 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRolling Ahead Diffusion for Traffic Scene Simulation
Feb 13, 2025



Realistic driving simulation requires that NPCs not only mimic natural driving behaviors but also react to the behavior of other simulated agents. Recent developments in diffusion-based scenario generation focus on creating diverse and realistic traffic scenarios by jointly modelling the motion of all the agents in the scene. However, these traffic scenarios do not react when the motion of agents deviates from their modelled trajectories. For example, the ego-agent can be controlled by a stand along motion planner. To produce reactive scenarios with joint scenario models, the model must regenerate the scenario at each timestep based on new observations in a Model Predictive Control (MPC) fashion. Although reactive, this method is time-consuming, as one complete possible future for all NPCs is generated per simulation step. Alternatively, one can utilize an autoregressive model (AR) to predict only the immediate next-step future for all NPCs. Although faster, this method lacks the capability for advanced planning. We present a rolling diffusion based traffic scene generation model which mixes the benefits of both methods by predicting the next step future and simultaneously predicting partially noised further future steps at the same time. We show that such model is efficient compared to diffusion model based AR, achieving a beneficial compromise between reactivity and computational efficiency.
Towards a Mechanistic Explanation of Diffusion Model Generalization
Nov 28, 2024We propose a mechanism for diffusion generalization based on local denoising operations. Through analysis of network and empirical denoisers, we identify local inductive biases in diffusion models. We demonstrate that local denoising operations can be used to approximate the optimal diffusion denoiser. Using a collection of patch-based, local empirical denoisers, we construct a denoiser which approximates the generalization behaviour of diffusion model denoisers over forward and reverse diffusion processes.
TorchDriveEnv: A Reinforcement Learning Benchmark for Autonomous Driving with Reactive, Realistic, and Diverse Non-Playable Characters
May 07, 2024
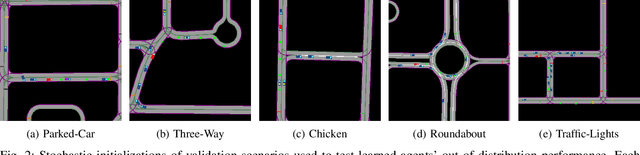
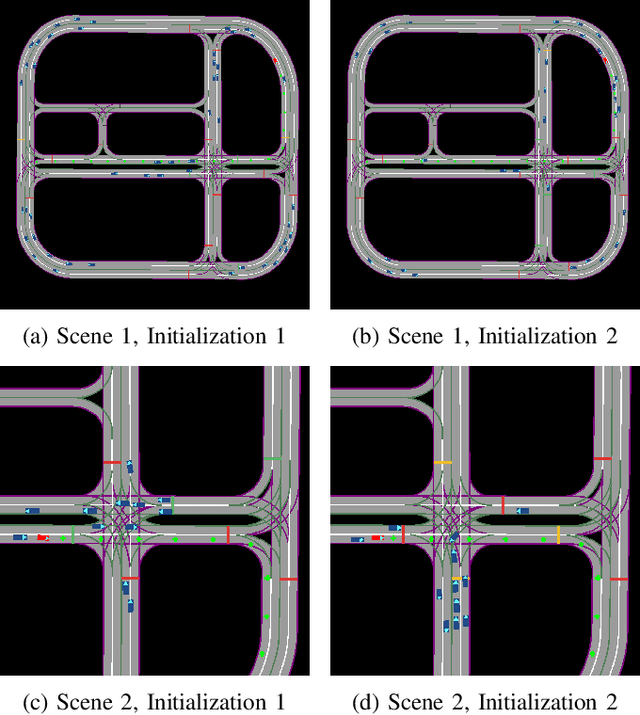
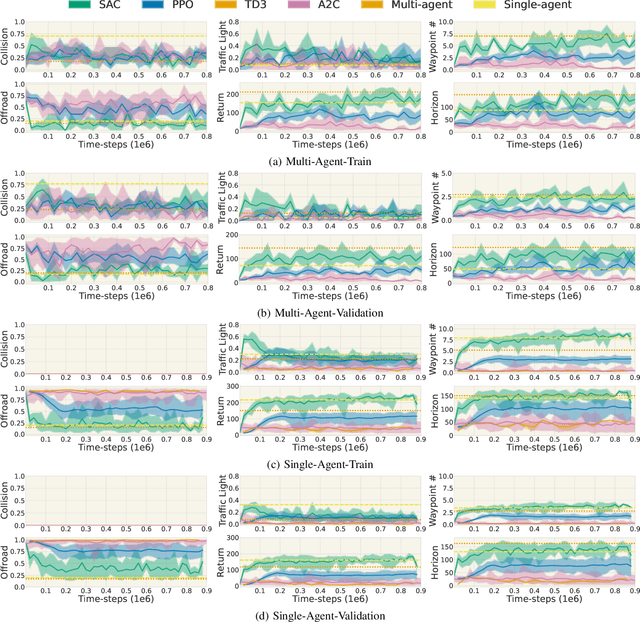
The training, testing, and deployment, of autonomous vehicles requires realistic and efficient simulators. Moreover, because of the high variability between different problems presented in different autonomous systems, these simulators need to be easy to use, and easy to modify. To address these problems we introduce TorchDriveSim and its benchmark extension TorchDriveEnv. TorchDriveEnv is a lightweight reinforcement learning benchmark programmed entirely in Python, which can be modified to test a number of different factors in learned vehicle behavior, including the effect of varying kinematic models, agent types, and traffic control patterns. Most importantly unlike many replay based simulation approaches, TorchDriveEnv is fully integrated with a state of the art behavioral simulation API. This allows users to train and evaluate driving models alongside data driven Non-Playable Characters (NPC) whose initializations and driving behavior are reactive, realistic, and diverse. We illustrate the efficiency and simplicity of TorchDriveEnv by evaluating common reinforcement learning baselines in both training and validation environments. Our experiments show that TorchDriveEnv is easy to use, but difficult to solve.
