 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLAICraft: Large-Scale Time-Aligned Vision-Speech-Action Dataset for Embodied AI
May 19, 2025Advances in deep generative modelling have made it increasingly plausible to train human-level embodied agents. Yet progress has been limited by the absence of large-scale, real-time, multi-modal, and socially interactive datasets that reflect the sensory-motor complexity of natural environments. To address this, we present PLAICraft, a novel data collection platform and dataset capturing multiplayer Minecraft interactions across five time-aligned modalities: video, game output audio, microphone input audio, mouse, and keyboard actions. Each modality is logged with millisecond time precision, enabling the study of synchronous, embodied behaviour in a rich, open-ended world. The dataset comprises over 10,000 hours of gameplay from more than 10,000 global participants.\footnote{We have done a privacy review for the public release of an initial 200-hour subset of the dataset, with plans to release most of the dataset over time.} Alongside the dataset, we provide an evaluation suite for benchmarking model capabilities in object recognition, spatial awareness, language grounding, and long-term memory. PLAICraft opens a path toward training and evaluating agents that act fluently and purposefully in real time, paving the way for truly embodied artificial intelligence.
Constrained Generative Modeling with Manually Bridged Diffusion Models
Feb 27, 2025In this paper we describe a novel framework for diffusion-based generative modeling on constrained spaces. In particular, we introduce manual bridges, a framework that expands the kinds of constraints that can be practically used to form so-called diffusion bridges. We develop a mechanism for combining multiple such constraints so that the resulting multiply-constrained model remains a manual bridge that respects all constraints. We also develop a mechanism for training a diffusion model that respects such multiple constraints while also adapting it to match a data distribution. We develop and extend theory demonstrating the mathematical validity of our mechanisms. Additionally, we demonstrate our mechanism in constrained generative modeling tasks, highlighting a particular high-value application in modeling trajectory initializations for path planning and control in autonomous vehicles.
Rolling Ahead Diffusion for Traffic Scene Simulation
Feb 13, 2025



Realistic driving simulation requires that NPCs not only mimic natural driving behaviors but also react to the behavior of other simulated agents. Recent developments in diffusion-based scenario generation focus on creating diverse and realistic traffic scenarios by jointly modelling the motion of all the agents in the scene. However, these traffic scenarios do not react when the motion of agents deviates from their modelled trajectories. For example, the ego-agent can be controlled by a stand along motion planner. To produce reactive scenarios with joint scenario models, the model must regenerate the scenario at each timestep based on new observations in a Model Predictive Control (MPC) fashion. Although reactive, this method is time-consuming, as one complete possible future for all NPCs is generated per simulation step. Alternatively, one can utilize an autoregressive model (AR) to predict only the immediate next-step future for all NPCs. Although faster, this method lacks the capability for advanced planning. We present a rolling diffusion based traffic scene generation model which mixes the benefits of both methods by predicting the next step future and simultaneously predicting partially noised further future steps at the same time. We show that such model is efficient compared to diffusion model based AR, achieving a beneficial compromise between reactivity and computational efficiency.
Towards a Mechanistic Explanation of Diffusion Model Generalization
Nov 28, 2024We propose a mechanism for diffusion generalization based on local denoising operations. Through analysis of network and empirical denoisers, we identify local inductive biases in diffusion models. We demonstrate that local denoising operations can be used to approximate the optimal diffusion denoiser. Using a collection of patch-based, local empirical denoisers, we construct a denoiser which approximates the generalization behaviour of diffusion model denoisers over forward and reverse diffusion processes.
Prospective Messaging: Learning in Networks with Communication Delays
Jul 09, 2024Inter-neuron communication delays are ubiquitous in physically realized neural networks such as biological neural circuits and neuromorphic hardware. These delays have significant and often disruptive consequences on network dynamics during training and inference. It is therefore essential that communication delays be accounted for, both in computational models of biological neural networks and in large-scale neuromorphic systems. Nonetheless, communication delays have yet to be comprehensively addressed in either domain. In this paper, we first show that delays prevent state-of-the-art continuous-time neural networks called Latent Equilibrium (LE) networks from learning even simple tasks despite significant overparameterization. We then propose to compensate for communication delays by predicting future signals based on currently available ones. This conceptually straightforward approach, which we call prospective messaging (PM), uses only neuron-local information, and is flexible in terms of memory and computation requirements. We demonstrate that incorporating PM into delayed LE networks prevents reaction lags, and facilitates successful learning on Fourier synthesis and autoregressive video prediction tasks.
