 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Cataract Fundus Image Restoration Model Utilizing Unpaired Cataract and High-quality Images
Nov 19, 2024



Cataract is one of the most common blinding eye diseases and can be treated by surgery. However, because cataract patients may also suffer from other blinding eye diseases, ophthalmologists must diagnose them before surgery. The cloudy lens of cataract patients forms a hazy degeneration in the fundus images, making it challenging to observe the patient's fundus vessels, which brings difficulties to the diagnosis process. To address this issue, this paper establishes a new cataract image restoration method named Catintell. It contains a cataract image synthesizing model, Catintell-Syn, and a restoration model, Catintell-Res. Catintell-Syn uses GAN architecture with fully unsupervised data to generate paired cataract-like images with realistic style and texture rather than the conventional Gaussian degradation algorithm. Meanwhile, Catintell-Res is an image restoration network that can improve the quality of real cataract fundus images using the knowledge learned from synthetic cataract images. Extensive experiments show that Catintell-Res outperforms other cataract image restoration methods in PSNR with 39.03 and SSIM with 0.9476. Furthermore, the universal restoration ability that Catintell-Res gained from unpaired cataract images can process cataract images from various datasets. We hope the models can help ophthalmologists identify other blinding eye diseases of cataract patients and inspire more medical image restoration methods in the future.
Microscaling Data Formats for Deep Learning
Oct 19, 2023



Narrow bit-width data formats are key to reducing the computational and storage costs of modern deep learning applications. This paper evaluates Microscaling (MX) data formats that combine a per-block scaling factor with narrow floating-point and integer types for individual elements. MX formats balance the competing needs of hardware efficiency, model accuracy, and user friction. Empirical results on over two dozen benchmarks demonstrate practicality of MX data formats as a drop-in replacement for baseline FP32 for AI inference and training with low user friction. We also show the first instance of training generative language models at sub-8-bit weights, activations, and gradients with minimal accuracy loss and no modifications to the training recipe.
Shared Microexponents: A Little Shifting Goes a Long Way
Feb 16, 2023



This paper introduces Block Data Representations (BDR), a framework for exploring and evaluating a wide spectrum of narrow-precision formats for deep learning. It enables comparison of popular quantization standards, and through BDR, new formats based on shared microexponents (MX) are identified, which outperform other state-of-the-art quantization approaches, including narrow-precision floating-point and block floating-point. MX utilizes multiple levels of quantization scaling with ultra-fine scaling factors based on shared microexponents in the hardware. The effectiveness of MX is demonstrated on real-world models including large-scale generative pretraining and inferencing, and production-scale recommendation systems.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019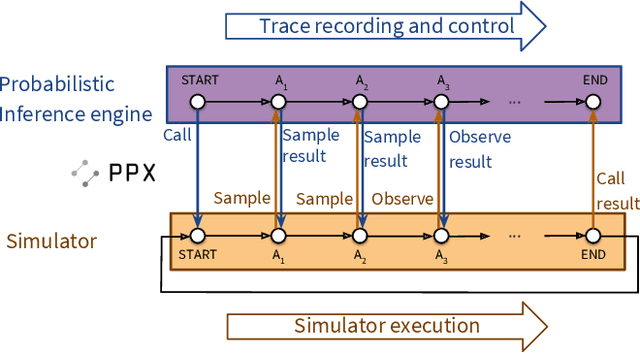

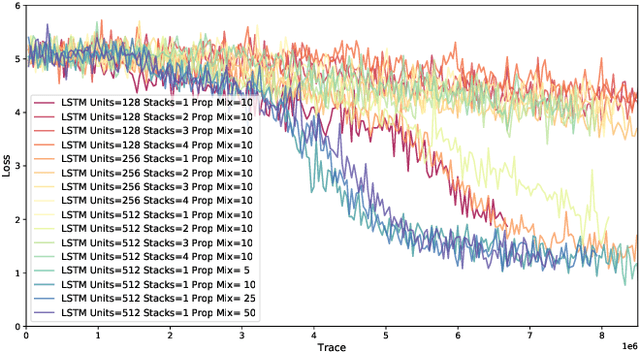
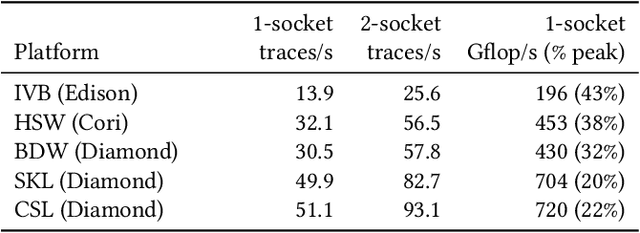
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
Efficient Probabilistic Inference in the Quest for Physics Beyond the Standard Model
Sep 01, 2018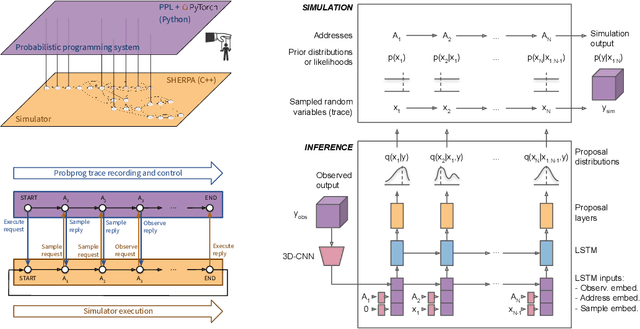
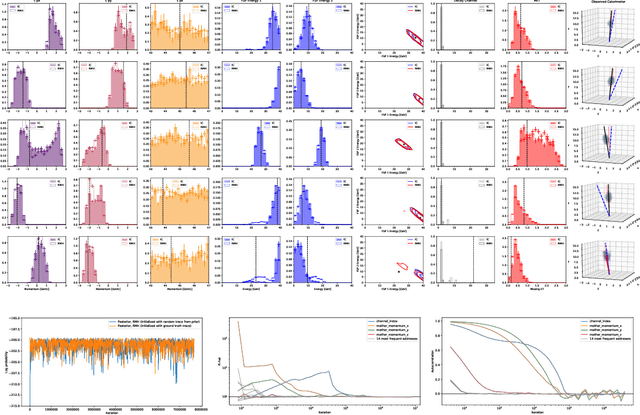