Semantically Consistent Video Inpainting with Conditional Diffusion Models
Apr 30, 2024Current state-of-the-art methods for video inpainting typically rely on optical flow or attention-based approaches to inpaint masked regions by propagating visual information across frames. While such approaches have led to significant progress on standard benchmarks, they struggle with tasks that require the synthesis of novel content that is not present in other frames. In this paper we reframe video inpainting as a conditional generative modeling problem and present a framework for solving such problems with conditional video diffusion models. We highlight the advantages of using a generative approach for this task, showing that our method is capable of generating diverse, high-quality inpaintings and synthesizing new content that is spatially, temporally, and semantically consistent with the provided context.
Nearest Neighbour Score Estimators for Diffusion Generative Models
Feb 12, 2024



Score function estimation is the cornerstone of both training and sampling from diffusion generative models. Despite this fact, the most commonly used estimators are either biased neural network approximations or high variance Monte Carlo estimators based on the conditional score. We introduce a novel nearest neighbour score function estimator which utilizes multiple samples from the training set to dramatically decrease estimator variance. We leverage our low variance estimator in two compelling applications. Training consistency models with our estimator, we report a significant increase in both convergence speed and sample quality. In diffusion models, we show that our estimator can replace a learned network for probability-flow ODE integration, opening promising new avenues of future research.
A Diffusion-Model of Joint Interactive Navigation
Sep 21, 2023



Simulation of autonomous vehicle systems requires that simulated traffic participants exhibit diverse and realistic behaviors. The use of prerecorded real-world traffic scenarios in simulation ensures realism but the rarity of safety critical events makes large scale collection of driving scenarios expensive. In this paper, we present DJINN - a diffusion based method of generating traffic scenarios. Our approach jointly diffuses the trajectories of all agents, conditioned on a flexible set of state observations from the past, present, or future. On popular trajectory forecasting datasets, we report state of the art performance on joint trajectory metrics. In addition, we demonstrate how DJINN flexibly enables direct test-time sampling from a variety of valuable conditional distributions including goal-based sampling, behavior-class sampling, and scenario editing.
Realistically distributing object placements in synthetic training data improves the performance of vision-based object detection models
May 24, 2023When training object detection models on synthetic data, it is important to make the distribution of synthetic data as close as possible to the distribution of real data. We investigate specifically the impact of object placement distribution, keeping all other aspects of synthetic data fixed. Our experiment, training a 3D vehicle detection model in CARLA and testing on KITTI, demonstrates a substantial improvement resulting from improving the object placement distribution.
Video Killed the HD-Map: Predicting Driving Behavior Directly From Drone Images
May 19, 2023The development of algorithms that learn behavioral driving models using human demonstrations has led to increasingly realistic simulations. In general, such models learn to jointly predict trajectories for all controlled agents by exploiting road context information such as drivable lanes obtained from manually annotated high-definition (HD) maps. Recent studies show that these models can greatly benefit from increasing the amount of human data available for training. However, the manual annotation of HD maps which is necessary for every new location puts a bottleneck on efficiently scaling up human traffic datasets. We propose a drone birdview image-based map (DBM) representation that requires minimal annotation and provides rich road context information. We evaluate multi-agent trajectory prediction using the DBM by incorporating it into a differentiable driving simulator as an image-texture-based differentiable rendering module. Our results demonstrate competitive multi-agent trajectory prediction performance when using our DBM representation as compared to models trained with rasterized HD maps.