Online Continual Learning of Video Diffusion Models From a Single Video Stream
Jun 07, 2024Diffusion models have shown exceptional capabilities in generating realistic videos. Yet, their training has been predominantly confined to offline environments where models can repeatedly train on i.i.d. data to convergence. This work explores the feasibility of training diffusion models from a semantically continuous video stream, where correlated video frames sequentially arrive one at a time. To investigate this, we introduce two novel continual video generative modeling benchmarks, Lifelong Bouncing Balls and Windows 95 Maze Screensaver, each containing over a million video frames generated from navigating stationary environments. Surprisingly, our experiments show that diffusion models can be effectively trained online using experience replay, achieving performance comparable to models trained with i.i.d. samples given the same number of gradient steps.
TorchDriveEnv: A Reinforcement Learning Benchmark for Autonomous Driving with Reactive, Realistic, and Diverse Non-Playable Characters
May 07, 2024
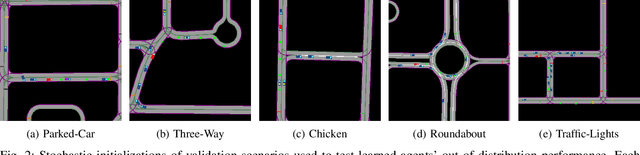
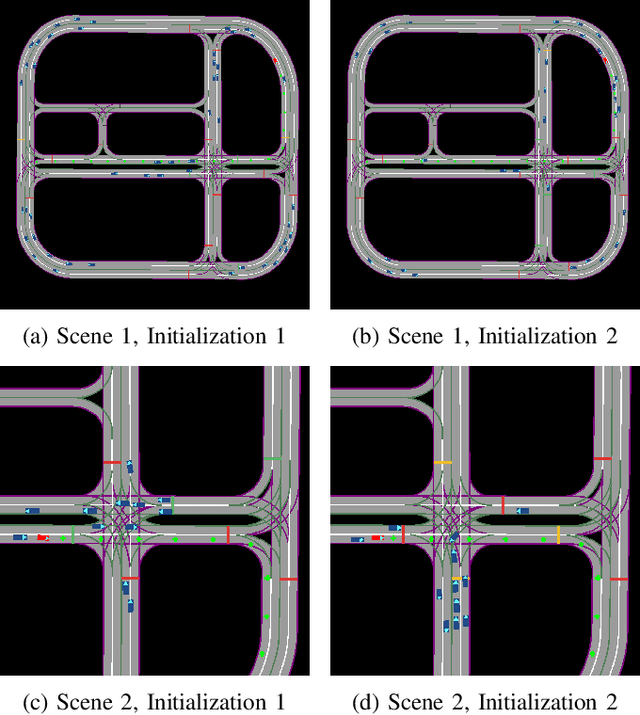
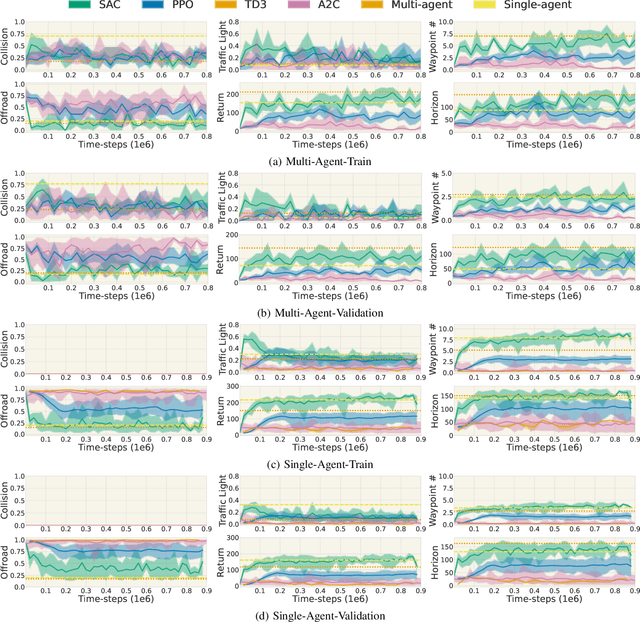
The training, testing, and deployment, of autonomous vehicles requires realistic and efficient simulators. Moreover, because of the high variability between different problems presented in different autonomous systems, these simulators need to be easy to use, and easy to modify. To address these problems we introduce TorchDriveSim and its benchmark extension TorchDriveEnv. TorchDriveEnv is a lightweight reinforcement learning benchmark programmed entirely in Python, which can be modified to test a number of different factors in learned vehicle behavior, including the effect of varying kinematic models, agent types, and traffic control patterns. Most importantly unlike many replay based simulation approaches, TorchDriveEnv is fully integrated with a state of the art behavioral simulation API. This allows users to train and evaluate driving models alongside data driven Non-Playable Characters (NPC) whose initializations and driving behavior are reactive, realistic, and diverse. We illustrate the efficiency and simplicity of TorchDriveEnv by evaluating common reinforcement learning baselines in both training and validation environments. Our experiments show that TorchDriveEnv is easy to use, but difficult to solve.
