount importance to both government and non-government organizations (NGOs), such as the United Nations Children's Fund (UNICEF), who can use this information to deliver effective social and economic aid. We propose a method that detects and maps the locations of informal settlements using only freely available, Sentinel-2 low-resolution satellite spectral data and socio-economic data. This is in contrast to previous studies that only use costly very-high resolution (VHR) satellite and aerial imagery. We show how we can detect informal settlements by combining both domain knowledge and machine learning techniques, to build a classifier that looks for known roofing materials used in informal settlements. Please find additional material at https://frontierdevelopmentlab.github.io/informal-settlements/.
Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model
Sep 01, 2018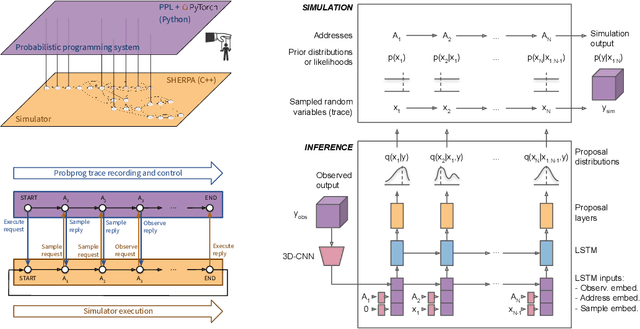
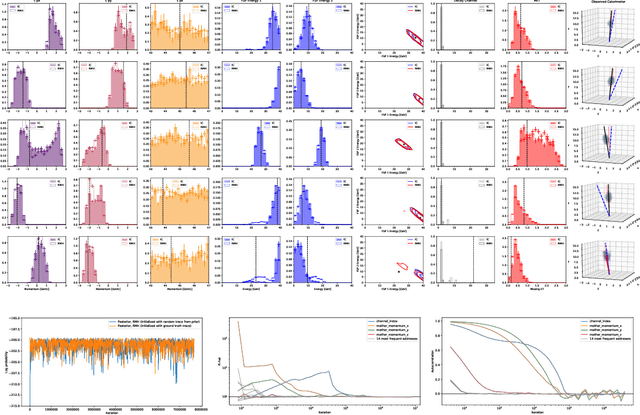


We present a novel framework that enables efficient probabilistic inference in large-scale scientific models by allowing the execution of existing domain-specific simulators as probabilistic programs, resulting in highly interpretable posterior inference. Our framework is general purpose and scalable, and is based on a cross-platform probabilistic execution protocol through which an inference engine can control simulators in a language-agnostic way. We demonstrate the technique in particle physics, on a scientifically accurate simulation of the tau lepton decay, which is a key ingredient in establishing the properties of the Higgs boson. High-energy physics has a rich set of simulators based on quantum field theory and the interaction of particles in matter. We show how to use probabilistic programming to perform Bayesian inference in these existing simulator codebases directly, in particular conditioning on observable outputs from a simulated particle detector to directly produce an interpretable posterior distribution over decay pathways. Inference efficiency is achieved via inference compilation where a deep recurrent neural network is trained to parameterize proposal distributions and control the stochastic simulator in a sequential importance sampling scheme, at a fraction of the computational cost of Markov chain Monte Carlo sampling.
Discontinuous Hamiltonian Monte Carlo for Probabilistic Programs
Apr 07, 2018
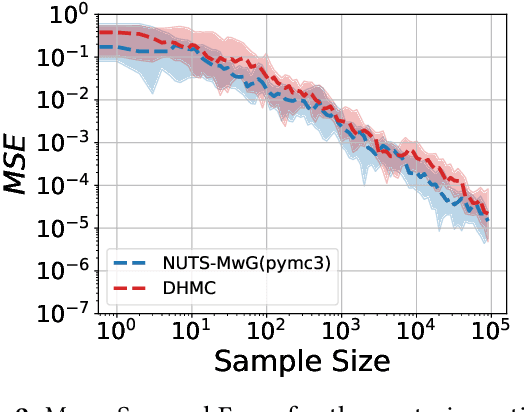
Hamiltonian Monte Carlo (HMC) is the dominant statistical inference algorithm used in most popular first-order differentiable probabilistic programming languages. HMC requires that the joint density be differentiable with respect to all latent variables. This complicates expressing some models in such languages and prohibits others. A recently proposed new integrator for HMC yielded a new Discontinuous HMC (DHMC) algorithm that can be used for inference in models with joint densities that have discontinuities. In this paper we show how to use DHMC for inference in probabilistic programs. To do this we introduce a sufficient set of language restrictions, a corresponding mathematical formalism that ensures that any joint density denoted in such a language has a suitably low measure of discontinuous points, and a recipe for how to apply DHMC in the more general probabilistic-programming context. Our experimental findings demonstrate the correctness of this approach.