Conditional Permutation Invariant Flows
Jun 17, 2022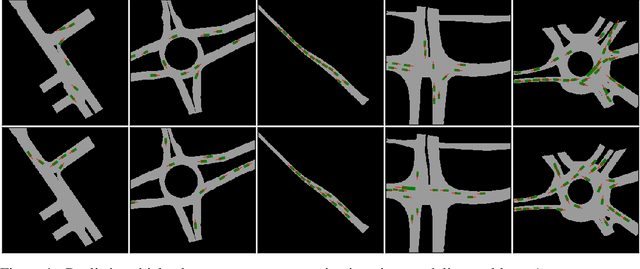
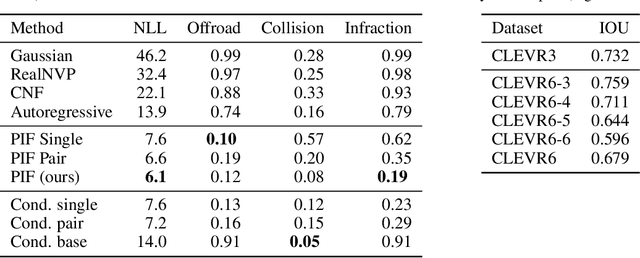
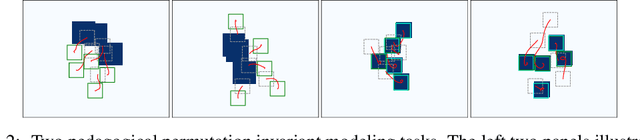
We present a novel, conditional generative probabilistic model of set-valued data with a tractable log density. This model is a continuous normalizing flow governed by permutation equivariant dynamics. These dynamics are driven by a learnable per-set-element term and pairwise interactions, both parametrized by deep neural networks. We illustrate the utility of this model via applications including (1) complex traffic scene generation conditioned on visually specified map information, and (2) object bounding box generation conditioned directly on images. We train our model by maximizing the expected likelihood of labeled conditional data under our flow, with the aid of a penalty that ensures the dynamics are smooth and hence efficiently solvable. Our method significantly outperforms non-permutation invariant baselines in terms of log likelihood and domain-specific metrics (offroad, collision, and combined infractions), yielding realistic samples that are difficult to distinguish from real data.
Critic Sequential Monte Carlo
May 30, 2022
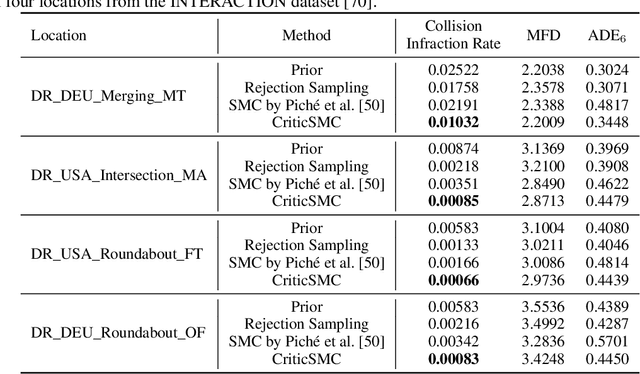
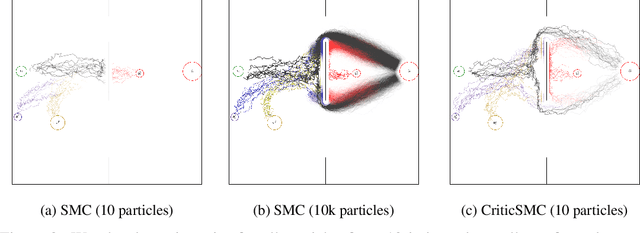
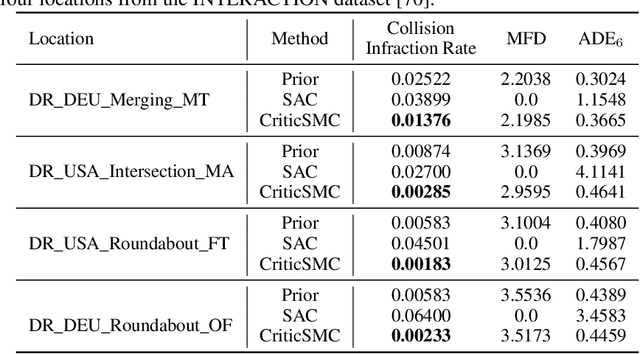
We introduce CriticSMC, a new algorithm for planning as inference built from a novel composition of sequential Monte Carlo with learned soft-Q function heuristic factors. This algorithm is structured so as to allow using large numbers of putative particles leading to efficient utilization of computational resource and effective discovery of high reward trajectories even in environments with difficult reward surfaces such as those arising from hard constraints. Relative to prior art our approach is notably still compatible with model-free reinforcement learning in the sense that the implicit policy we produce can be used at test time in the absence of a world model. Our experiments on self-driving car collision avoidance in simulation demonstrate improvements against baselines in terms of infraction minimization relative to computational effort while maintaining diversity and realism of found trajectories.