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Apr 30, 2024Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
All-in-one simulation-based inference
Apr 15, 2024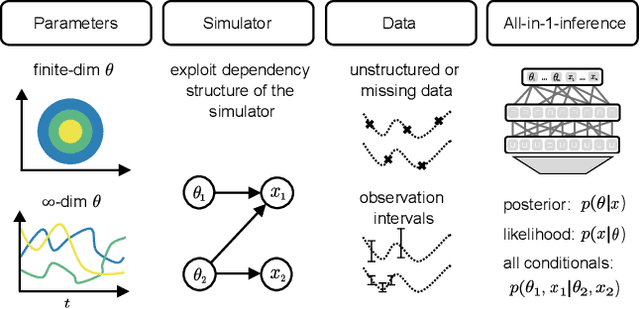
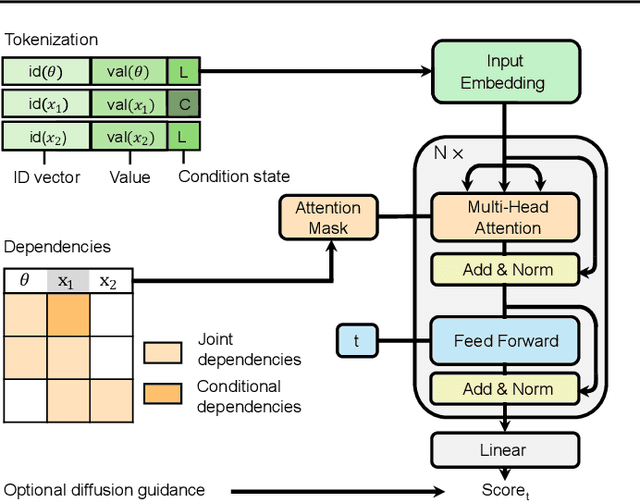
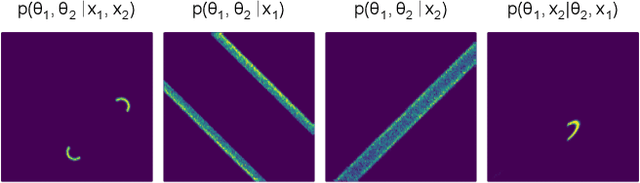
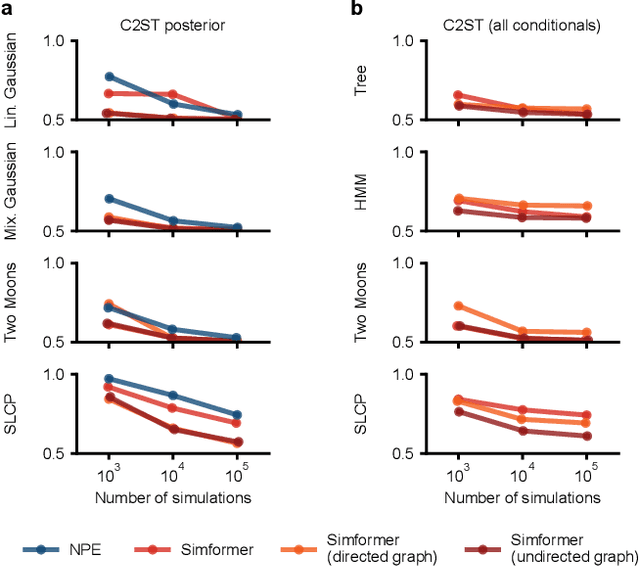
Amortized Bayesian inference trains neural networks to solve stochastic inference problems using model simulations, thereby making it possible to rapidly perform Bayesian inference for any newly observed data. However, current simulation-based amortized inference methods are simulation-hungry and inflexible: They require the specification of a fixed parametric prior, simulator, and inference tasks ahead of time. Here, we present a new amortized inference method -- the Simformer -- which overcomes these limitations. By training a probabilistic diffusion model with transformer architectures, the Simformer outperforms current state-of-the-art amortized inference approaches on benchmark tasks and is substantially more flexible: It can be applied to models with function-valued parameters, it can handle inference scenarios with missing or unstructured data, and it can sample arbitrary conditionals of the joint distribution of parameters and data, including both posterior and likelihood. We showcase the performance and flexibility of the Simformer on simulators from ecology, epidemiology, and neuroscience, and demonstrate that it opens up new possibilities and application domains for amortized Bayesian inference on simulation-based models.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.