We present a novel framework that enables efficient probabilistic inference in large-scale scientific models by allowing the execution of existing domain-specific simulators as probabilistic programs, resulting in highly interpretable posterior inference. Our framework is general purpose and scalable, and is based on a cross-platform probabilistic execution protocol through which an inference engine can control simulators in a language-agnostic way. We demonstrate the technique in particle physics, on a scientifically accurate simulation of the tau lepton decay, which is a key ingredient in establishing the properties of the Higgs boson. High-energy physics has a rich set of simulators based on quantum field theory and the interaction of particles in matter. We show how to use probabilistic programming to perform Bayesian inference in these existing simulator codebases directly, in particular conditioning on observable outputs from a simulated particle detector to directly produce an interpretable posterior distribution over decay pathways. Inference efficiency is achieved via inference compilation where a deep recurrent neural network is trained to parameterize proposal distributions and control the stochastic simulator in a sequential importance sampling scheme, at a fraction of the computational cost of Markov chain Monte Carlo sampling.
CosmoFlow: Using Deep Learning to Learn the Universe at Scale
Aug 14, 2018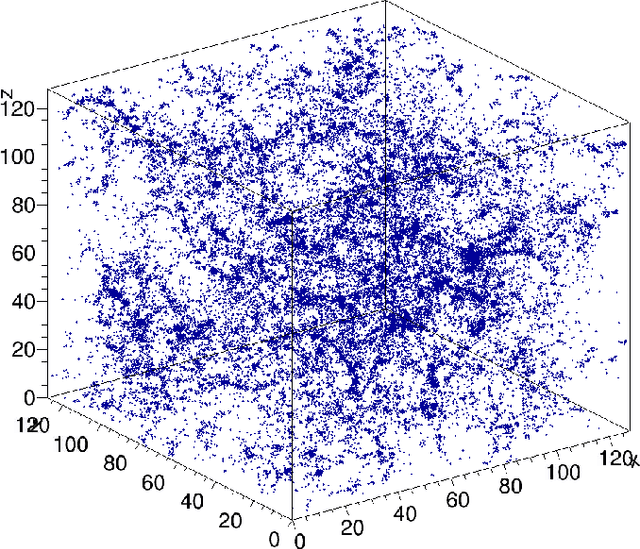
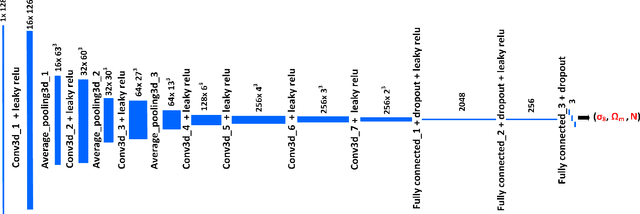
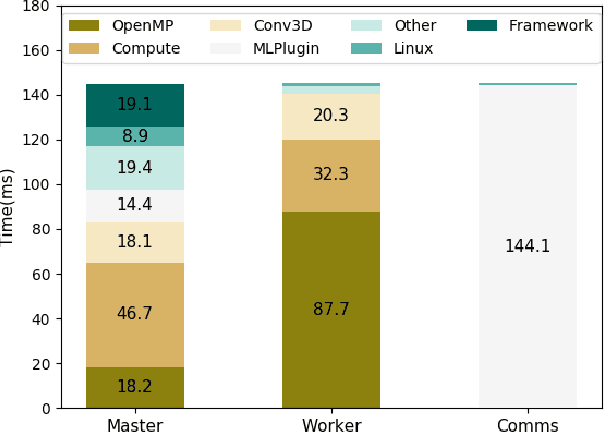
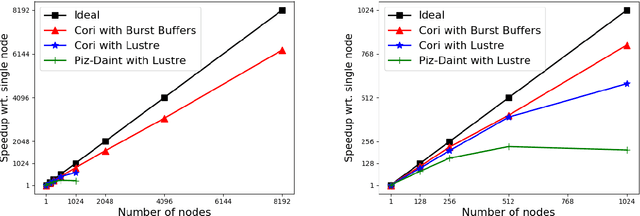
Deep learning is a promising tool to determine the physical model that describes our universe. To handle the considerable computational cost of this problem, we present CosmoFlow: a highly scalable deep learning application built on top of the TensorFlow framework. CosmoFlow uses efficient implementations of 3D convolution and pooling primitives, together with improvements in threading for many element-wise operations, to improve training performance on Intel(C) Xeon Phi(TM) processors. We also utilize the Cray PE Machine Learning Plugin for efficient scaling to multiple nodes. We demonstrate fully synchronous data-parallel training on 8192 nodes of Cori with 77% parallel efficiency, achieving 3.5 Pflop/s sustained performance. To our knowledge, this is the first large-scale science application of the TensorFlow framework at supercomputer scale with fully-synchronous training. These enhancements enable us to process large 3D dark matter distribution and predict the cosmological parameters $\Omega_M$, $\sigma_8$ and n$_s$ with unprecedented accuracy.